
中兴通讯AIM团队 投稿
量子位 | 公众号 QbitAI
如何让AI代码补全更懂开发者?
中兴通讯团队提出了两个新的评测指标,以及一套仓库级代码语料处理框架。
按照团队的说法,这套方法论不仅为评测代码大模型提供了新视角,也为提升模型在真实工业场景中的代码补全性能开辟了新路径。

目前在编写代码时,智能补全工具如GitHub Copilot和Cursor等,极大地提升了程序员的开发效率。
然而这些AI工具给出的建议经常“差了点火候”,不完全符合用户预期。
对此团队认为,这实际上暴露了当前代码大模型使用中的两个关键痛点:
-
AI的“我觉得好” vs 用户“真的好用”:目前评价AI代码补全效果的指标,和开发者实际使用时的真实感受、采纳意愿,往往存在一条“隐形鸿沟”。
-
AI的“局部视野”:多数模型在学习代码时,更侧重于理解一小段上下文的序列关系,对于整个代码仓库中,跨越不同文件、不同模块的复杂结构和深层语义依赖,常常“力不从心”,导致补全建议的质量和实用性大打折扣。
这些问题,无疑限制了代码大模型在复杂工业环境,尤其是在ZTE-Code-Copilot(中兴通讯自研的通信领域代码开发助手)这类专业场景中的应用潜力。
那么,如何使AI的补全建议更符合开发者的需求呢?

两个新指标+一套新框架
事实上,开发者们苦恼于AI的“自说自话”久矣。团队认为要解决这个问题,必须回答两个灵魂拷问:
① 何谓高质量的代码补全,能够让开发者愉快地按“Tab”键采纳?
② 如何教会AI“高瞻远瞩”,理解整个代码仓库的复杂结构和内在逻辑,而不是只盯着眼前的一亩三分地?
针对上述挑战,团队祭出了两大“法宝”:
更贴近用户真实感知的评估“新标尺”:LCP与ROUGE-LCP指标设计
团队发现,开发者在用“随手补全”功能(指代码补全中的单行补全任务和行内补全任务)时,下意识地会从左到右看AI的建议,特别关注建议的开头部分是不是对的。
就是说,只要开头那段对了,哪怕后面有点小问题,也很可能就接受了,再自己改改。
基于这一核心洞察,团队提出了两个与用户感知更契合的新评估指标:
(1)最长公共前缀长度(LCP, Longest Common Prefix)
定义:LCP(S, R)指模型输出序列 S=s1, s2, …, sT与参考序列(即用户期望的代码)R=r1, r2, …, rT从起始位置开始连续匹配的最大字符数。
核心价值:LCP强调从第一个字符开始的连续匹配性,这恰恰是交互式代码补全场景中用户最为关注的特性。它比那些允许不连续匹配的指标(如基于LCS的指标)更能反映用户在实际操作中的体验。
(2)ROUGE-LCP
定义:在LCP基础上,借鉴ROUGE-L的归一化思想,提出ROUGE-LCP: ROUGE-LCP(S,R)=LCP(S,R) /∣R∣。 其中∣R∣是参考序列的长度。
核心价值:通过除以参考序列长度,ROUGE-LCP实现了对不同长度补全样本的公平比较,同样能有效反映模型输出的实用性。
赋予AI“全局视野”的“导航系统”:SPSR-Graph仓库级代码语料处理框架
为了让大模型能真正理解复杂代码仓库的结构和语义,而不只是“管中窥豹”,团队设计了一套仓库级代码语料处理框架。
其核心是构建和利用一种特殊的代码知识图谱——SPSR-Graph(Structure-Preserving and Semantically-Reordered Code Graph)。
目标是,通过显式建模代码的结构信息和跨文件的依赖关系,让预训练语料本身就蕴含更丰富的结构化知识,从而提升模型对整个代码仓库的理解深度。
下图为SPSR-Graph框架图,展示了从原始代码到高质量SPSR-Graph训练语料的完整流程。
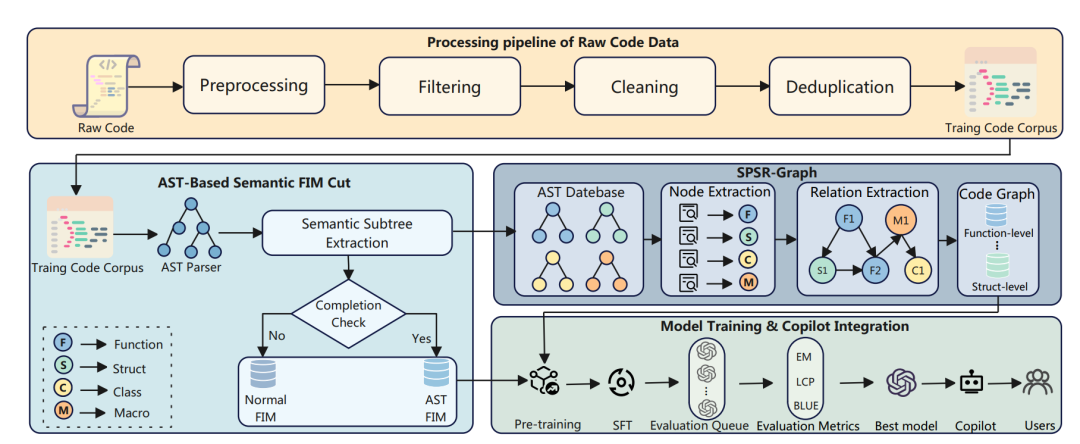
图中核心组件解读:
1、语料预处理:对海量原始代码进行严格的数据过滤、清洗和去重,确保输入“干净”。
2、AST结构切割:利用AST将代码分解为函数、类等具有完整语义的结构化单元。
3、结构感知图谱构建与样本生成:以上述语义单元为节点,以它们之间的调用、依赖关系为边,构建代码知识图谱。然后通过遍历图中的路径,将路径上的代码片段(包含必要的结构注释)拼接起来,形成富含全局结构信息的训练样本。
主要步骤如下:
其一,基于AST的语法感知语义单元抽取 (Syntax-Aware Semantic Unit Extraction via AST)。
团队首先使用AST(抽象语法树)解析工具(如Tree-sitter)将源代码切割成具备语义封闭性的基本单元,例如函数体、类定义、条件分支等。
这确保了每个单元在结构上的完整性和上下文的连续性,避免了传统基于Token的随机或滑窗方法可能带来的语义割裂。
其二,SPSR-Graph构建——结构保持与依赖排序。
-
语义单元抽取与图初始化:将从代码库中抽取出的所有顶层语义单元(如函数v𝑖)作为图Γ=(V,ϵ)中的节点V。这些单元具备语义完备性。
-
关系抽取与图构建:分析这些语义单元之间的依赖关系,如函数调用、成员引用、类型依赖等,作为图中的有向边ϵ⊆V×V。图的边可以标注类型,节点可以增强属性(如定义位置、模块归属)以承载更丰富的语义。
-
图结构遍历与训练样本构建: 在构建好的有向图Γ上,采用有向广度优先搜索(BFS)等策略,找出所有深度不超过预设值D的语义路径。
每一条路径pk都被映射为一个训练样本:Sample(pk)=νk1⊕νk2⊕…⊕νkm,其中⊕代表结构感知的拼接操作。
在拼接过程中,会插入文件路径等结构化注释信息,以增强模型对跨文件结构的建模能力。
整个过程不仅保留了代码的语法结构完整性和上下文一致性,更关键的是,它在调用路径的维度上对语料进行了重排序,使模型在训练时能显式地学习和建模跨函数、跨模块的结构性依赖。
通过这套“组合拳”,团队期望AI模型能练就“火眼金睛”,洞察代码的深层奥秘。
实验效果
接下来,团队进行了一系列实验来验证新指标的“含金量”和新方法的“战斗力”。
LCP与ROUGE-LCP:真的和开发者“心有灵犀”吗?
团队收集了ZTE-Code-Copilot在2025年3月3日至4月24日期间,超过10000条真实用户的“随手补全”数据记录进行分析。
以下为LCP分布及其与采纳次数和采纳率的关系图(即LCP的“用户缘”):
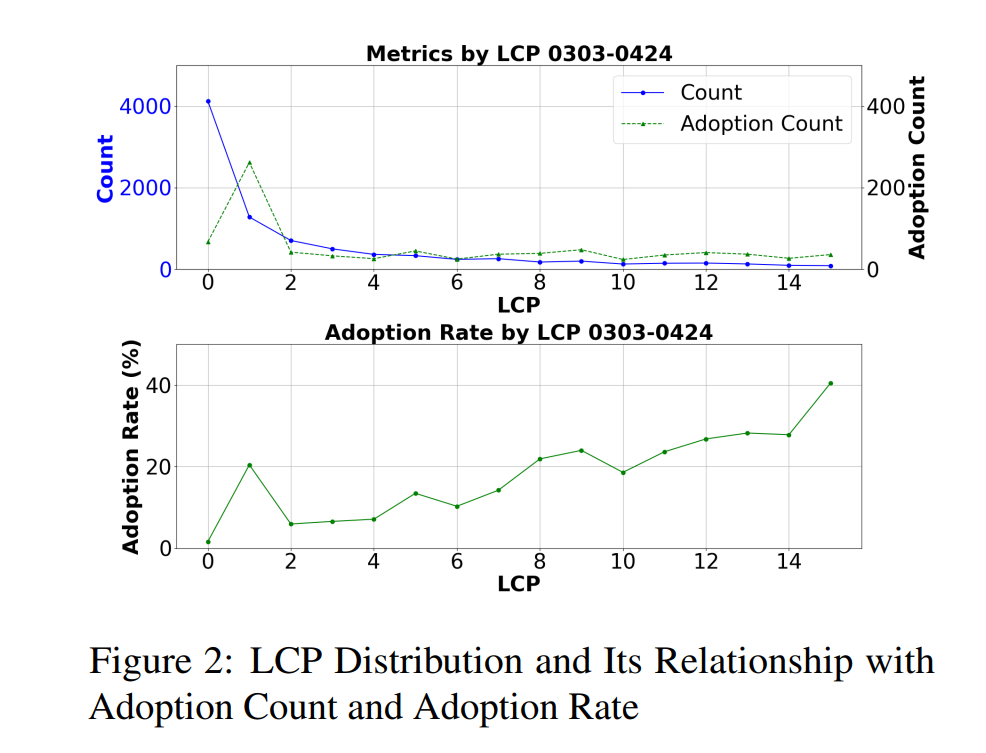
团队发现LCP的分布呈现明显的长尾特性,与理论推导高度吻合。
最亮眼的是,LCP值与用户实际“采纳率”之间存在显著的正相关。
表1显示,皮尔逊相关系数r值在不同时间段均高于0.69,最高达到0.91,且P值均小于0.05。
简单说,LCP越高,用户越愿意用AI的建议。在LCP=1时,会出现一个明显的尖峰,这是因为当AI给出句尾需要补全标点符号(,.;)的建议时,人们会有更高概率采纳。

ROUGE-LCP分布及其与采纳次数和采纳率的关系图(即ROUGE-LCP的“洞察力”)如下:
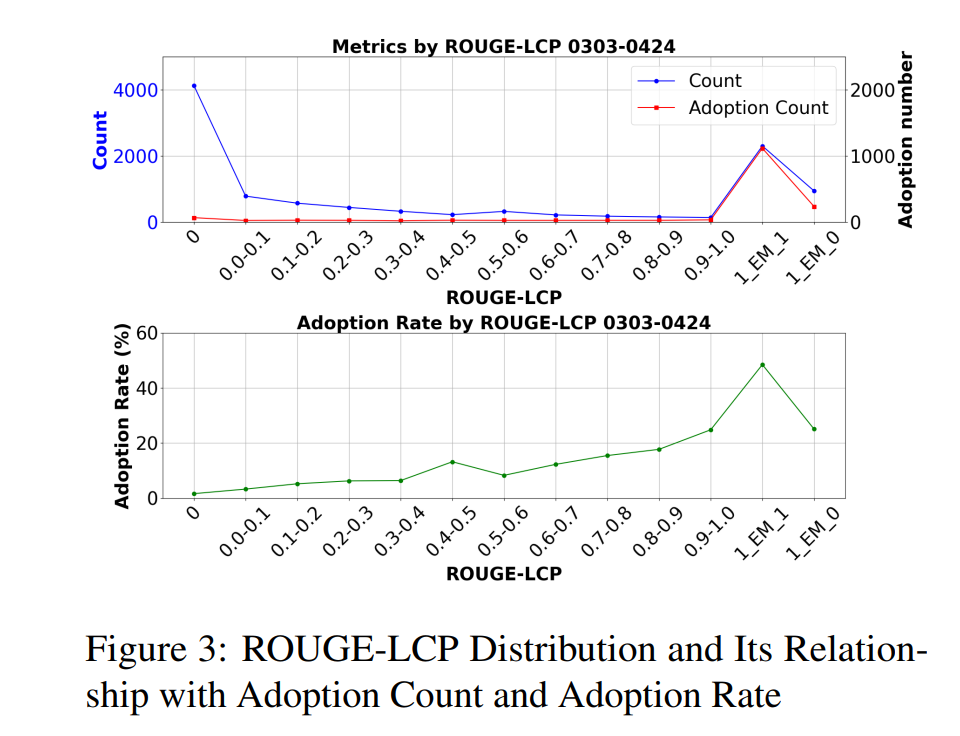
团队表示,ROUGE-LCP的分布也符合其混合模型预期。随着ROUGE-LCP值增加,用户采纳率整体上升,在AI建议与用户想法完全一致(EM=1)时达到顶峰。
新老指标大PK
团队计算了LCP、ROUGE-LCP,以及传统的评估指标——EM(完全匹配)、LCS(最长公共子序列)和ROUGE-L的每日平均值,并同时统计了采纳率的每日平均值。
通过将时间窗口扩展至两个月,进一步分析了LCP等评估指标与采纳率之间的相关性。
原论文表2清晰显示,在与用户采纳率的相关性方面,LCP和ROUGE-LCP明显胜出,r值普遍更高,LCP与用户采纳率的相关性甚至超过了0.7,远好于传统的评测指标EM。
下表为评估指标(LCS、LCP、ROUGE-L、ROUGE-LCP、EM)与用户采纳率之间的皮尔逊相关性分析:
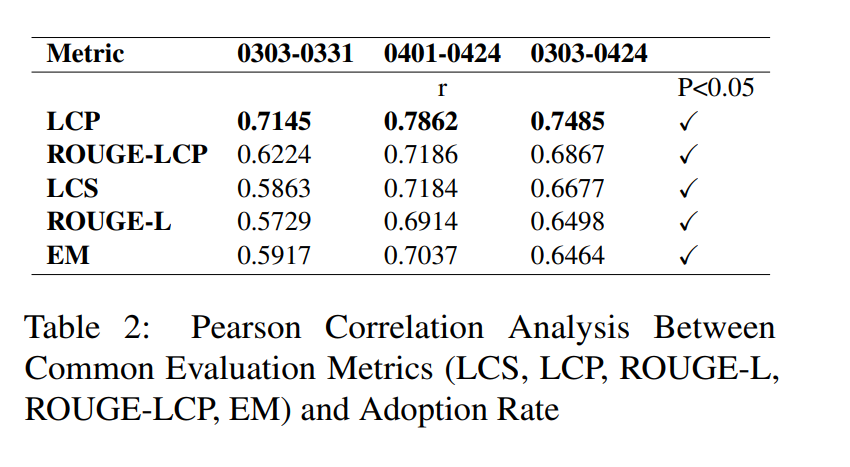
但也发现了一个现象,ROUGE-LCP与采纳率的相关性要低于LCP与采纳率的相关性。
这两个现象说明,用户在是否接受AI提供的代码补全建议这个点上,与AI提供的答案从首字母起正确的字符的绝对数量相关,而不是相对占比,这反应了用户编辑有一定的随意性。
并且,用户并不完全追求AI提供的答案和预期完全一致,只需要AI在符合用户编辑习惯的基础上,提供尽可能正确的答案。
这充分证明,新指标更能捕捉到用户真正的采纳行为和使用意图。
SPSR-Graph:“武装”后的AI有多强?
团队选用Qwen2.5-7B-Coder作为基础模型,使用了约0.6B token的通信领域C/C++代码语料进行预训练,并辅以约6万条精调语料。
(1)“三级跳”式性能提升
然后,团队比较了不同预训练语料策略的效果:基础的Pipeline处理→ 增加AST语义切割 → 构建函数级代码图谱(KGF) → 进一步引入结构体级图谱(KGFS)。
下表为不同预训练语料策略在随手补全任务中的性能比较:
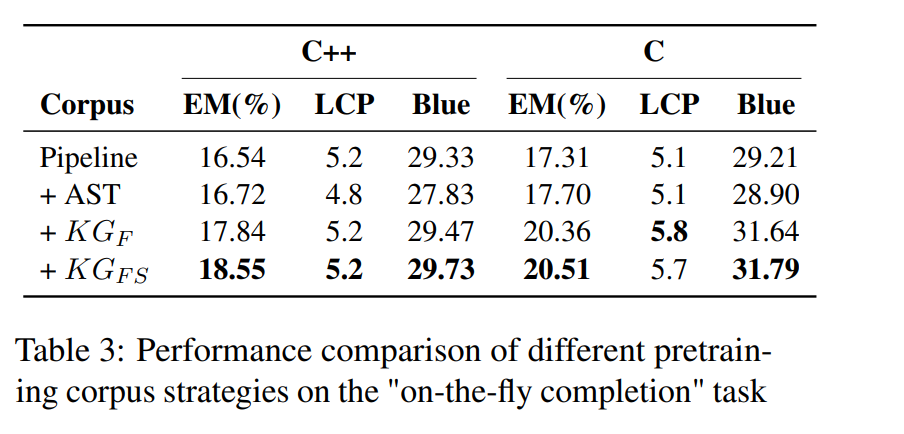
结果显示,采用KGFS策略训练的模型,在C++和C语言上的EM(精确匹配率)、LCP和BLEU等多个核心指标上均取得了最佳性能。
尤其在C语言上,相较于仅使用AST切割的策略,KGF使EM提升了2.66%,BLEU提升了2.74%,证明SPSR-Graph带来的全局上下文理解能力效果显著。
(2)知识图谱的“最佳有效半径”
下图为代码知识图谱广度对代码补全性能的影响:
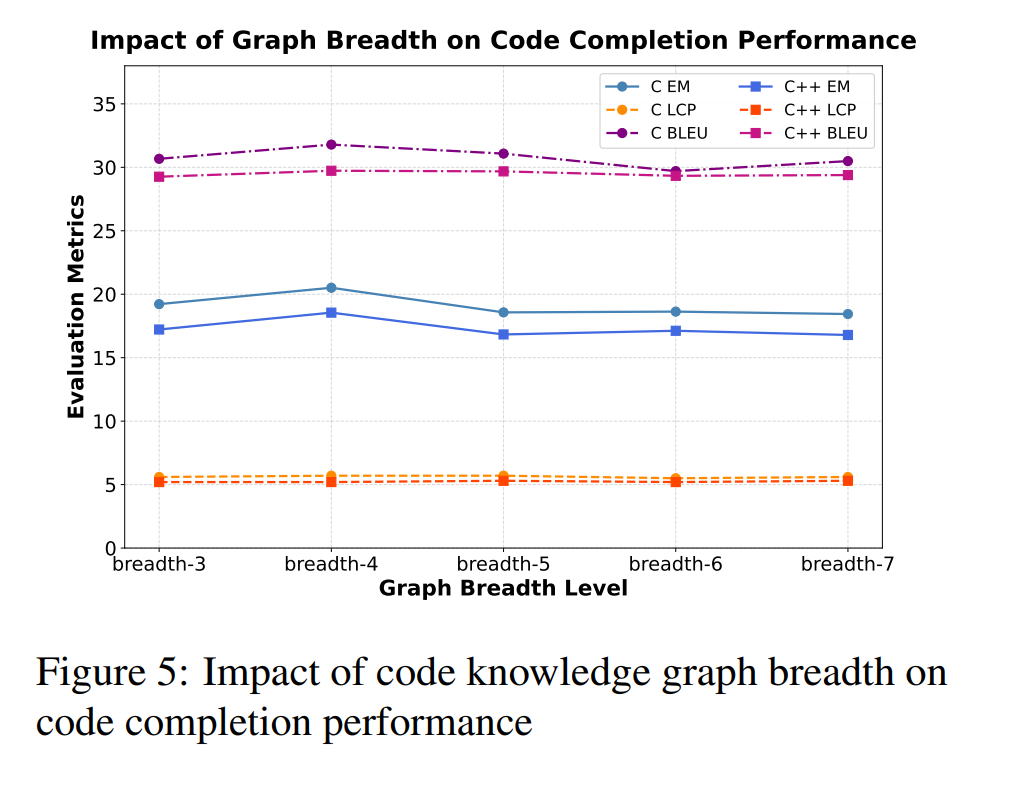
团队还探索了SPSR-Graph的“遍历广度”(即一个代码节点在图中连接多少“邻居”)对模型性能的影响。
实验发现,当广度k=4时,模型表现最佳。广度过小,信息量不足;广度过大,则可能引入过多无关噪声,反而导致性能下降。
未来展望
通过本次研究,团队系统地探讨并实践了如何让AI代码补全更懂开发者:
一是提出了更精准的“尺子”:LCP和ROUGE-LCP这两个新评测指标,能够更真实地反映用户对“随手补全”建议的采纳意愿,为模型优化指明了更靠谱的方向。
二是打造了更智能的“教材”:基于SPSR-Graph的仓库级代码语料处理框架,通过保留代码结构、重排语义依赖,显著增强了模型对复杂代码结构和跨文件依赖的感知与利用能力。
本文作者来自中兴通讯AIM团队。团队致力于推动通信领域和垂直领域的智能化发展,研究范围包括星云通信领域大模型,星云Agent框架(NAE),以及星云精调流水线等。
未来,团队表示将继续深化对LCP和ROUGE-LCP指标在更多代码生成任务、不同类型模型上的适配性研究。
同时,SPSR-Graph方法也将进一步探索与强化学习等技术的结合,以挖掘模型更深层次的推理能力,并尝试扩展到更复杂的软件工程领域。
论文链接:https://arxiv.org/pdf/2505.13073
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)