


新智元报道
新智元报道
【新智元导读】AI非上云不可、非集群不能?万字实测告诉你,32B卡不卡?70B是不是智商税?要几张卡才能撑住业务? 全网最全指南教你如何用最合适的配置,跑出最强性能。
今年上半年,随着DeepSeek R1的发布,国内大模型的应用迎来井喷式的发展,各种大模型的信息满天飞,连普通消费者都多多少少被大模型一体机给安利了,特别是满血版的DeepSeek 671B。
然而理性地来讲,671B模型的部署成本动辄百万起步,远超一般企业的IT预算。
同时,我们对大模型的使用与功能挖掘还停留在初期阶段,特别是在后千模大战的时代,32B/70B等中档模型已经可以满足许多企业的需求。
所以,如何选择一个适合自己的大模型,并为此大模型选择一台合适的工作站?今天我们就来为大家说一说这个话题。
为了解决大模型实用性和经济性的问题,我们重中之重是对其进行性能以及使用评估,为此我们使用了 Dell Precision 7960 塔式工作站,针对市面上最主流的模型进行了评测。


机器平台:Dell Precision 7960 Tower
GPU:单张、双卡及四卡 NVIDIA RTX™ 5880 Ada
CPU:Intel® Xeon® w7-3555
内存:64G DDR5 × 12

Dell Precision 7960 Tower
不同尺寸的大模型,应用的场景也各不相同。以下是我们此次主要测试的模型尺寸及相应的使用场景。

-
大语言模型

对于70B模型,我们还额外测试了其FP8量化的性能表现,来为有大并发用户数的情况提供参考。
-
多模态大模型
为了适应对多模态大模型的使用要求,我们还针对Qwen2.5的两个多模态大模型进行了测试,分别是7B以及32B的模型。
使用了目前广受欢迎的vllm推理引擎来进行测试,为了最大程度利用GPU的显存,将其「gpu utilization」参数设置为0.93。
操作系统:ubuntu22.04
Driver Version:570.124
CUDA:12.8
软件包:conda python3.10 torch2.6.0 vllm0.8.5
1. 运行vllm
首先,根据不同的GPU数量调整tensor-parallel-size参数。
vllm serve DeepSeek-R1-Distill-Qwen-7B --port 9812 --tensor-parallel-size 1 --gpu-memory-utilization 0.932. 运行测试脚本
然后,针对知识库的检索问答,我们写了一个测试脚本。
通过prompt让模型进行总结,对每个请求输入4k的token,输出约512个token的总结,并收集在此期间的性能指标。
3. 收集测试指标并汇总
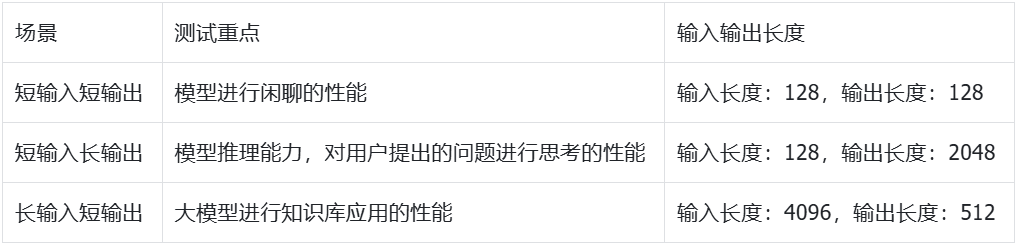
测试用例 为了贴近真实情况,使用了三种测试用例:
为了消除误差,每个测试进行了多次,并取平均值。
大语言模型测试
单卡NVIDIA RTX™ 5880 Ada运行7B/8B/14B模型 先说在NVIDIA RTX™ 5880 Ada单卡环境下测试的情况。
我们测试了DeepSeek-R1-Distill-Qwen-7B以及Qwen3-8B和Qwen3-14B。
由于32B/70B的模型的参数量较大,对显卡的显存需求更高,因此我们将在双卡及四卡中进行测试。
DeepSeek-R1-Distill-Qwen-7B模型测试
-
input 128/output 128
在测试batch size达到256情况下,平均输出吞吐率可以达到12.35 token/s,而总输出吞叶率最高可达3161 token/s。
其中,平均吞吐率能够反映模型对每一个请求的响应能力及速度,而总吞吐率则体现了机器总的处理能力。
与此同时,首字时延只有2.89秒左右,意味着用户在输出问题到获取模型的应答只需要消耗2.9秒的时间。
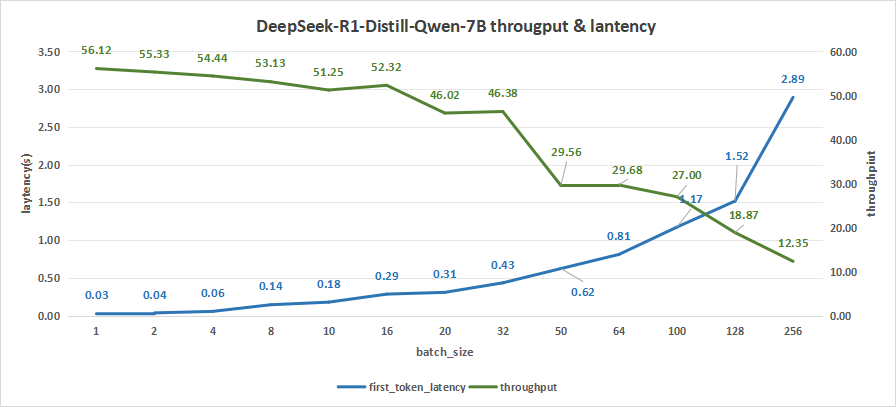
图1:DeepSeek-R1-Distill-Qwen-7B(NVIDIA RTX™ 5880 Ada ×1)
-
input 128/output 2048
如下表所示,DeepSeek-R1-Distill-Qwen-7B在测试batch size达到256情况下:
平均吞吐率可以达到16.82 token/s,而吞叶率最高可达4396 token/s,同时,首字时延为2.91秒左右。
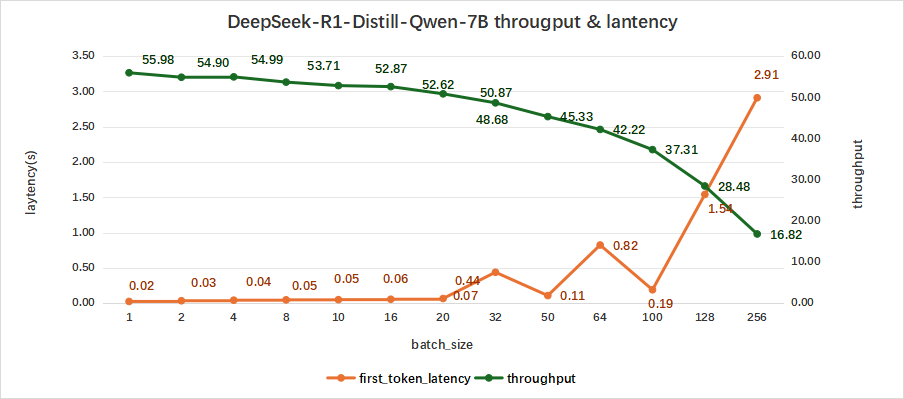
图2:DeepSeek-R1-Distill-Qwen-7B(NVIDIA RTX™ 5880 Ada ×1)
-
input 4096/output 512
在batch size为256时,平均吞吐率为4.24 token/s,而吞吐率可达最高1085 token/s。但同时,其首字时延高达167.43秒,这会严重影响到我们的用户体验。
因此,比较合理的batch size应该是在16-32之间。
比如batch_size=20,其首字时延为6.03s,而平均吞吐率可以达到35.71 token/s,总的吞吐率为714 token/s。
这样会比较符合我们用户在使用大模型做一些知识库检索和应用时更希望得到的体验。
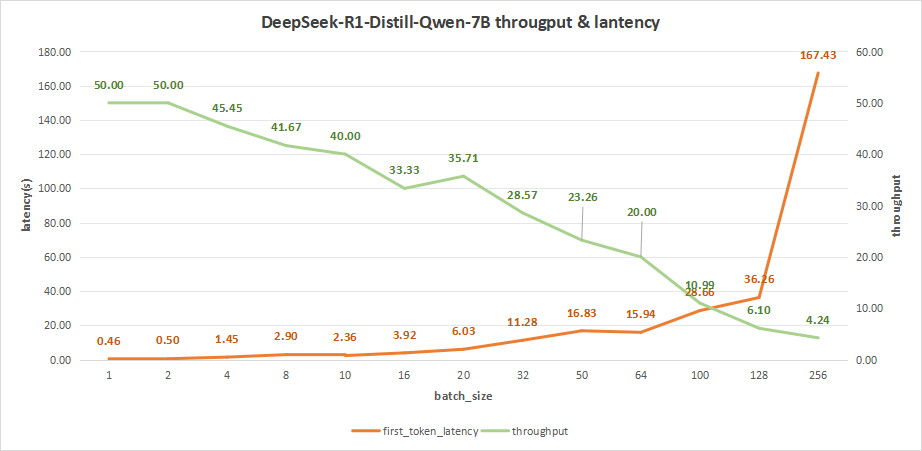
图3:DeepSeek-R1-Distill-Qwen-7B(NVIDIA RTX™ 5880 Ada ×1)
-
input 128/output 128
Qwen3-8B在测试batch size达到256情况下,平均吞吐率可达11.31 token/s,而吞叶率最高可达2895 token/s,同时,首字时延只有2.93秒左右。
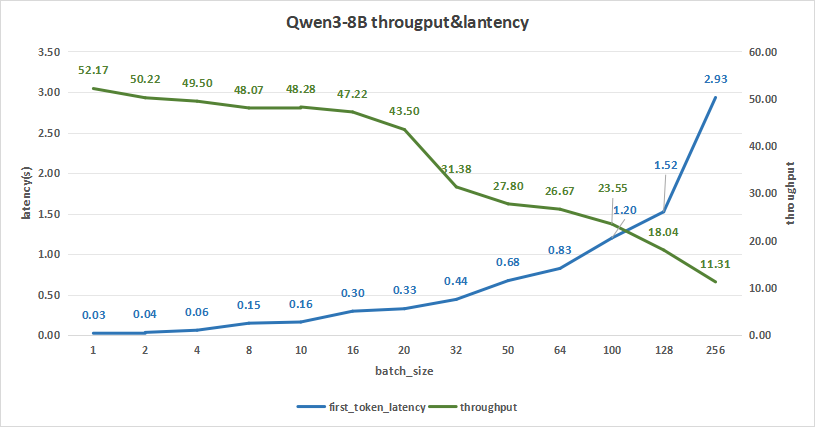
图4:Qwen3-8B(NVIDIA RTX™ 5880 Ada ×1)
-
input 128/output 2048
Qwen3-8B的测试结果如下,在batch size为256时,平均吞吐率为13.40 token/s,吞吐率可达最高3430.40 token/s,但同时,首字总时延达到3.08秒。
所以比较合理的batch size可以是128。
这样首字时延约为1.51秒,而平均吞吐率能达到23.88 token/s,吞吐率也能达到3056.64token/s。
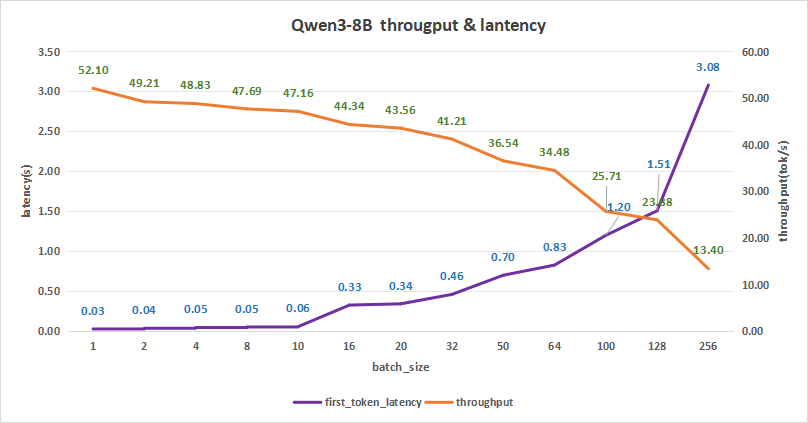
图5:Qwen3-8B(NVIDIA RTX™ 5880 Ada ×1)
-
input 4096/output 512
Qwen3-8B测试结果如下,在batch size为256时,平均吞吐率为7.94 token/s,而总吞吐率可达最高2033 token/s,但同时,其首字时延高达217.69秒,用户体验不佳。
因此,合理的batch size应该是在10-20之间。
比如batch size=16,其首字时延为5.18s,而平均吞吐率可以达到25 token/s,总吞吐率为400 token/s。
如此一来,这更符合我们用户在使用大模型做一些知识库检索和应用时,更希望得到的体验。
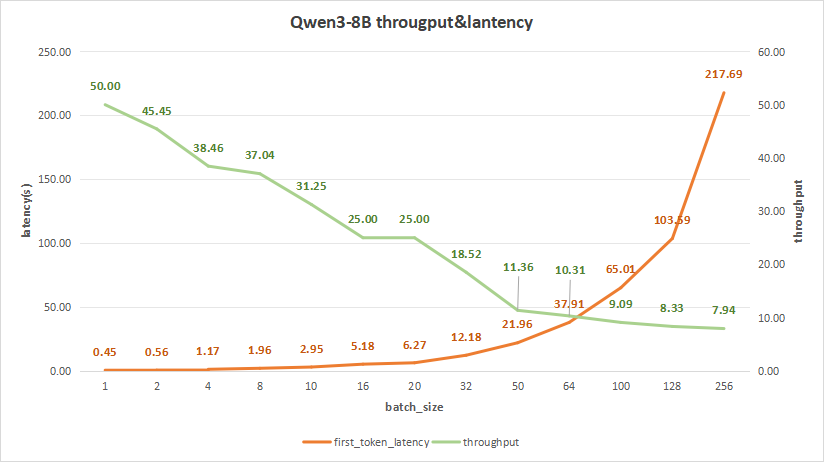
图6:Qwen3-8(NVIDIA RTX™ 5880 Ada ×1)
-
input 128/output 128
如下图,可以看出在batch size=256时,平均吞吐率可达5.69 token/s,而总吞叶率最高可达1457 token/s。但与此同时,首字时延达到6.01秒左右。
为追求更好的用户体验,满足用户在日常对话中的需求,建议batch size=128或者100,保证首字时延在2-3秒。
而且,在batch size=128时,平均吞吐率可达9.03 token/s,总吞吐量可以达到1156 token/s。
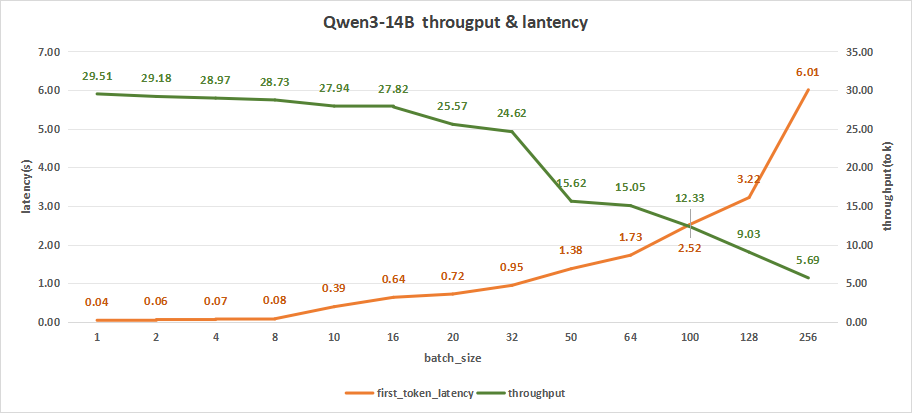
图7:Qwen3-14B(NVIDIA RTX™ 5880 Ada ×1)
-
input 128/output 2048
Qwen3-14B的测试结果如下,在batch size为256时,平均吞吐率为6.09 token/s,总吞吐率可达1552 token/s,但首字总时延达到6.06秒,这个表现是用户不太可以接受的。
如果体验要更好的话可以设置batch size为128。
此时,首字时延约为3.36秒,而且平均吞吐率能达到14.22 token/s,总吞吐率甚至能达到最高的1820 token/s。
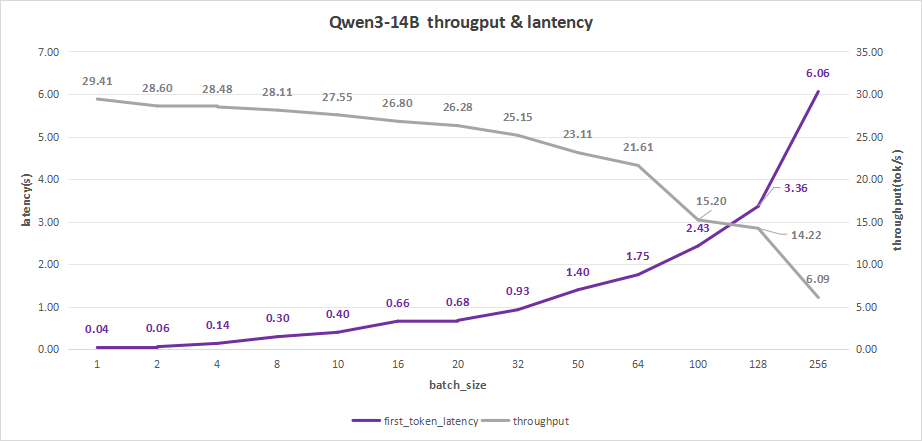
图8:Qwen3-14B(NVIDIA RTX™ 5880 Ada ×1)
-
input 4096/output 512
Qwen3-14B测试结果如下,在batch size为256时,会出现部分的并发请求失败的现象,这是由于请求并发数过多,而显卡性能不足,无法同时处理多个请求,因此我们只统计到128的并发数。
而在batch size为128时,平均吞吐率为8.77 token/s,而吞吐率可达最高2245 token/s,但同时,其首字时延高达194.19秒,这会严重影响到我们的用户体验。
因此,比较合理的batch size应该是在10-20之间。
比如batch size=16,其首字时延为8.52s,而平均吞吐率可以达到17.86 token/s,总的吞吐率为286 token/s,这会更符合我们用户在使用大模型做一些知识库检索和应用时的使用预期。
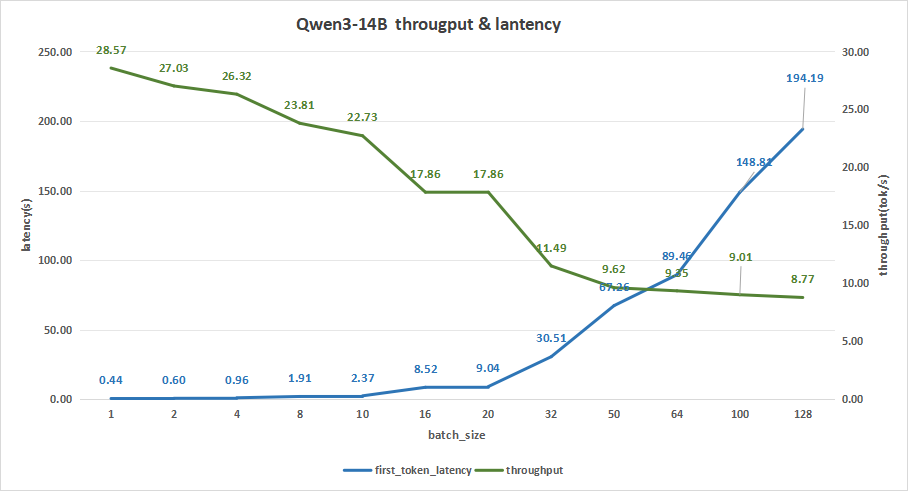
图9:Qwen3-14B(NVIDIA RTX™ 5880 Ada ×1)
图10:单卡NVIDIA RTX™ 5880 Ada功率
接下来我们看看双卡NVIDIA RTX™ 5880 Ada运行DeepSeekR1-7B、Qwen3-8B、Qwen3-14B的模型的情况,另外还加上了Qwen3-32B的模型来做测试。
DeepSeekR1-7B模型测试
-
input128/output 128
如下表所示,DeepSeek-R1-Distill-Qwen-7B在测试batch size达到256情况下,平均吞吐率达到21.59 token/s,而总吞叶率最高可达5528 token/s,同时,首字时延也在1.61秒左右。
相比之下,我们可以选择batch size区间为128-256作为大模型进行日常对话时的基础指标。
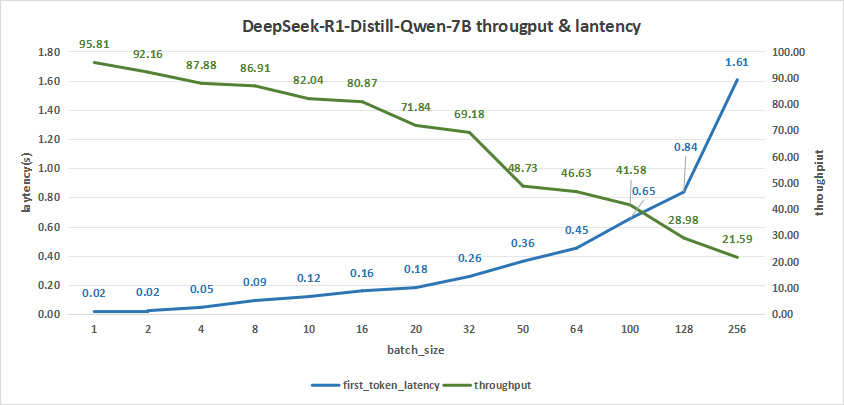
图11:DeepSeek-R1-Distill-Qwen-7B(NVIDIA RTX™ 5880 Ada ×2)
-
input 128/output 2048
DeepSeek-R1-Distill-Qwen-7B的测试结果如下,在batch size为256时,平均吞吐率为32.53 token/s,总吞吐率可达最高8327 token/s,同时,首字总时延也才达到0.36秒。
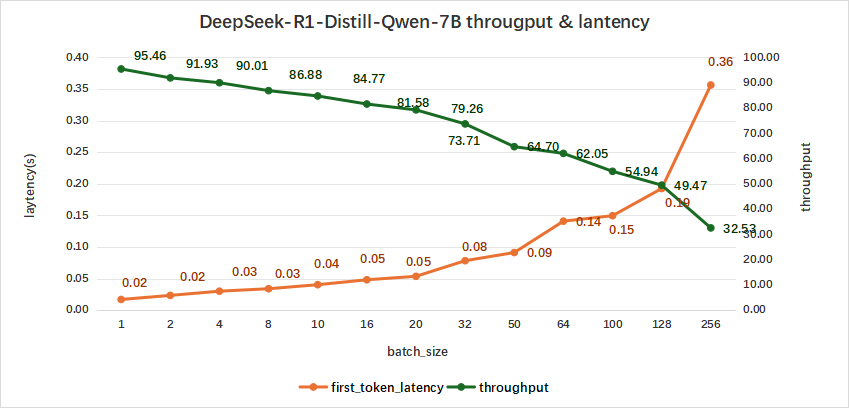
图12:DeepSeek-R1-Distill-Qwen-7B(NVIDIA RTX™ 5880 Ada ×2)
-
input 4096/output 512
依测试结果来看,我们建议的batch size在10-32之间,期间首字时延都是2-10秒。
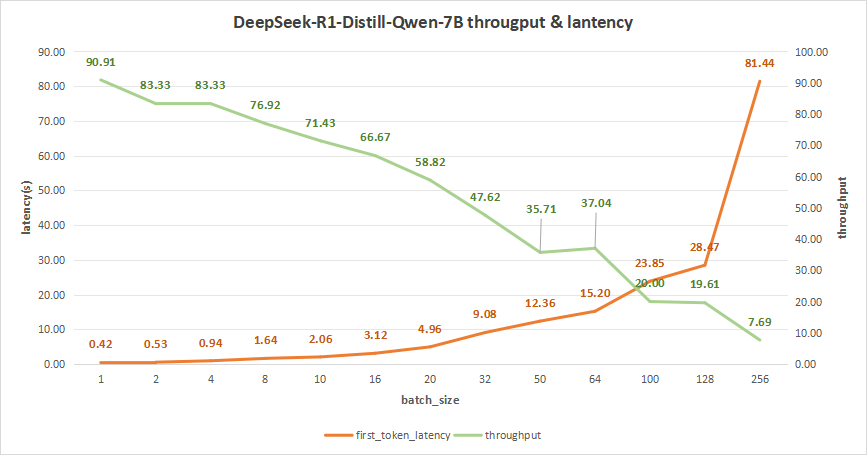
图13:DeepSeek-R1-Distill-Qwen-7B(NVIDIA RTX™ 5880 Ada ×2)
Qwen3-8B模型测试
-
input 128/output 128
Qwen3-8B测试结果如下,在batch size为256时,平均吞吐率可以达到17.63 token/s,而总吞吐率可达最高4508.57 token/s,与此同时,首字时延也才达到1.90秒。
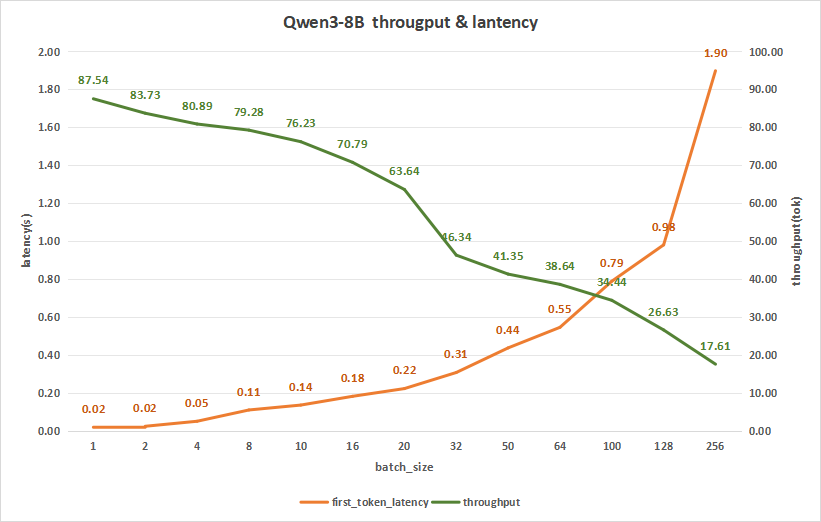
图14:Qwen3-8B(NVIDIA RTX™ 5880 Ada ×2)
-
input 128/output 2048
Qwen3-8B的测试结果如下,在batch size为256时,平均吞吐率为22.12 token/s,总吞吐率可达最高5663.89 token/s,同时,首字总时延也才达到2.18秒。
如果希望优化用户体验的话,可以选择batch size为128。
此时,首字时延约为1.01秒,而平均吞吐率能达到35.22 token/s,总吞吐率也能达到4508 token/s。
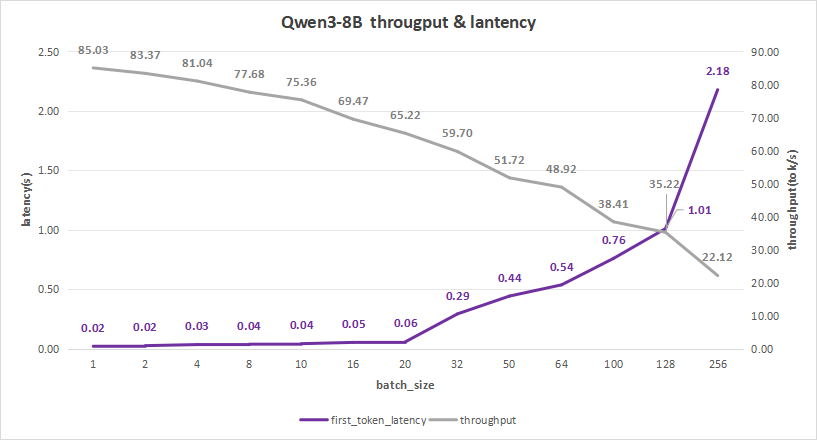
图15:Qwen3-8B(NVIDIA RTX™ 5880 Ada ×2)
-
input 4096/output 512
Qwen3-8B测试结果如下,在batch size为256时,平均吞吐率为6.58 token/s,而吞吐率可达最高1684 token/s,但同时,其首字时延高达141.89秒,用户体验不佳。
因此,我们可以选择batch size在16-32之间。
这时首字时延区间为5-10秒,比如batch size=20,其首字时延为5.77s,而平均吞吐率可以达到40 token/s,总吞吐率为800 token/s,这样可以更好地支撑用户在知识库检索应用方面的需求。
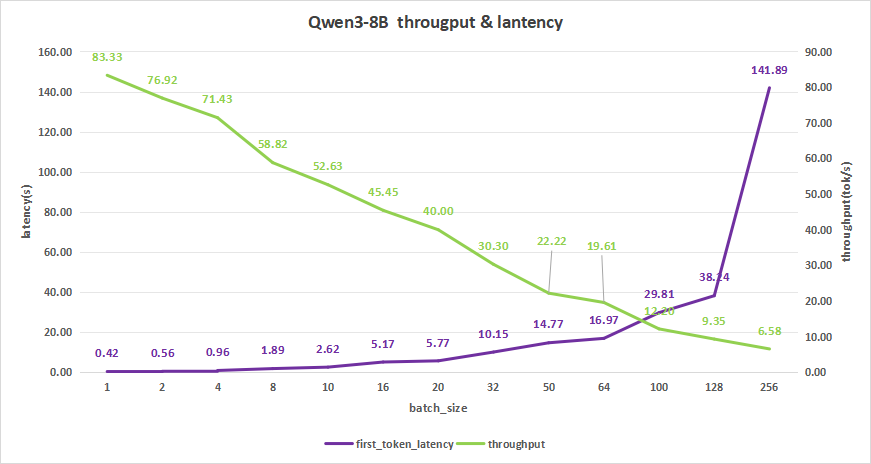
图16:Qwen3-8B(NVIDIA RTX™ 5880 Ada ×2)
Qwen3-14B模型测试
-
input 128/output 128
在batch size为256时,平均吞吐率可达12.19 token/s,总吞吐率最高3121 token/s,同时,首字时延才达到2.83秒,可以算是比较适合我们在日常对话的使用了。
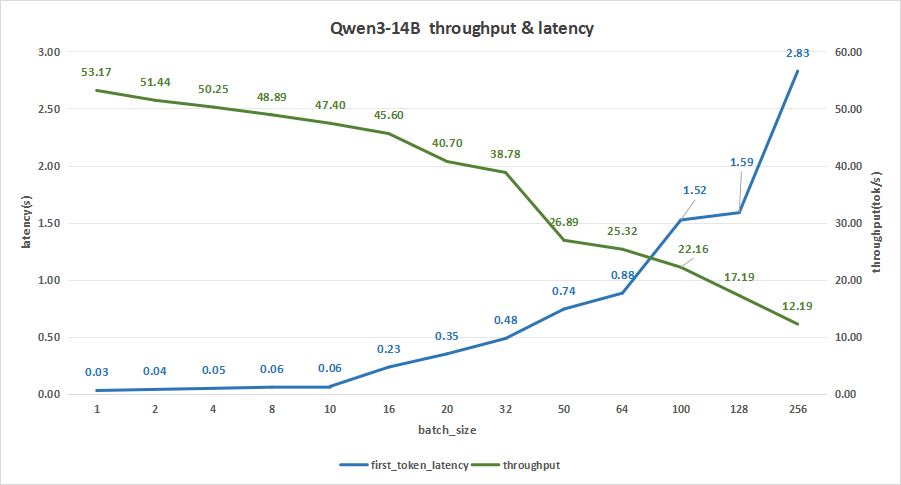
图17:Qwen3-14B(NVIDIA RTX™ 5880 Ada ×2)
-
input 128/output 2048
在batch size为256时,平均吞吐率为15.61 token/s,总吞吐率可达最高3996 token/s。同时,首字总时延也才达到3.33秒。
追求更好的用户体验可以将batch size设置为128,其首字时延约为1.62秒,而平均吞吐率能达到25.54 token/s,总吞吐率也能达到3269 token/s。
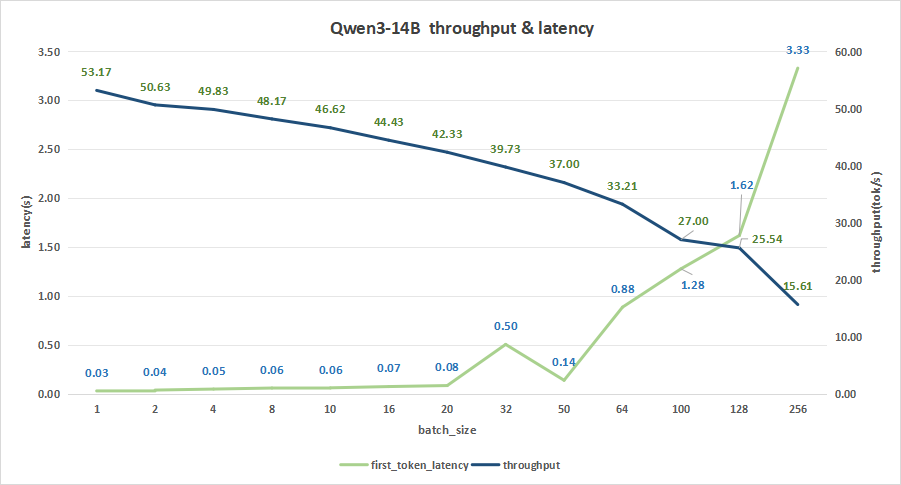
图18:Qwen3-14B(NVIDIA RTX™ 5880 Ada ×2)
-
input 4096/output 512
在batch size为256时,平均吞吐率为5.15 token/s,而吞吐率可达最高1318 token/s,不过首字时延高达203.56秒,并不是一个理想的使用状态。
比较合理的batch size应该是在10-20之间。
比如batch size=20,其首字时延为6.37s,平均吞吐率达到28.57 token/s,总吞吐率为571 token/s。对于采用大模型做知识库应用的话,可以达到一个相对理想的使用情况。
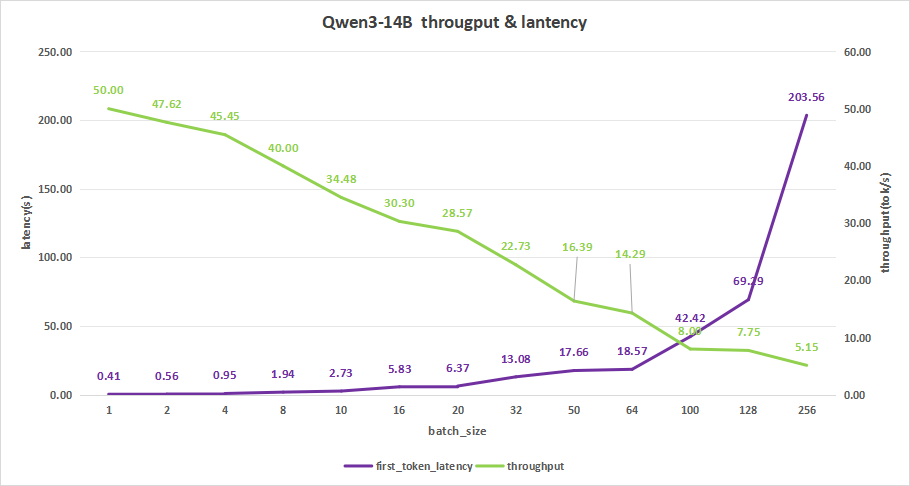
图19:Qwen3-14B(NVIDIA RTX™ 5880 Ada ×2)
Qwen3-32B模型测试
-
input 128/output 128
在batch size为256时,平均吞吐率可达4.42 token/s,总吞吐率最高1133 token/s,但同时,首字时延达到7.67秒,这其实和我们在日常对话的期望是相悖的。
较为合理的batch size应该是在20-64之间。
比如batch size为50,首字时延只有1.47秒,平均吞吐率为12.90 token/s,而总吞吐率更是达到865 token/s,比较适合我们在日常对话的使用。
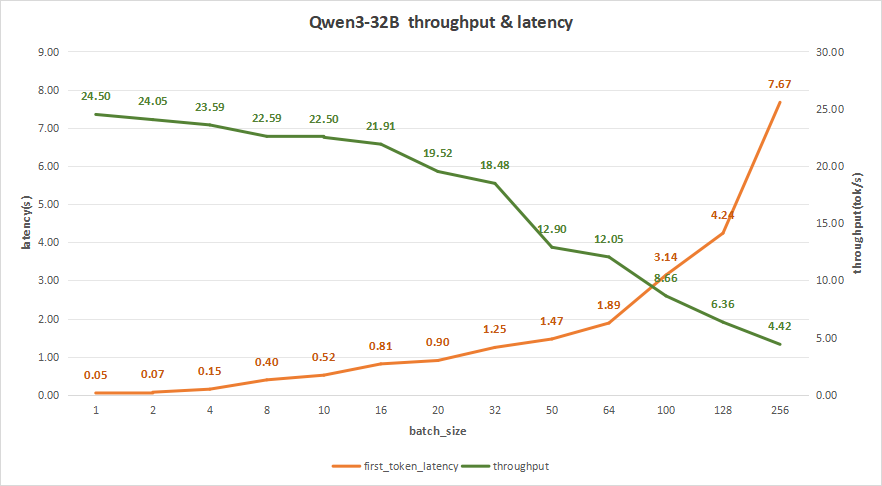
图20:Qwen3-32B(NVIDIA RTX™ 5880 Ada ×2)
-
input 128/output 2048
在batch size为256时,平均吞吐率为6.22 token/s,总吞吐率可达最高1591 token/s,同时,首字总时延也达到7.3秒。
同样的,如果注重用户体验的话,可以选择batch size为50-100。
比如batch_size=64,其首字时延约为2.26秒,而平均吞吐率能达到16.08 token/s,总吞吐率也能达到1028 token/s。
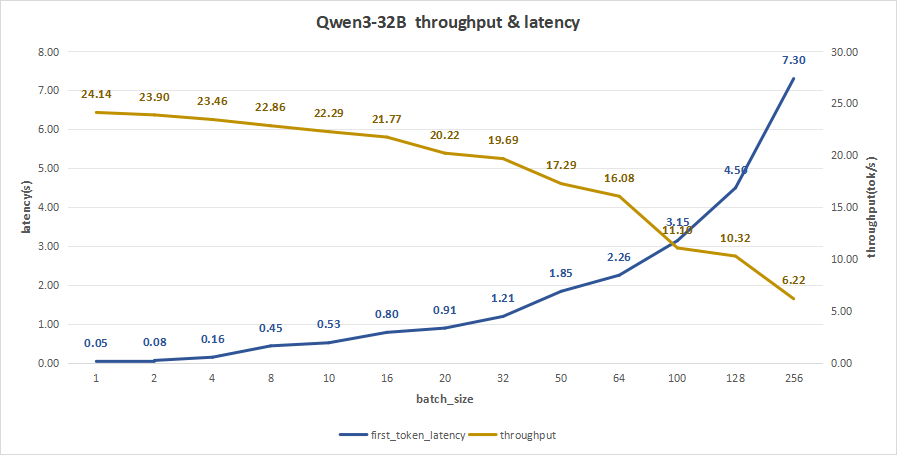
图21:Qwen3-32B(NVIDIA RTX™ 5880 Ada ×2)
-
input 4096/output 512
在batch size为256时,会出现部分的并发请求失败的现象,这是由于请求并发数过多,而显卡性能不足,无法同时处理多个请求,因此我们只统计到128的并发数。
而在batch size为128时,平均吞吐率为7.35 token/s,而吞吐率可达最高941 token/s,但同时,其首字时延高达233.39秒,这会严重影响到用户体验。
测试对比下来,比较合理的batch size应该是在10-20之间。
此时首字时延约为3-9秒,比如batch size为10,其首字时延约为3.70s,而平均吞吐率可以达到16.95 token/s,总吞吐率为170 token/s,这会更符合日常用户的需求。
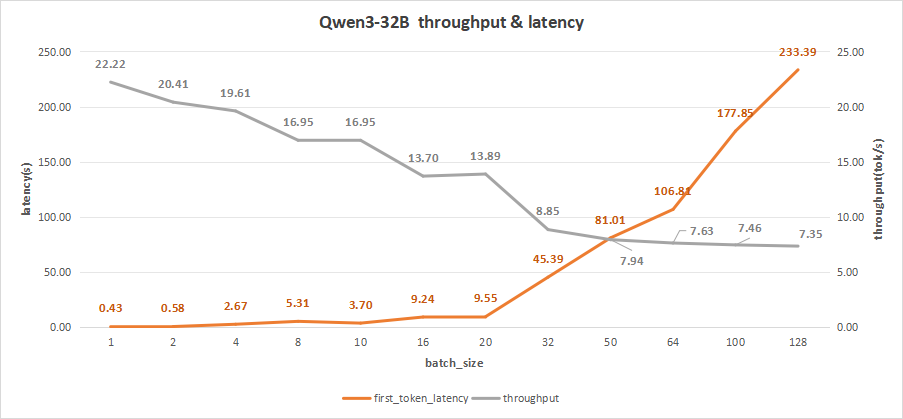
图22:Qwen3-32B(NVIDIA RTX™ 5880 Ada ×2)
双卡GPU功率
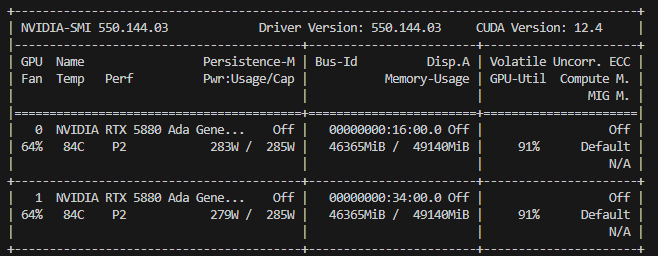
图23:双卡NVIDIA RTX™ 5880 Ada运行功率
最后来看重磅的四卡情况,我们选择DeepSeek-R1-Distill-Llama-70B的模型,并且进行了FP16与FP8量化版的对比测试,同时也测试了Qwen3-32B模型在四卡情况下的推理性能。
Qwen3-32B模型测试
-
input 128/output 128
batch size为256时,平均吞吐率可达8.52 token/s,总吞吐率达到2182 token/s。同时,首字时延达到1.98秒。
而在batch size为128时,平均吞吐率可达21.09 token/s,总吞吐率达到最高的2698 token/s,此时首字时延达到0.38秒。
相比之下batch size为128时配置的模型更适用于用户日常的对话。
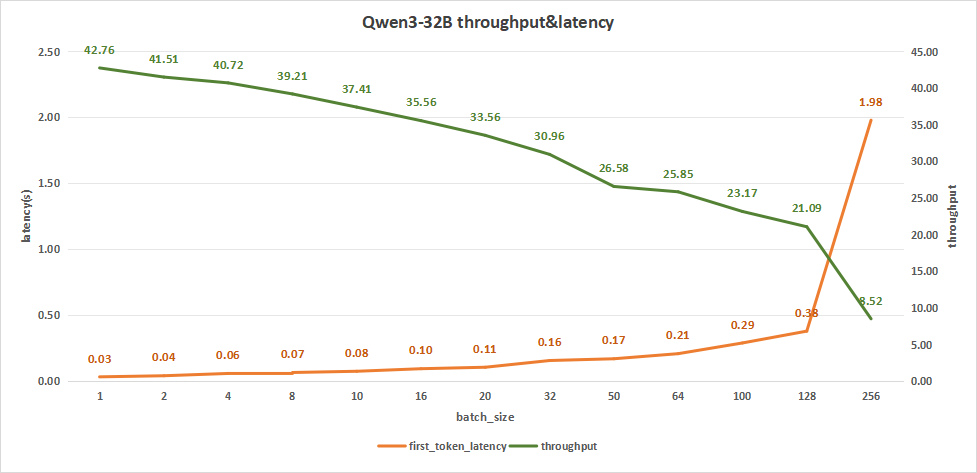
图24:Qwen3-32B(NVIDIA RTX™ 5880 Ada ×4)
-
input 128/output 2048
batch size为256时,平均吞吐率为10.86 token/s,总吞吐率可达最高2779 token/s,同时,首字总时延也达到4.48秒。
如果希望用户体验更好的话,可以选择batch size为100或者128。
比如batch size=100,其首字时延约为0.29秒,而平均吞吐率能达到21.84 token/s,总吞吐率也能达到2183 token/s。
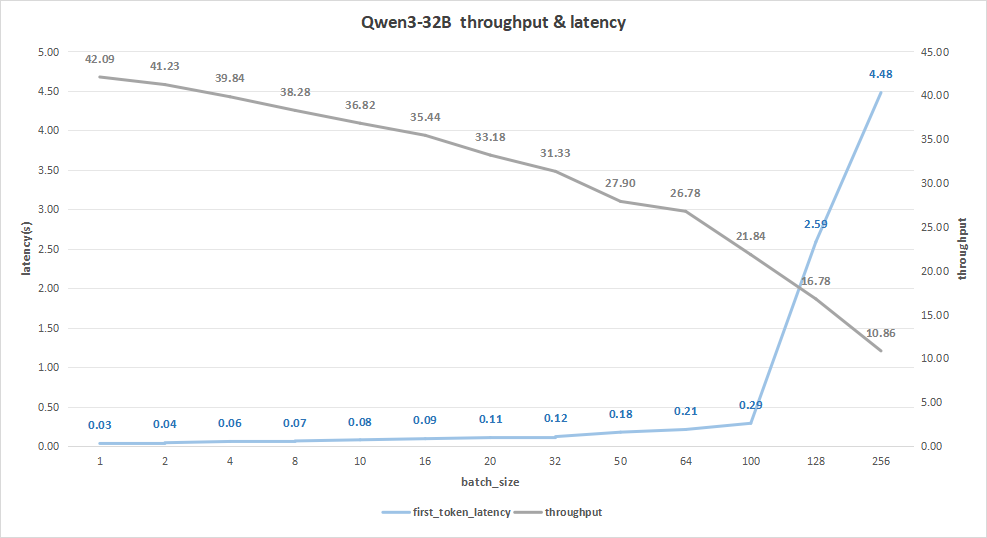
图25:Qwen3-32B(NVIDIA RTX™ 5880 Ada ×4)
-
input 4096/output 512
当batch size为256时,平均吞吐率为3.62 token/s,而吞吐率可达最高927 token/s,但同时,其首字时延高达262.12秒,严重降低用户体验。
比较合适的batch size应该是在10-20之间。
比如batch size=16,其首字时延为6.92s,而平均吞吐率可以达到25 token/s,总的吞吐率为400 token/s,此时效果会比较好。
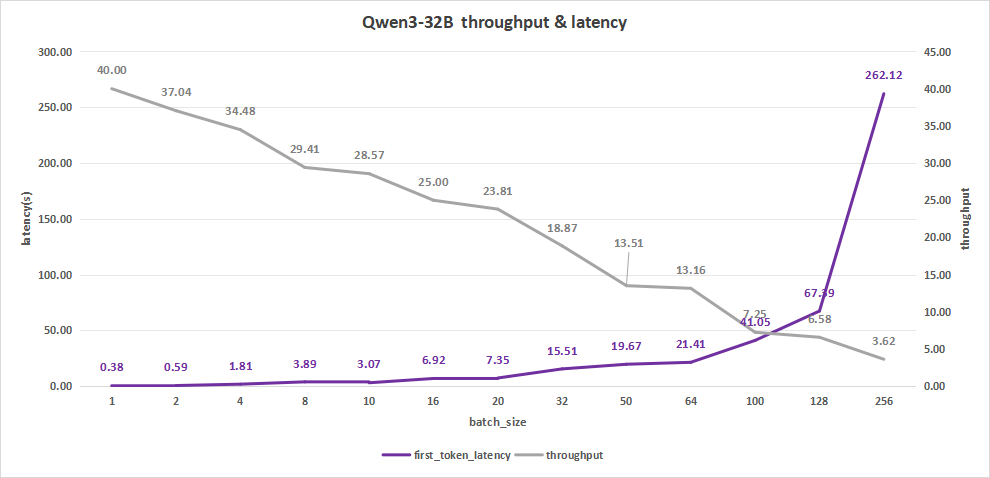
图26:Qwen3-32B(NVIDIA RTX™ 5880 Ada ×4)
DeepSeek-R1-Distill-Llama-70B/70B-FP8对比测试
-
input 128/output 128
DeepSeek-R1-Distill-Llama-70B在batch size为100的情况下,平均吞吐率可达到8.26 token/s,总的吞吐率可达到825 token/s。
虽然batch size为256时,可以达到最高总吞吐率999 token/s,但是其首字时延达到了9.22秒,不适合用户在日常对话中使用,会严重影响用户的体验。
综合比较batch size设置为100是在此用例中较为理想的。
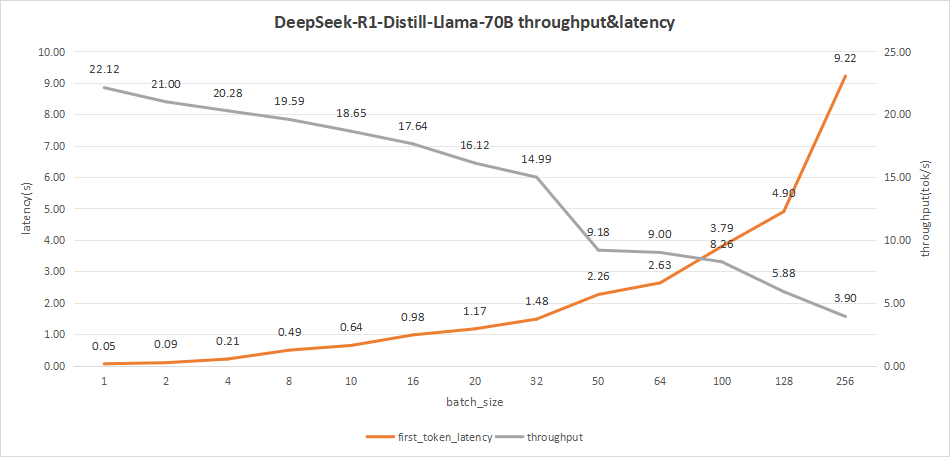
图27:DeepSeek-R1-Distill-Llama-70B(NVIDIA RTX™ 5880 Ada ×4)
为了对比,我们对DeepSeek-R1-Distill-Llama-70B进行了FP8的量化。其表现如下图。
在测试batch size达到256的情况下,平均吞吐率为4.53 token/s,而总吞叶率最高可达1160 token/s,但首字时延达到了7.96秒。
同样的,我们关注batch size为100的情况下,平均吞吐率可达到8.90 token/s,总吞吐率可达到890 token/s,因此batch size选为100时也同样较为合适。
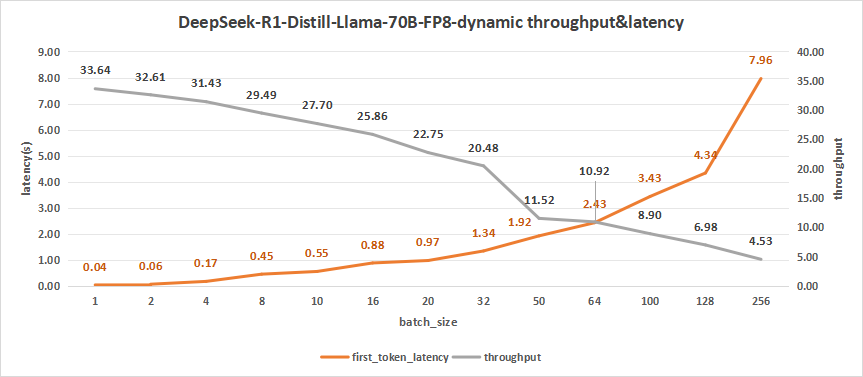
图28:DeepSeek-R1-Distill-Llama-70B-FP8-dynamic(NVIDIA RTX™ 5880 Ada ×4)
-
input 128/output 2048
DeepSeek-R1-Distill-Llama-70B在batch size为100时,平均吞吐率可达到11.46 token/s,总吞吐率可达到1146 token/s。
即使batch size为256时,能够达到最高总吞吐率1504 token/s,但是其首字时延达到了9.01秒,效果不佳。
因此batch size设置为100可以达到较为理想的效果。
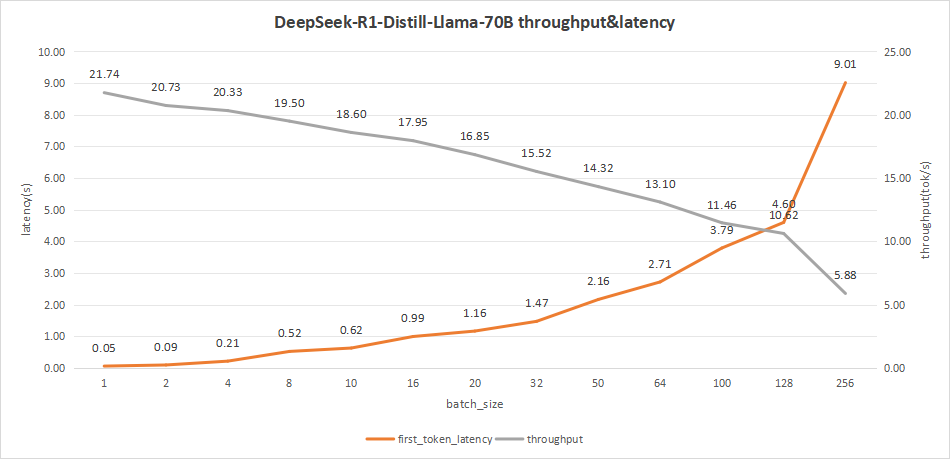
图29:DeepSeek-R1-Distill-Llama-70B(NVIDIA RTX™ 5880 Ada ×4)
我们同样在这个用例,来看看DeepSeek-R1-Distill-Llama-70B FP8量化的情况。测试结果如下。
在batch size达到256时,平均吞吐率为8.27 token/s,总吞叶率最高可达1882 token/s,但首字时延达到了8.27秒。
同样的,我们关注batch size为100的情况下,平均吞吐率可达到13.61 token/s,总的吞吐率可达到1361 token/s,而首字时延也只有3.49秒。
因此batch size选为100时也同样较为合适。
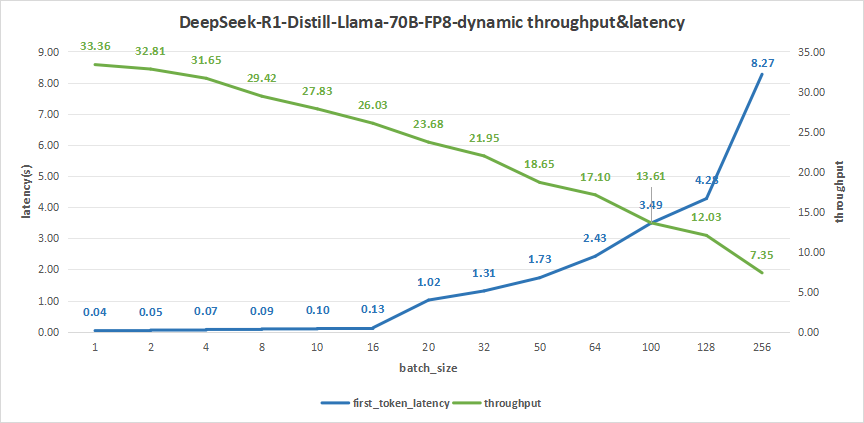
图30:DeepSeek-R1-Distill-Llama-70B-FP8-dynamic(NVIDIA RTX™ 5880 Ada ×4)
-
input 4096/output 512
DeepSeek-R1-Distill-Llama-70B测试情况如下图。
在batch size为256时,会出现部分的并发请求失败的现象,这是由于请求并发数过多后,导致显卡性能无法同时处理多个请求,因此只统计到128的并发数。
而在batch size为128时,首字时延高达279.36秒,会降低用户体验。
综合看来,比较合理的batch size应该是在10-16之间。
期间的时延为5-8秒,比如我们可以选取batch size为10,其首字时延为5s,而平均吞吐率可以达到14.49 token/s,总的吞吐率为145 token/s。
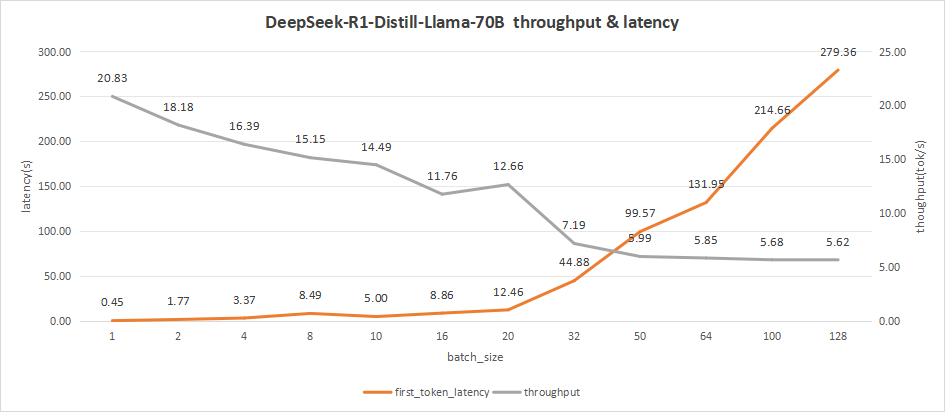
图31:DeepSeek-R1-Distill-Llama-70B(NVIDIA RTX™ 5880 Ada ×4)
我们再来看看70B FP8量化后的模型测试情况。
DeepSeek-R1-Distill-Llama-70B-FP8-dynamic测试结果如下,同样在batch size为256时,出现部分的并发请求失败的现象,因此我们并未将其进行统计。
而在batch size=128时,其平均吞吐率为4.12 token/s,而吞吐率可达最高527 token/s,但同时,其首字时延高达136.52秒,用户体验严重受限。
因此,比较合理的batch size应该是10左右,比如我们可以选取batch size=10,其首字时延为4.18s,而平均吞吐率可以达到20.41 token/s,总的吞吐率为204 token/s。
这会更符合我们用户在使用大模型做一些知识库检索和应用时的预期。
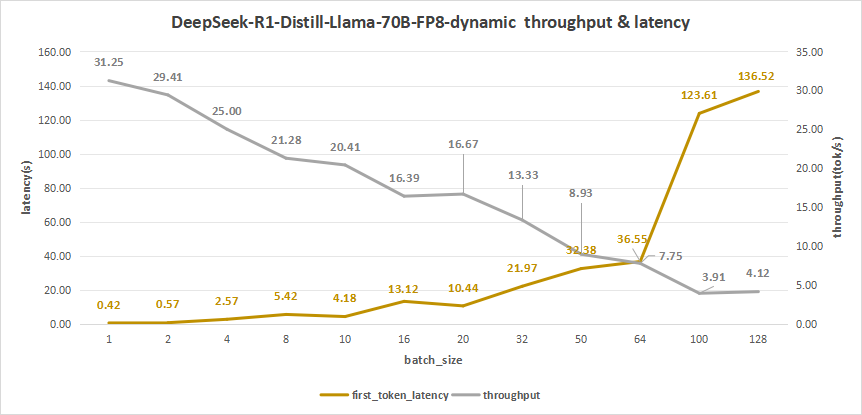
图32:DeepSeek-R1-Distill-Llama-70B-FP8-dynamic(NVIDIA RTX™ 5880 Ada ×4)
四卡GPU功率和利用率
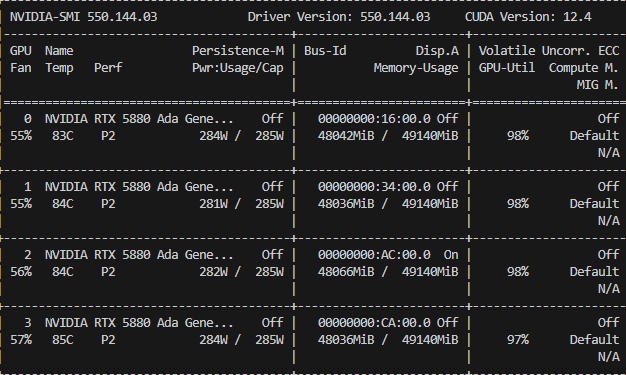
图33:四卡NVIDIA RTX™ 5880 Ada功率和利用率
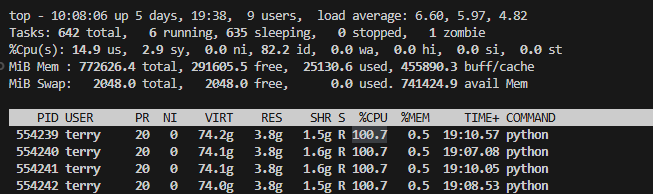
图34:四卡NVIDIA RTX™ 5880 Ada系统资源的占用率
70B FP16 or FP8?
对于70B的模型,使用FP16与FP8的考量,我们依据测试结果做如下建议:
-
对于要求多并发的需求,如果是用于知识库应用场景,我们建议使用FP8量化版本。
如上测试可知,FP16版本的70B模型,在体验较为理想的要求下(吞吐率达到18-20 token/s,首字时延3秒内),并发用户数仅为4左右。
而FP8版本,在相似体验的情况下,可达到8个并发访问。
-
对于推理有较多需求的用户,建议使用FP16版本。
因为在多并发的情况下,例如一百个并发用户使用,其用户体验是相似的,都可以获得每秒至少11个token的速度,同时首字时延均为3秒多。
而在相似用户体验的情况下,FP16版本的70B模型,相比FP8版本,能带来更高的准确率。
以上的测试用例是比较理想化的,为了仿真用户的真实使用场景,我们将在常用模型上模拟用户随机发送请求的情况。
使用的测试模型为Qwen3-8B和Qwen3-32B,分别使用单卡和四卡的NVIDIA RTX™ 5880 Ada进行测试。
我们将使用知识库检索这一用例进行测试,即在input 4k/output 512的情况下,通过泊松分布来模仿用户在不同时间点随机发送请求。
为了发现使用瓶颈,我们仿真了每分钟60次及100次请求的情况,测试结果见下。
单卡NVIDIA RTX™ 5880 Ada运行Qwen3-8B
我们先看Qwen3-8B在单卡NVIDIA RTX™ 5880 Ada上的测试结果:
先看第一个测试案例60reqs/min,泊松分布的参数λ=1,我们通过泊松分布发送请求的随机性来模仿多个用户在不同时间点使用的情况,发送请求的泊松分布如下所示:
(因为是泊松分布的随机性,所以只能在指定请求数下尽量保证期望时间为60s,在30s时出现最高的请求数5,存在部分空闲的时间间隔没有发送请求。)
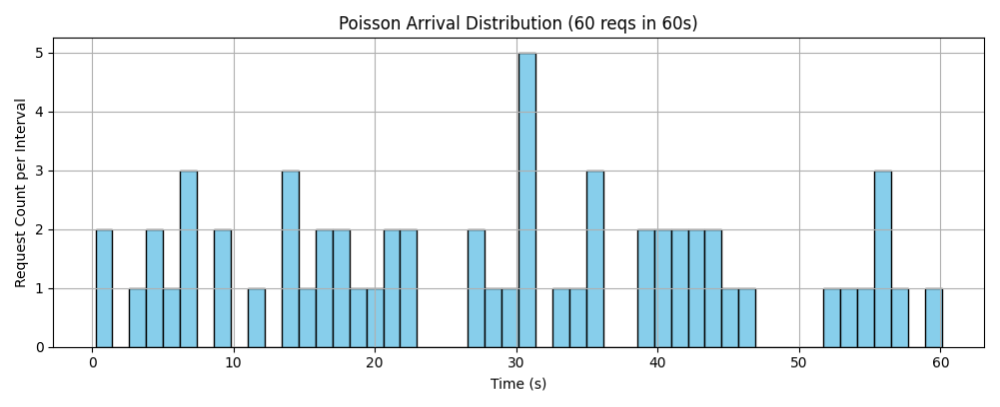
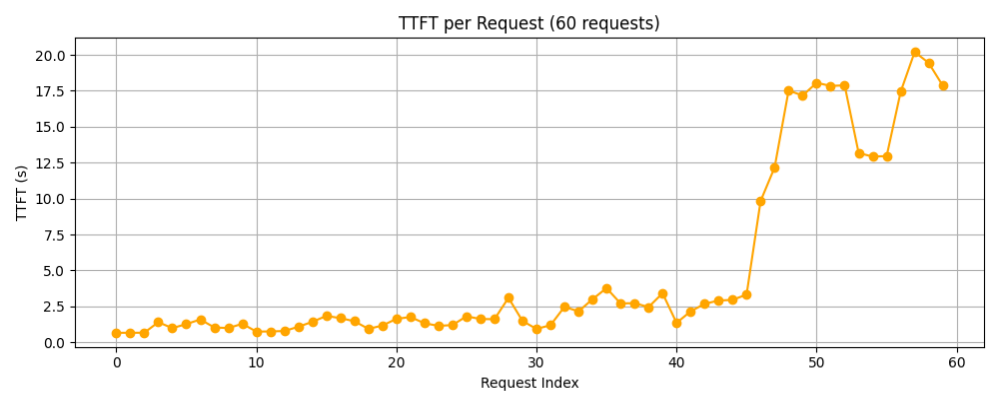
由下图的每个请求的首字时延可以看到,在前40个请求中,首字时延还是比较稳定的,但是在之后有明显上升的趋势。
由泊松分布图可以猜测,应该是在30s处发送了5个请求,之后又在40s处连续发送多个请求,可能导致模型无法及时处理,从而出现阻塞的现象,导致之后的请求时延增大。
具体测试的结果如下表所示:
可以看出60reqs/min在单卡的8B模型上表现不俗,平均每个请求的首字时延只有5秒,平均吞吐率也能达到10.9 token/s,对于用户在进行知识库检索问答时,有比较良好的体验。

第二个测试案例是100reqs/min,泊松分布的参数λ=1.67。
同样的,我们通过泊松分布发送请求的随机性来模仿多个用户在不同时间点使用的情况,发送请求的泊松分布如下所示:
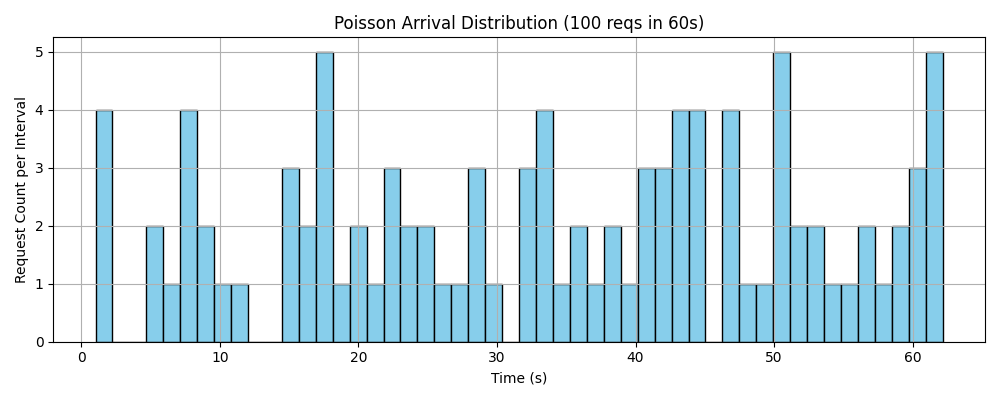
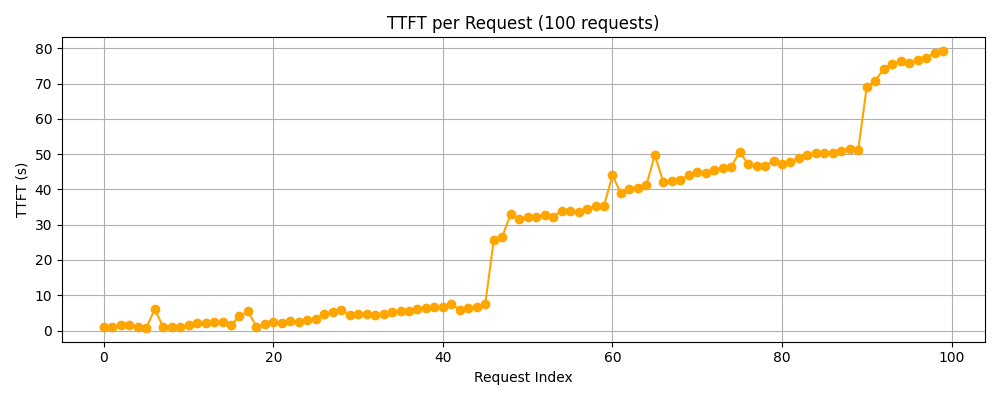
由下图的每个请求的首字时延可以看到,同样在前40个请求中,首字时延还是比较稳定的,但是在之后有明显上升的趋势。
可以得知,此时已经超过了显卡处理请求的能力范畴,之后随着请求数的增加,后面发送的请求开始排队阻塞,从而导致首字时延的累加。
最后测得的指标如下表所示:
可以看到在此案例下,平均首字时延高达27.689秒,会导致用户体验不佳,即使平均吞吐率有9 token/s。
但是在一分钟内处理100个requests,对于单卡的8B模型来说,还是会有请求超载的现象。

四卡NVIDIA RTX™ 5880 Ada运行Qwen3-32B
下面是Qwen3-32B在四卡上进行测试的结果:
第一个测试案例是60reqs/min,我们通过泊松分布发送请求的随机性来模仿多个用户在不同时间点使用的情况,发送请求的泊松分布如下所示:
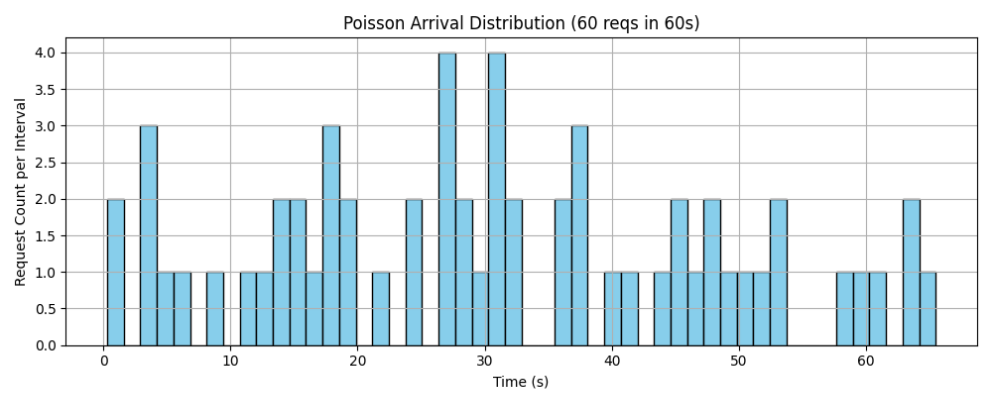
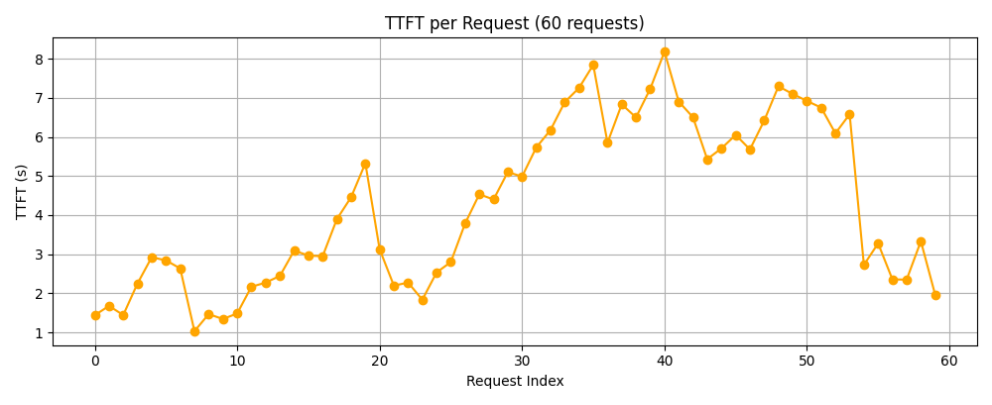
每个请求的首字时延如上图所示,可以看到,首字时延随着请求数的增加不断波动,这是由于当请求数量增加时,显卡由于未处理之前的线程导致后面线程排队阻塞,导致时延增加。
从泊松分布图也能看出来,前期出现多次高请求数的时间段,所以会有时延突增的现象;而随着之后请求数逐渐下降,当处理完之前的请求时,也会使得后面发送请求的首字时延减少。
下表是测得的具体指标:
可以看出60reqs/min在四卡的32B模型上表现不俗,平均每个请求的首字时延只有4.26秒,平均吞吐率也能达到8.85 token/s,对于用户在进行知识库检索问答时能获得较好的体验感。

第二个测试案例是100reqs/min。
同样的,我们通过泊松分布发送请求的随机性来模仿多个用户在不同时间点使用的情况,发送请求的泊松分布如下所示:
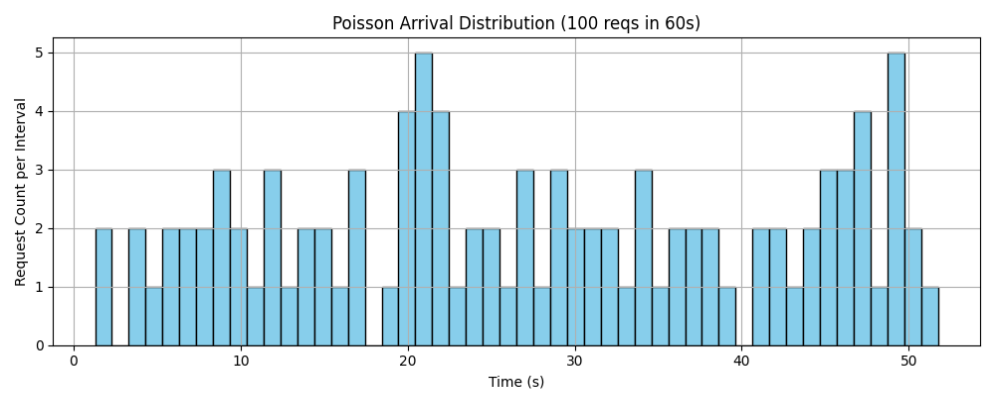
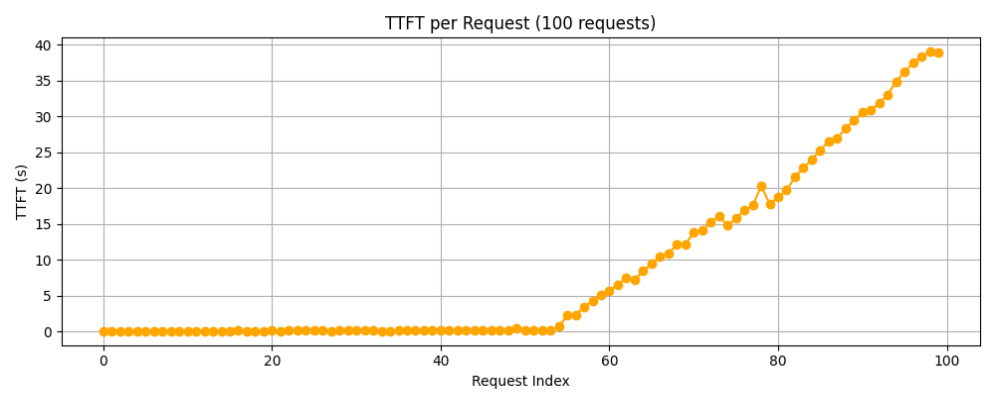
每个请求的首字时延如上图所示。
可以看到,首字时延随着请求数的增加不断增加,再通过第一个案例可以发现,当在60s内发送100个requests时,显卡已经有点过载了,才会导致首字时延的不断增加。
虽然平均首字时延仅有约8.7秒,但是在后期,性能会逐渐下降,超出用户可以接受的范畴。
下表是测得的具体指标:

所以我们得出一个结论,32B模型,在四卡NVIDIA RTX™ 5880 Ada的Dell Precision 7960机器上能够应对的处理次数,一分钟约为60次,即每小时大约3600次。
由于以上的几个大模型,都缺少图片的理解能力,为了补充这一缺失,我们日常工作中,还需要部署多模态大模型。
目前主流的多模态大模型,有Pixtral,MiniCPM,Qwen等几种,我们选择了广受好评的Qwen2.5-VL来做为测试的基准,原因是业界已经有许多团队基于Qwen2.5做了各种微调,用于满足不同的使用场景。
我们测试了两种模型尺寸,分别是Qwen2.5-VL7B以及32B,分别使用单卡和四卡进行测试。

为了与贴近真实情况,使用了三种测试用例,分别是分辨率为720p,1080p和4k的图片数据。
其中,我们是通过取100张COCO图片数据集,执行图片描述任务,我们获取了每次大模型对每一张图片进行分析时的指标,并取了平均值。
具体如下表所示,时延单位为秒,吞吐率单位为token/s。
Qwen2.5-VL-7B-Instruct模型使用的是单卡的NVIDIA RTX™ 5880 Ada,而Qwen2.5-VL-32B-Instruct这个模型使用的是四卡的NVIDIA RTX™ 5880 Ada。
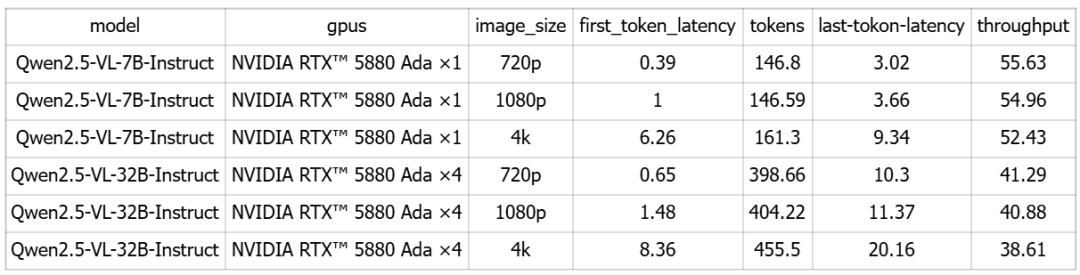
首先我们主要关注7B模型的平均首字时延和吞吐率。
在720p这种较低分辨率的图片下,首字时延只有0.39秒,而在4k超清画质的图片测试中,要高达6.26秒的时延。
除此之外,不同画质的吞吐率其实差别不大,所以如果想要获得较好的用户体验还是要尽量避免选用4k分辨率的图片进行大模型的识别。
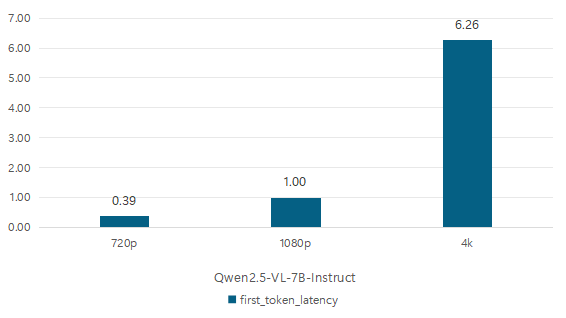
NVIDIA RTX™ 5880 Ada单卡测试数据
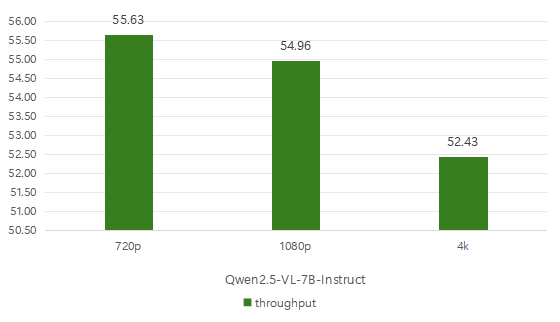
接着看一下32B模型的平均首字时延和吞吐率。
在720p这种较低分辨率的图片下,首字时延也只有0.65秒,而在4k超清画质的图片测试中,要高达8.36秒的时延。
除此之外,不同画质的吞吐率其实差别不大,如果想要获得更快的推理速度需要避免选择4k分辨率的图片进行大模型识别。
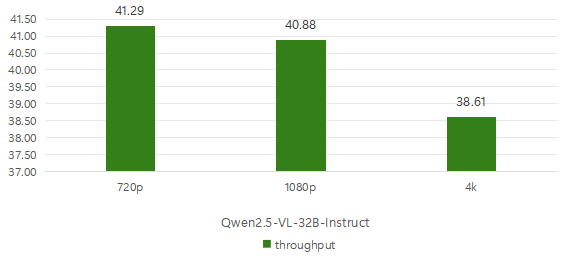
NVIDIA RTX™ 5880 Ada四卡测试数据
1. 对于知识库类的应用
我们建议使用单卡或双卡NVIDIA RTX™ 5880 Ada就可以了,因为知识库应用可以使用7B、8B的模型,这个配置对于部署7B、8B模型来说已经足够了。
使用8B模型,在保证体验的情况下,对于单卡及双卡的并发用户数,分别是20及40,考虑到用户随机访问的情况,每小时能处理的请求总量分别是3000、6000次。
2. 对于智能体类的应用
我们建议使用四卡NVIDIA RTX™ 5880 Ada的配置。
因为智能体会带来大量的思考过程以及工具调用,对于模型能力有一定的要求,所以建议使用32B模型。
而32B模型在四卡的配置上,能达到比较好的用户体验,特别是长上下文的情况下,四卡机能比双卡机带来3-4倍的并发用户数量支持。
同样,为了保证用户体验,四卡机32B模型的并发数量最好是控制在20左右,考虑到用户随机访问的情况,每小时能处理的请求总量约为7000次。
3. 设备表现出色
对于Dell Precision 7960的表现我们还是非常满意,不只是在性能方面能充分发挥大模型的能力。
同时,在测试过程中的噪音控制也是相当不错的,即使在四卡做大并发的使用场景下,其噪音分贝也仅有55分贝上下,对于日常办公没有噪音影响。而其他的测试案用例,则基本上察觉不到噪声。
(文:新智元)