



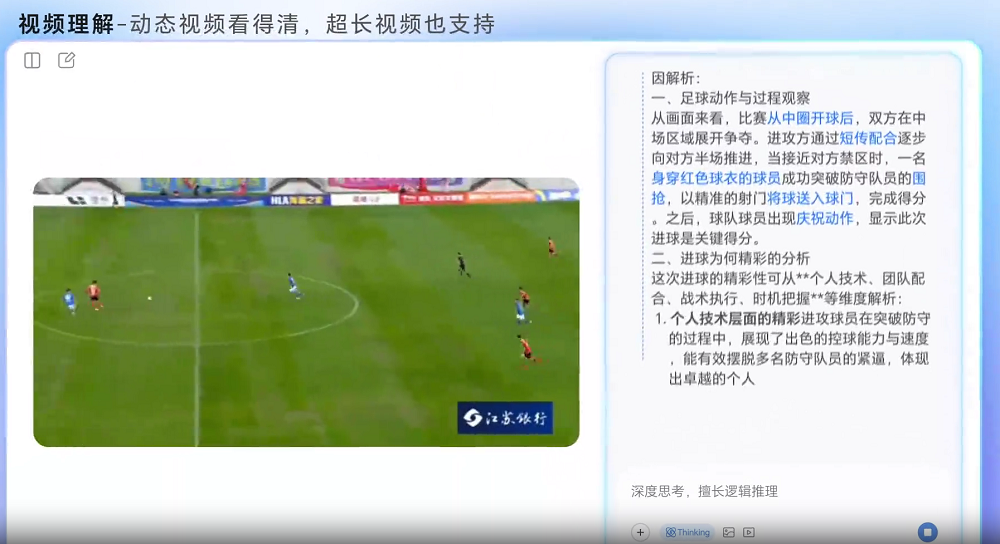
▲视频解析能力展示(图源:智谱)
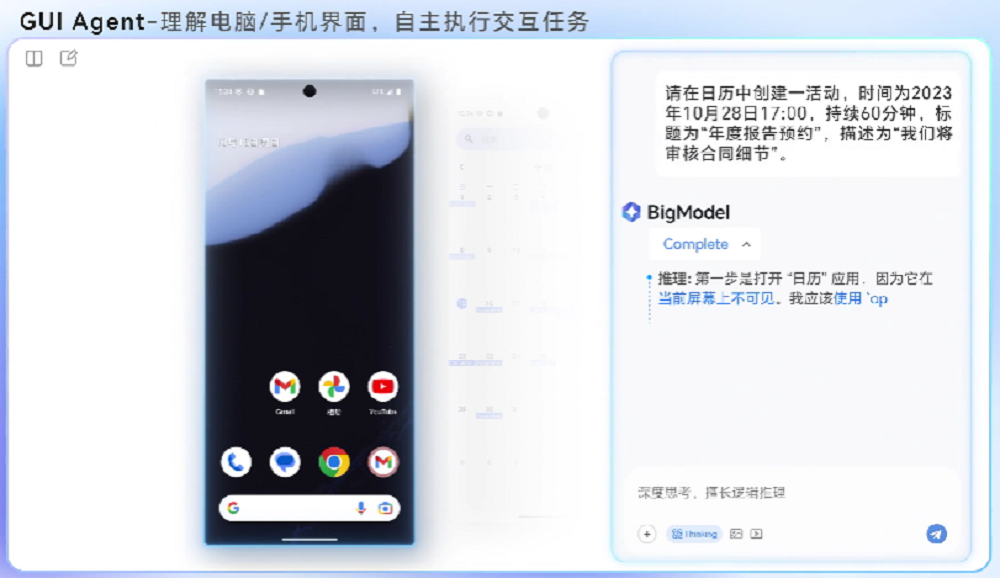
▲GUI Agent能力展示(图源:智谱)
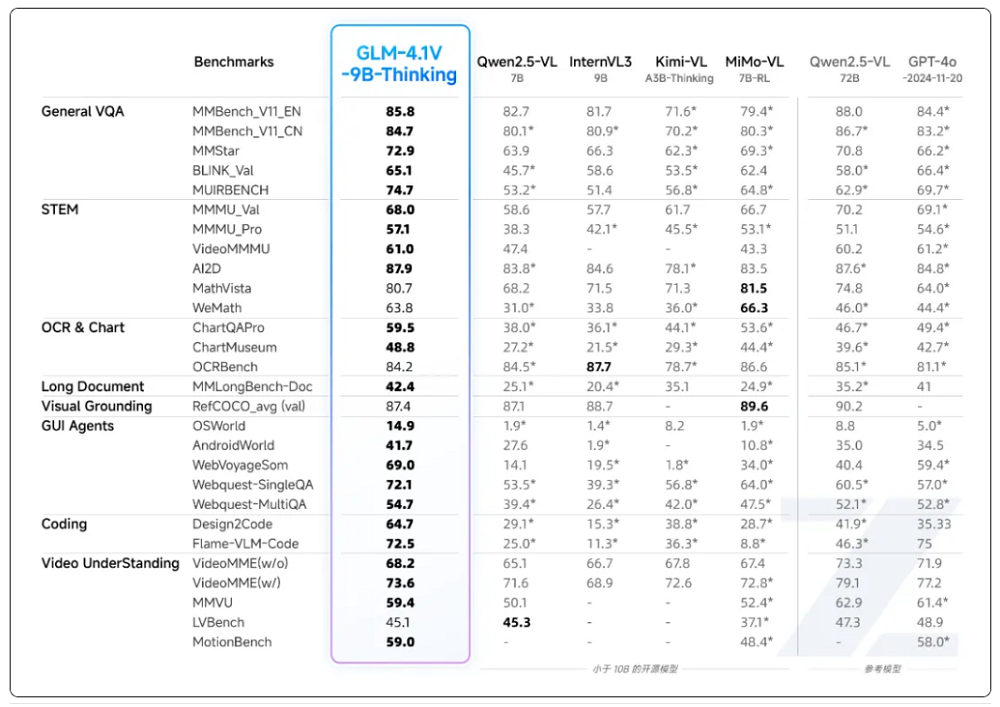
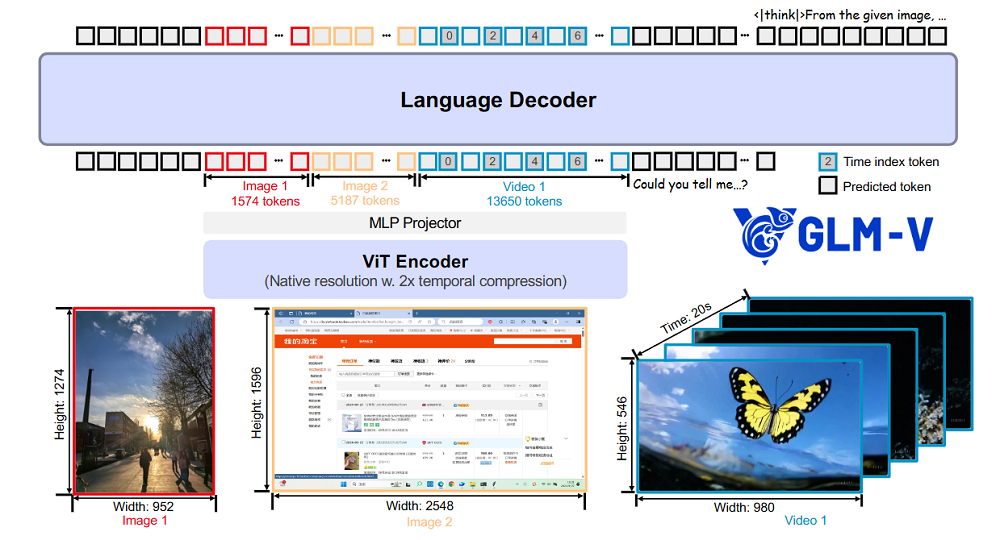
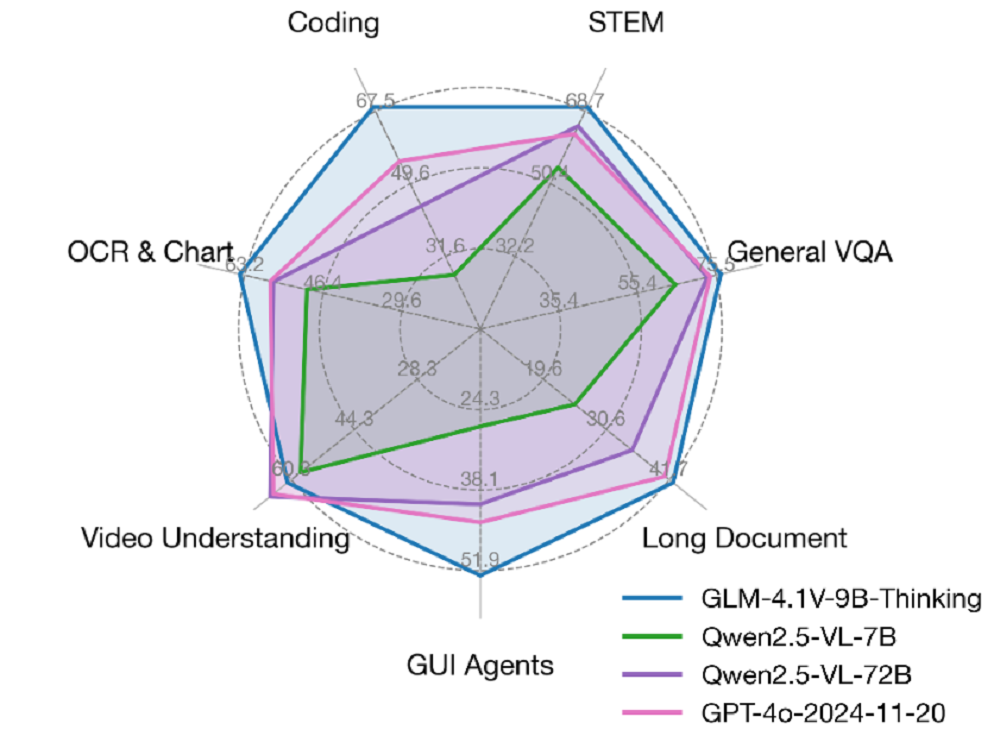
在模型的预训练阶段,智谱采用了分阶段渐进式的训练策略,通过两个紧密衔接的子阶段逐步构建和提升模型的多模态理解与长上下文处理能力。
首先展开的是多模态预训练阶段,这个阶段的核心目标是打牢模型的基础能力,使其建立起对多种模态数据的通用理解。这一阶段的训练数据,既有传统的图像字幕和交错图文,也包含了更具挑战性的OCR识别、视觉定位(Grounding)以及指令响应等多样化数据。
随后进入的长上下文持续训练阶段,则着重拓展模型处理复杂长序列数据的能力。这个阶段,智谱引入了更具挑战性的训练素材,包括连续的视频帧序列以及token数量超过8K的超长图文混合内容。
通过这两个阶段的递进式训练,模型逐步获得了处理高分辨率图像、视频序列以及超长文本等复杂场景的能力。
(文:智东西)