
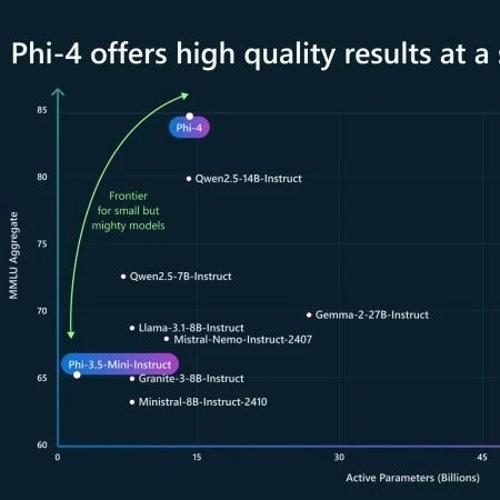
 尽管与phi-3架构相比变化极小,但由于数据的改进、训练课程的优化以及后训练方案的创新,phi-4相对于其规模实现了强大的性能——特别是在以推理为重点的基准测试上。
尽管与phi-3架构相比变化极小,但由于数据的改进、训练课程的优化以及后训练方案的创新,phi-4相对于其规模实现了强大的性能——特别是在以推理为重点的基准测试上。

-
phi-4的核心支柱:
-
合成数据用于预训练和中期训练,以提高模型的推理和问题解决能力。
-
对有机数据(如网页内容、书籍和代码库)进行策展和过滤,以提取高质量的数据种子。
-
后训练阶段通过新的SFT(监督式微调)数据集和直接偏好优化(DPO)技术来提升模型性能。
-
数据方法:详细介绍了合成数据的目的和生成方法,包括种子策展、重写和增强、自我修订、指令反转以及代码和其他科学数据的验证。
-
预训练细节:描述了phi-4模型的架构和预训练过程,包括数据组成和中期训练的细节。
-
后训练:介绍了如何通过SFT和DPO将预训练模型转化为用户可以安全交互的AI助手,包括关键令牌搜索(PTS)技术来生成DPO数据。
-
合成数据生成的原则:
-
多样性:数据应全面覆盖每个领域内的子主题和技能。
-
细微差别和复杂性:有效的训练需要反映领域复杂性和丰富性的细微、非平凡的例子。
-
准确性:代码应能正确执行,证明应有效,解释应符合已建立的知识等。
-
思维链:数据应鼓励系统性推理,教会模型以逐步的方式解决问题。
-
预训练和中期训练的合成数据:
-
创建了50种不同类型的合成数据集,涵盖了广泛的主题、技能和互动性质,累积约4000亿未加权token。
-
使用了多种新技术生成phi-4的合成数据集,包括种子策展、重写和增强、自我修订、指令反转以及代码和其他任务的验证。
-
有机数据的策展和过滤:
-
收集了数以百万计的高质量有机问题和解决方案,这些数据来自公开网站、现有数据集和外部数据集。
-
针对高质量网络数据进行了专门的采集,优先选择推理密集和细腻的材料,如学术论文、教育论坛和编程教程。
-
后训练数据集:
-
后训练数据包括监督式微调(SFT)数据集和直接偏好优化(DPO)数据对。
-
SFT数据集使用来自多个领域的高质量数据生成,DPO数据对则基于拒绝采样和LLM评估生成。
https://arxiv.org/pdf/2412.08905
(文:PaperAgent)