

在AI驱动的数据时代,高效、灵活的网络爬虫和数据抓取工具成为开发者和企业的刚需。
以往我们所经常使用的爬虫工具(如Scrapy、Selenium),要么静态解析慢,要么动态渲染资源占用高、爬取难度过于复杂。
今天为大家介绍一款刚开源不久的轻量高性能爬虫工具:AnyCrawl。

它集成Cheerio、Playwright和Puppeteer三种引擎,支持静态页面快速解析、JavaScript渲染内容抓取以及Google/Bing等搜索引擎结果页面(SERP)批量提取。
提供多线程多进程架构、代理支持、LLM优化输出(Markdown/JSON)。
不用繁琐配置,也不用在多个爬虫库之间反复调试,一站式搞定所有类型网页抓取需求!
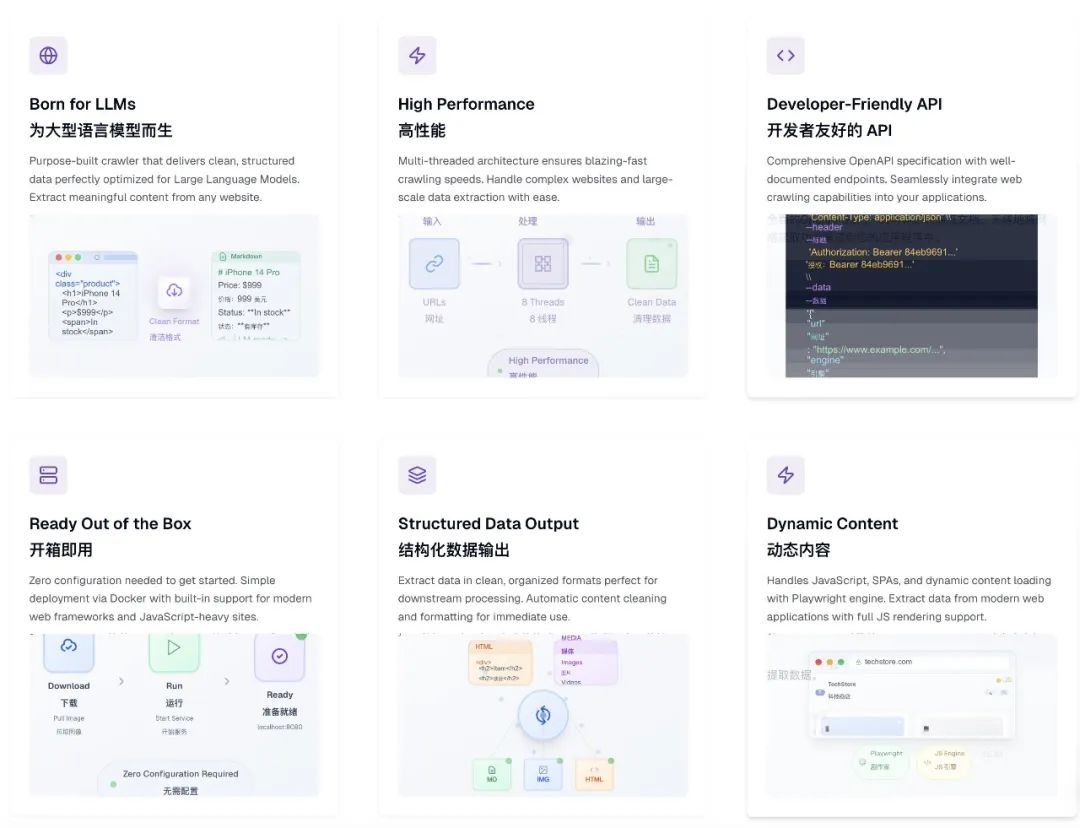
主要功能
-
• 多引擎支持:Cheerio(静态HTML解析,超快)、Playwright/Puppeteer(动态JS渲染,精准),自由切换。 -
• SERP爬虫:批量提取Google搜索引擎结果,结构化输出JSON/Markdown。 -
• 整站爬取:智能遍历网站链接,支持深度优先或广度优先策略。 -
• 高性能架构:多线程/多进程并发,批量任务处理效率高。 -
• 代理支持:内置HTTP/SOCKS代理,绕过反爬限制,优化大规模抓取。 -
• LLM优化:输出Markdown、JSON、HTML,适配RAG和AI训练。 -
• Docker部署:一键部署,跨平台兼容Windows、macOS、Linux。
快速使用
AnyCrawl支持 Docker 一键部署,避免繁琐的命令行操作。
首先在你所在的系统上安装 Docker 和 Docker Compose。
# MacOS
brew install docker docker-compose
# 或者下载 Docker Desktop
# https://www.docker.com/products/docker-desktop然后需要克隆项目
git clone https://github.com/any4ai/anycrawl.git
cd anycrawl通过Docker启动服务
# Build and start all services
docker compose up --build
# Or run in background
docker compose up --build -d验证服务是否部署成功
# Check service status
docker compose ps
# Test if API is running properly
curl http://localhost:8080/health创建环境配置文件
cp .env.example .env
# 示例配置
# Basic configuration
NODE_ENV=production
ANYCRAWL_API_PORT=8080
# Scraping configuration
ANYCRAWL_HEADLESS=true
ANYCRAWL_PROXY_URL=
ANYCRAWL_IGNORE_SSL_ERROR=true
# Database configuration
ANYCRAWL_API_DB_TYPE=sqlite
ANYCRAWL_API_DB_CONNECTION=/usr/src/app/db/database.db
# Redis configuration
ANYCRAWL_REDIS_URL=redis://redis:6379
# Authentication configuration
ANYCRAWL_API_AUTH_ENABLED=false详细的配置参数说明,可以通过文档指南进行学习了解。
官方说明文档:https://docs.anycrawl.dev/en/general
网络爬取-基本用法
curl -X POST http://localhost:8080/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_ANYCRAWL_API_KEY' \
-d '{
"url": "https://example.com",
"engine": "cheerio"
}'搜索引擎结果(SERP)-基本用法
curl -X POST http://localhost:8080/v1/search \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_ANYCRAWL_API_KEY' \
-d '{
"query": "AnyCrawl",
"limit": 10,
"engine": "google",
"lang": "all"
}'应用场景
-
• SERP抓取:批量采集Google搜索结果,市场研究神器。 -
• 电商分析:爬取产品价格/评论,输出JSON喂LLM。 -
• 学术研究:整站爬取论文/博客,Markdown适配RAG。 -
• 实时监控:动态页面抓取,跟踪新闻或价格变化。 -
• AI数据管道:清洗数据为LLM-ready格式,省去预处理。
写在最后
网络爬虫的痛点常让人抓狂:静态获取慢、动态加载卡、SERP页面复杂。
而 AnyCrawl 的出现,就像给爬虫装上了多引擎动车。它集成Cheerio/Playwright/Puppeteer,支持SERP、整站和动态网页抓取,输出LLM友好的Markdown/JSON。
更重要的是,它开源免费,Docker即可一键部署,跨平台无忧。
对于开发者而言更可快速上手,应用于AI训练、市场研究和SEO。
如果你正在寻找一款:高性能、易用、动态页面友好、SERP可批量爬取、LLM 语料格式即插即用的现代爬虫工具,那 AnyCrawl 是一个不错的选择!
GitHub 项目地址:https://github.com/any4ai/anycrawl

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)