

闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
图像生成界的“大魔王”Midjourney也来卷视频生成了?!

上面展示的就是一个视频效果。
可以看到跑步动作和人物、空间转换非常丝滑。
下面这个挖蛋糕的场景不仅逼真,勺子上还有倒影,非常细节了。

一石激起千层浪,消息一出,Reddit点赞量直达2.5k。
还引发了网友们激烈讨论。
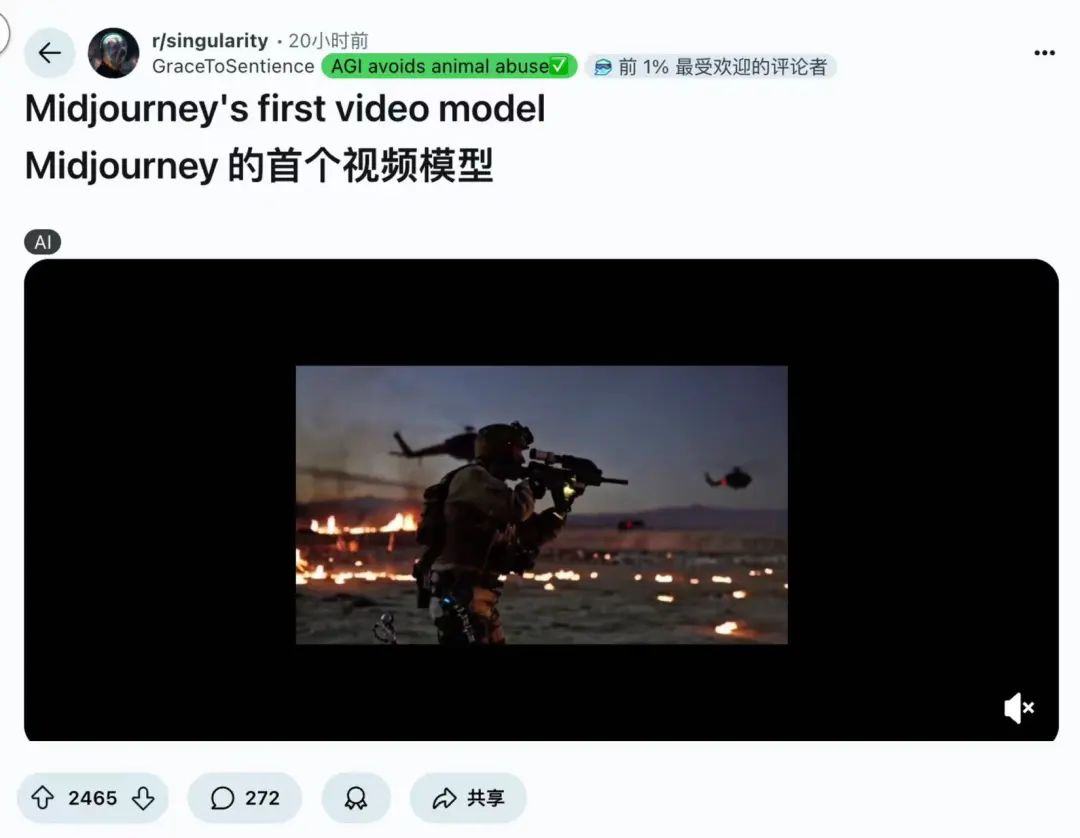
有人说“这是第一次以为是人工拍摄的视频”、“几乎和现实无法区分”。


不仅视频模型表现良好,Midjourney的图像模型V7也在不断更新中。
不仅效果惊人,价格还由你来定
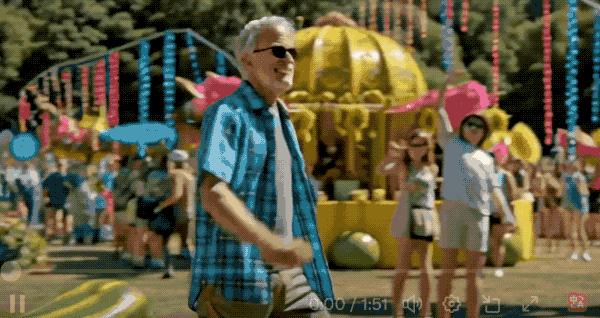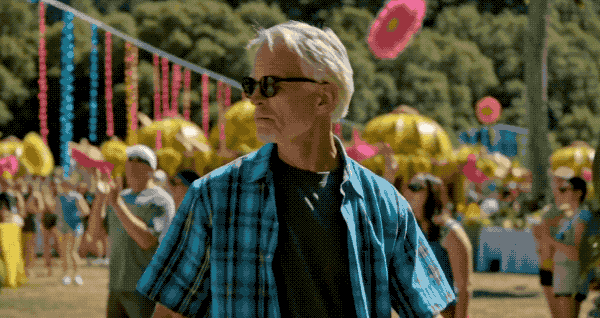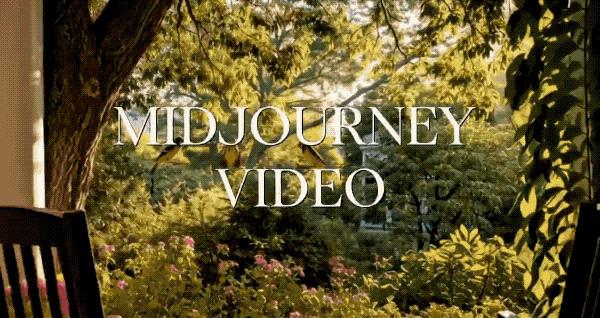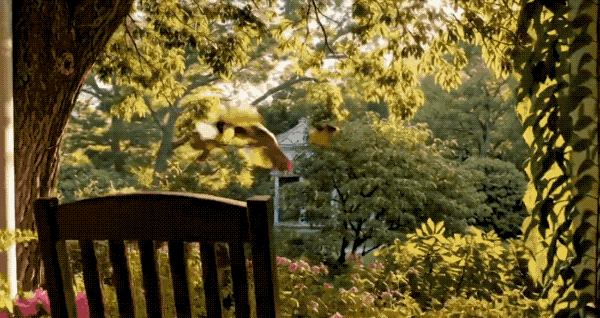
再来看看更多的效果演示。
多人物动作和视角切换也非常丝滑。

小猫的动作和人手的动作都很有物理真实感。

小狗滑滑板来了~

汽车漂移也不在话下。

小猫美甲确实很精细,但更细节的是手部的纹路,手指上居然还有指纹(虽然有一部分指纹是缺失的)。

不过,也正如上面那位网友所说,有些地方还是不太合理的。
比如,这个叠毯子的场景中,虽然考虑到了手部发力扯出的褶皱,给人一定的物理真实感,但是后面像是毯子自己缩回去了……

还有这个,怎么感觉是爬了一段无意义的楼梯,而且女人右手上的花突然飘到了左手上,就为了右手能搭上楼梯。

总体看下来,Midjourney的这个视频生成模型在物理真实感、纹路细节、动作平滑程度上表现还是很不错的。
但是,如果看过之前Veo 3的效果,你会不会觉得Midjourney这些视频哪里有点问题——
没有音频功能。
是的,网友们也发现了这一点。

同样是拉小提琴,Midjourney这边只有后期加的音乐。
而Veo 3却可以生成小提琴的琴声。
于是,就有人提出质疑了,Midjourney这时候入局是不是有点晚了?

不过,就在前两天,Midjourney公开进行了公司会议,展示了部分视频生成的演示,并且提到了“动画化图片”,似乎是与其他视频生成模型相区别的功能。
实际上,相比于写实风格,动画风才是Midjourney更擅长的。
目前,Midjourney的视频模型还没有正式发布,正在做最后的完善。
团队呼吁大家积极参加视频评分,以帮助模型学习人们在视频中喜欢看到的动作和构图组合。
并且,Midjourney还非常有诚意地表示,希望大家给些建议,让定价能够满足每个人的需求。
不得不说,这波操作也是非常有诚意了。

Midjourney V7支持语音生图
除了视频模型,生图模型Midjourney V7也在不断更新中。
从今年3月份开始,Midjourney不断呼吁用户积极参加图像评分,用来对V7进行最终完善。
在4月份, Midjourney发布了V7 alpha。
有Relax和Turbo模式两个版本。
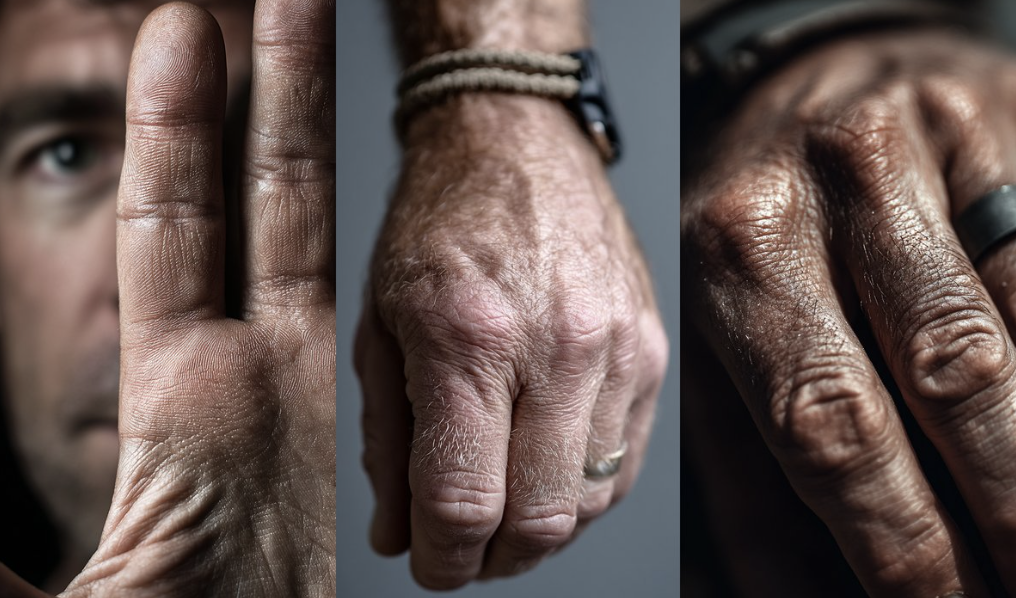
下面是一些效果图,可以看到,V7生成的手部纹理是非常逼真的。

V7的旗舰功能是“草稿模式”。
在使用这个功能时,提示栏将更改为“对话模式”。
比如,告诉它用猫换隼或让它变成夜晚,它会自动操作提示并开始一项新工作。
点击“草稿模式”然后点击麦克风按钮以启用“语音模式”——你可以大声思考,让图像如梦境一样在生成区流动。
也就是说,通过说话就能生成图像,并且可以生成多图任君选择~

草稿模式让生成成本减半,渲染图像速度提升了10倍。
目前,团队也已经将“草稿模式”与“对话模式“区分开,你可以自由选择如何单独或者组合使用这些功能。
团队还推出V7快速模式,也就是更新了加速的功能。
这意味着在快速模式下模型优化需40秒,在Turbo模式下将仅耗时18秒。
经过团队不断努力,目前,Midjourney V7图像生成速度提升了约40%。
快速模式作业渲染时间从36秒减少到22秒。
Turbo作业渲染时间从13秒减少到9秒。
图像模型V7不断更新,还即将推出视频模型,Midjourney不愧是卷王!
(文:量子位)