
昨天,我不是发了几个大模型参加数学高考的测试文章嘛。
没想到热度挺高,大家还挺关注的。

不过,很多评论区的小伙伴也说,根本看不出来区别。
因为缺了对AI难度最高的单选第6题,还有后面那些解答题。
那我想,不如再把模型补上,加上全缺失的智谱Z1、Kimi1.5、文心X1,(不带Claude 4,封号斗罗,我恨他),再做一个,完整的满血版的数学高考,让大家最直观的,感受一下这些模型的数学能力水平。
让大家看看,满分150分,每个模型到底多少分,哪个模型能拿高考数学状元。
因为要做解答题了,和选则填空不太一样,所以我还是单独定了一下规则,规则如下:
1. 数学大题往往都有两到三个小问,但是每个小问具体的赋分都不太一样,邀请了朋友(高中老师)来估摸一下每个小问的分数,如下,都取后者:

2. 高考大题往往会按照步骤给分,但是主要我也看不懂步骤(勿喷),所以这里我们不妨对大模型严格一点,按照结果是否正确来给分。
3. 每道题任然使用大模型跑3次,根据正确比例给分。
4. 依然所有的文本题,都使用LaTeX编辑器转成LaTeX文本格式,再扔给大模型进行回答。
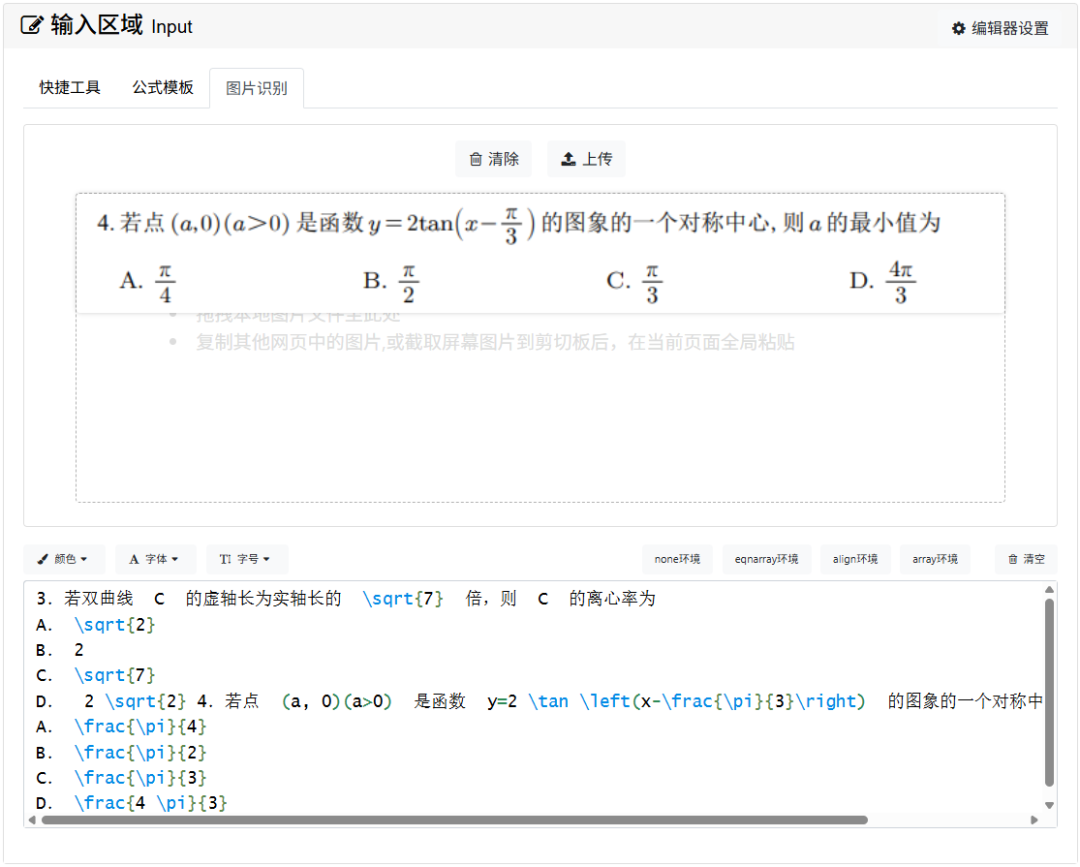
5. 带图片的多模态题也加入测试,直接截图进行作答,没有多模态或者推理时不能传图的模型,取其他所有多模态模型得分的平均分。
以上。
在几个朋友@东毅、@倒放、@云舒、@绛烨帮我kuku跑了好久之后,我们终于得出了结论。
这的,又一次干到了凌晨4点。

不过,最终的得分和结论,非常出人意料,也出乎我的意外。
先看对错。
对的全部都是✅,错的就是❌,如果是有部分对,就是⭕️,没有多模态的,就写没有多模态。
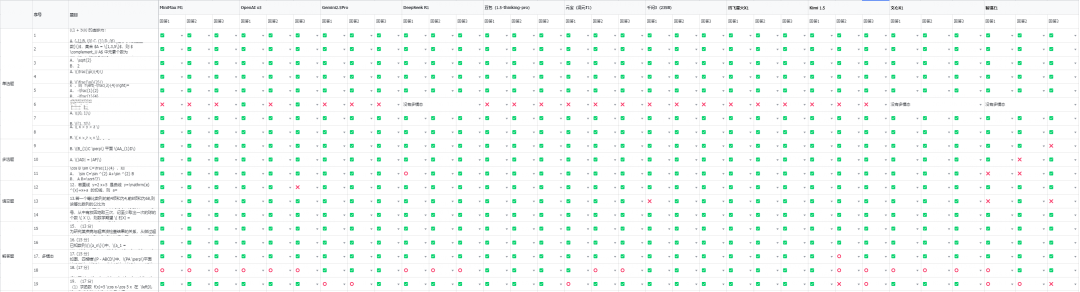
我说实话,这一片的绿,还是有点超出我的预期的,我本来以为,解答题会难住一堆大模型,没想到,几乎大部分都是对的,而单选题第6题,反而成了,所有大模型的噩梦。
涉及到图片的理解,对于广大高考学生,轻轻松松做一条辅助线就可以解决,但是所有的多模态大模型,几乎全军覆没,也就openai o3 在三次回答中,对了两次。
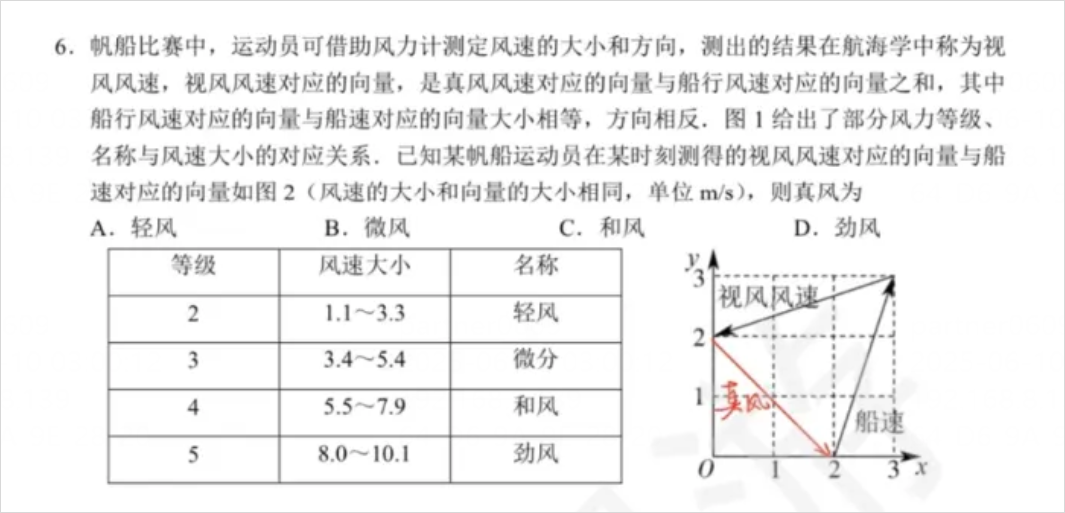
DeepSeek-R1-0528的表现不如其他的推理模型可能是因为他的推理思维链很长很长,而高考题并没有那么复杂,所以导致,想着想着,就想歪了。。。
真的发现,有时候想的短一点,正确性可能会更高。
所有的答案,都在这了,我们是结结实实的,把每个大模型、每道题,跑了3次。。。

下次一定要抽空做个脚本,这事用人干是真的顶不住= =
那最后,终于,要公布我们的测试最终得分了。。。
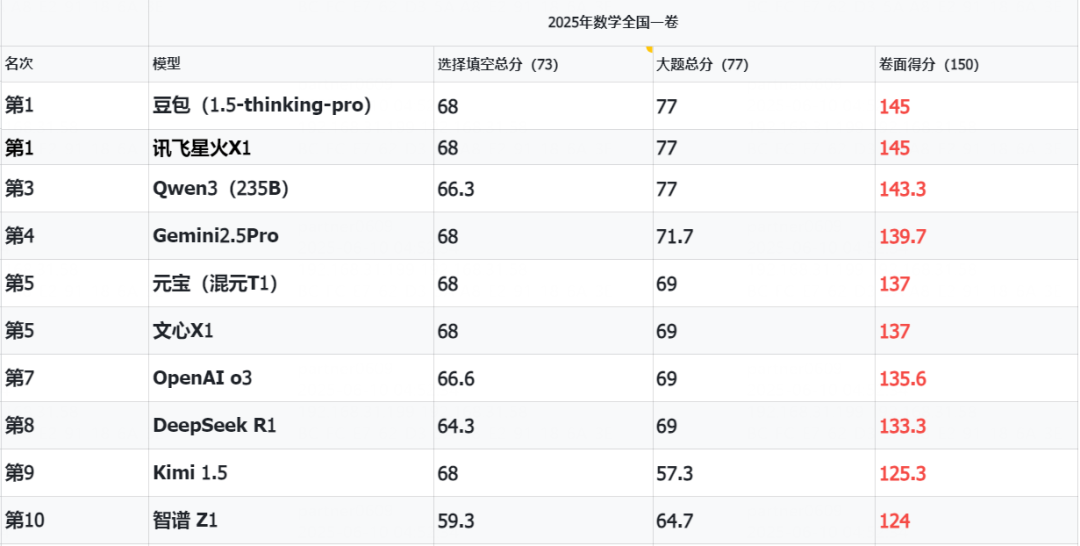
这个排名,真的让我有点意外。。。
这里我插一句,我对天发誓,这篇文章不是广告,我也和科大讯飞还有豆包没有任何利益关系,在测试过程中也没有任何弄虚作假或者不遵守规则。
但是实实在在的,就是这么发生了。
在我的测试中,讯飞星火和豆包除了第6题错,以其他题目全胜的姿态,145分的超高分,并列夺得了第一名。
而Qwen3,解答题全对,但是在填空题时,因为roll错了1次对了2次,产生了失误,丢了宝贵的1.7分,以143.3分,屈居第三。
Gemini2.5 pro,解答题拉了跨,139.7分,位列第四。
混元T1和文心x1,解答题失误稍微多了一些,比Gemini 2.5 pro多错了一点点,差了2.7分,并列屈居第五。
很有意思,太有意思了。
我其实很久没就没有测试测的这么开心过了。
2023年,我第一次测AI高考数学题的时候,那时候大家只有嘲讽。
强如大模型,不识一二三四五。
短短两年,对于高考来说,几乎都能轻松达到一个优秀学生的地步。
AI啊,进化还是太快了一点。
也许这就是我爱这份工作的原因吧。
它总能带给我一些未知,一些惊喜,还有一年抵十年的回忆。
所以,这场AI高考,就到这里画上句号吧。
天边泛起肚白。
新的一天。
又到来了。
(文:数字生命卡兹克)