


2025 年,AI 产业正在以一种前所未有的速度迭代向前,技术突破不断涌现,市场格局也在迅速发生变化。
Innovation Endeavors 合伙人 Davis Treybig 近期发布了一份 AI 产业深度报告《State of Foundation Models》(2025),报告从模型、技术、应用、智能体、市场、公司架构、未来机会七个维度出发,非常全面且深入地剖析了 AI 产业当下的发展现状及未来趋势,对 AI 产业的现状与未来趋势进行了全景式扫描,非常具备参考价值。
注:Innovation Endeavors 是一家专注于技术驱动型创业的早期风投基金,投资组合横跨生物技术、机器人、计算机视觉、金融科技等 AI 前沿领域。Davis Treybig 作为合伙人,主导了 Augment、Dosu、Capsule 等明星 AI 项目的投资。
TLDR:
-
AI不再是渐进式改良,而是生产力的代际跃迁。Cursor仅用一年达到近10亿美元年收入,创造了SaaS史上最快增长记录;25%的YC公司95%代码由AI生成;软件工程师坦言80%传统技能已贬值,但剩余20%核心能力被放大了10倍。
-
成功的AI应用已不再依赖单一模型。OpenAI内部一个复杂问题会被分解为20次不同的模型调用,通过多模型协作、任务分解、验证投票,系统性方法能将性能提升100%以上。
-
基础模型公司正被迫向应用层移动——OpenAI 73%收入来自ChatGPT订阅而非API,而Anthropic恰恰相反。这种战略分化背后,是对”纯模型API必将商品化”的深刻认知。
-
当数据收集成本降低1000倍,”数据即服务”将迎来前所未有的机遇:为AI智能体设计的新型基础设施(专属浏览器、支付系统、身份认证);”生成+验证”的闭环架构成为构建可靠AI的关键模式。
超 8000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

-
最新、最值得关注的 AI 新品资讯;
-
不定期赠送热门新品的邀请码、会员码;
-
最精准的AI产品曝光渠道
01
模型篇:
在成本、折旧与创新之间寻求平衡
在生成式AI指数级增长的背后,基础模型本身正经历着一场复杂而剧烈的演变。其发展轨迹充满了矛盾:训练成本屡创新高,而模型的生命周期却急剧缩短;对更大参数规模的盲目追求正在退潮,取而代之的是对计算效率和推理能力的深度挖掘。
前沿模型的经济学悖论:高昂成本与极速折旧
构建最先进的基础模型,正在成为一场资本和算力的豪赌。数据显示,前沿模型的训练成本正以惊人的速度膨胀。2020年,训练GPT-3的成本约为450万美元;而到了2025年,训练Llama 4的成本预计将超过3亿美元。在短短五年内,顶尖模型的入场券价格上涨了近两个数量级。
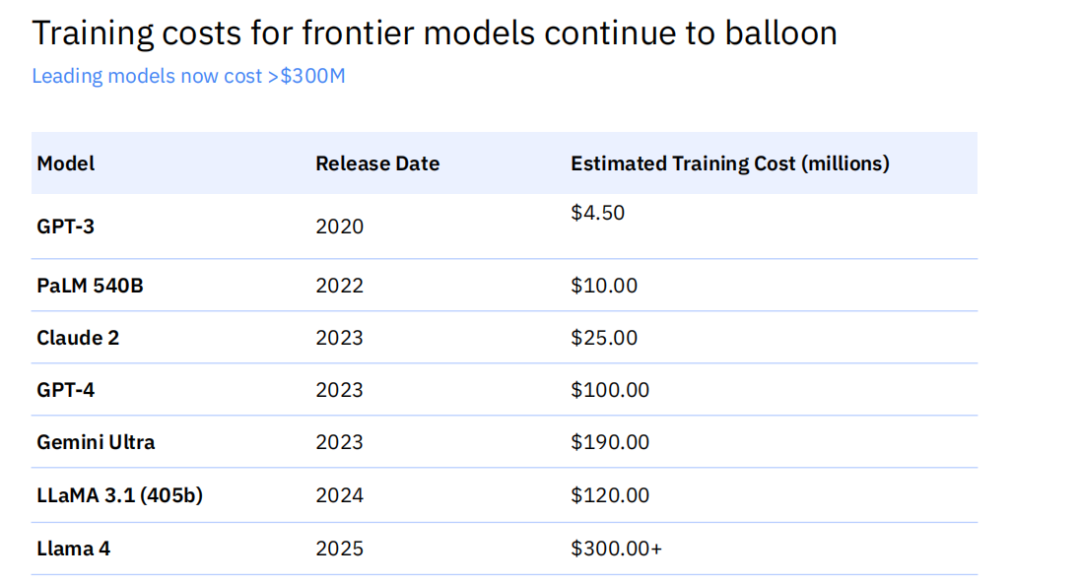
然而,这种巨大的投入面临着一个严峻的现实:极速的价值折旧。一个斥巨资训练的闭源前沿模型,其领先地位可能在6到12个月内就被颠覆。一个典型的例子是,2023年发布的GPT-4训练成本超过1亿美元,但仅在一年后,一个训练成本不足1000万美元的开源模型DeepSeek-VL,就能在多个关键视觉语言基准测试中取得与之相当甚至超越的性能。
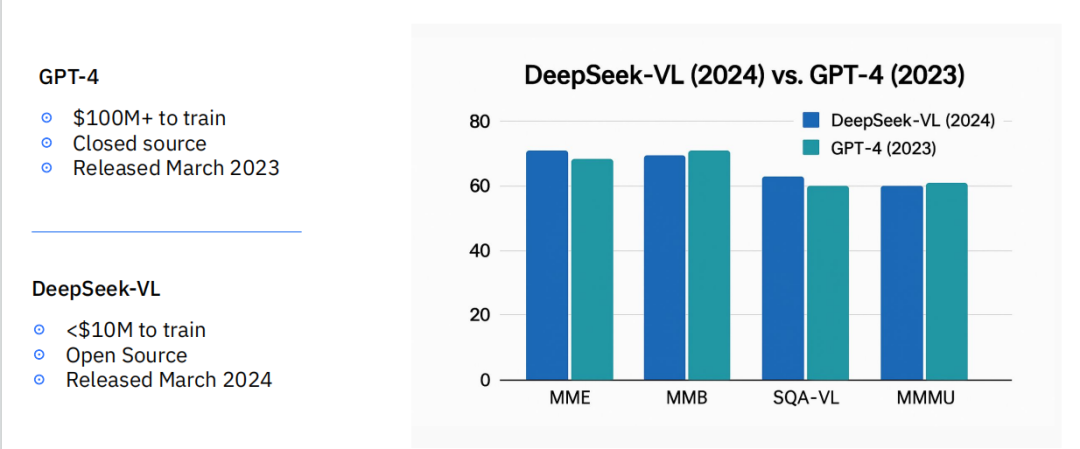
这种现象的背后,是开源模型与闭源模型之间性能差距的迅速收敛。在Meta、Mistral、阿里巴巴等科技巨头的推动下,高质量的开源模型层出不穷,持续追赶甚至在部分指标上超越了同期的闭源对手。迭代速度的极致体现是,根据OpenRouter等平台的追踪数据,一个新模型能在排行榜前五名保持领先的中位数时间仅为3周。这种“你方唱罢我登场”的快速更迭,使得任何单一模型的长期技术壁垒都变得极不稳定。

除了计算成本,数据成本同样惊人。Deepmind每年在数据标注上的花费高达10亿美元,而Meta为Llama 3的后训练数据投入了1.25亿美元。对于高质量的推理数据,OpenAI甚至愿意为单条推理轨迹支付2000至3000美元。计算和数据这两项巨额开支的边界日益模糊,共同构成了模型开发中令人望而却步的成本结构。
超越参数规模:推理计算与新尺度定律的兴起
长期以来,单纯扩大模型参数量被视为提升能力的核心路径,但这一趋势正在逆转。数据显示,在2023年GPT-4达到一个参数量高峰后,后续发布的新一代顶尖模型如Claude 3.5 Sonnet和Llama 3等,其参数规模反而有所下降。业界开始意识到,模型的效率和智能并非仅由参数量决定。
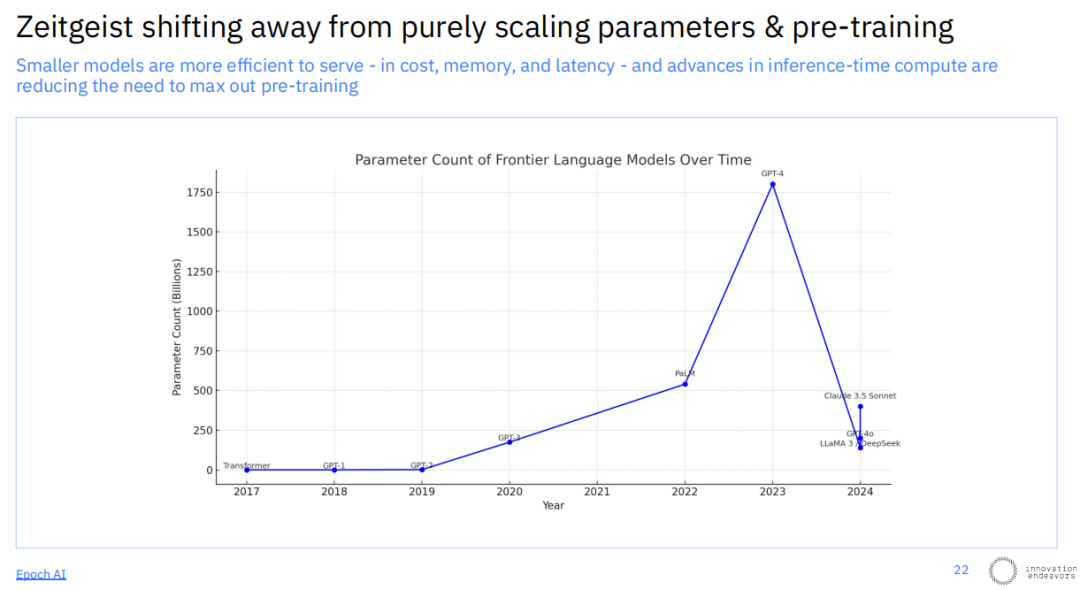
一种新的权衡范式正在形成:用更海量的数据(远超“计算最优”配比的tokens)来训练一个参数量较小的模型,虽然在训练阶段效率较低,但在推理(即实际使用)时,这样的模型更容易部署、运行成本更低、延迟也更小,从而在应用层面具备显著优势。
这一转变的深层原因在于,预训练的传统路径正逼近其物理极限。正如Ilya Sutskever所指出的,高质量的互联网数据是有限的,堪称“人工智能的化石燃料”。当数据无法同步增长时,单纯依靠硬件和集群规模的扩张将难以为继。因此,业界不得不寻找新的能力增长点,而推理时间计算(Inference time compute)正成为新的前沿。
其核心思想是,让模型在输出最终答案前,花费更多的时间进行内部的“思考”和“推理”。这种“慢思考”允许模型构建更复杂的逻辑链条,从而提升回答的质量和准确性。
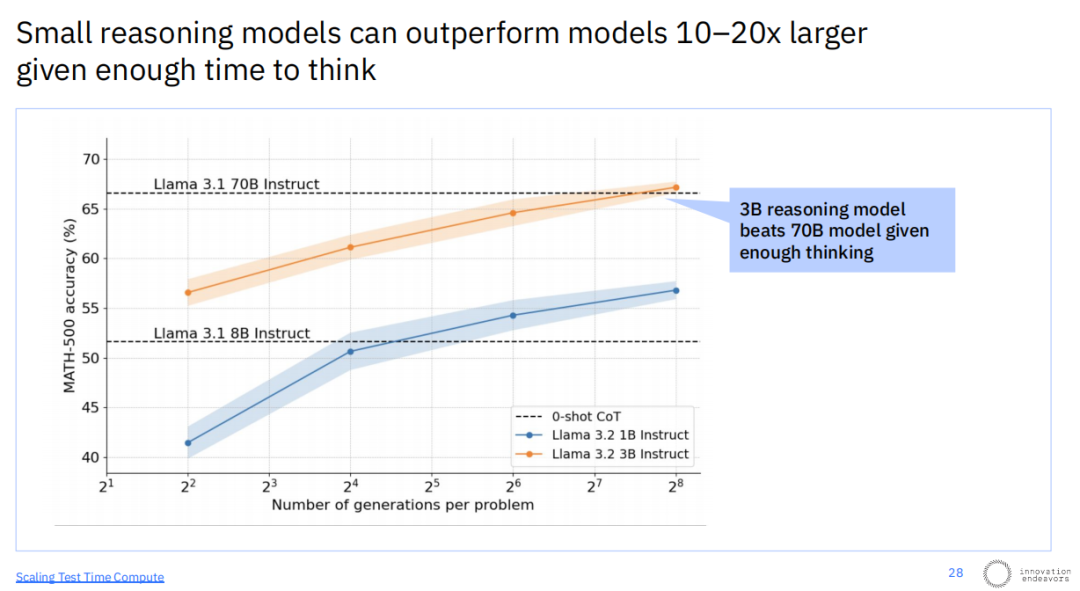
研究表明,这代表了一种新的尺度定律:增加测试时的计算量,同样能带来模型准确率的稳步提升。一个惊人的结果是,一个30亿参数的推理模型,在给予足够“思考时间”后,其数学能力可以超越一个不做深度思考的700亿参数的大模型。这证明了“思考”本身,而非单纯的模型尺寸,正成为解锁更高智能的关键。
后训练革命:构建更强推理能力的方法论
为了实现更强的推理能力,模型的训练方法论也在快速演进,重心正从预训练转向后训练(Post-training)阶段。目前主要有两种发展路径:一是通过在大量的“推理轨迹”上进行后训练,直接教会模型如何思考;二是利用“搜索”技术,在推理时指导模型的思考过程。例如,通过“Best-of-N”或“树状搜索”等技术,让模型生成多个候选答案或推理路径,再由一个验证器(Verifier)或奖励模型(Reward Model)来挑选出最佳结果。
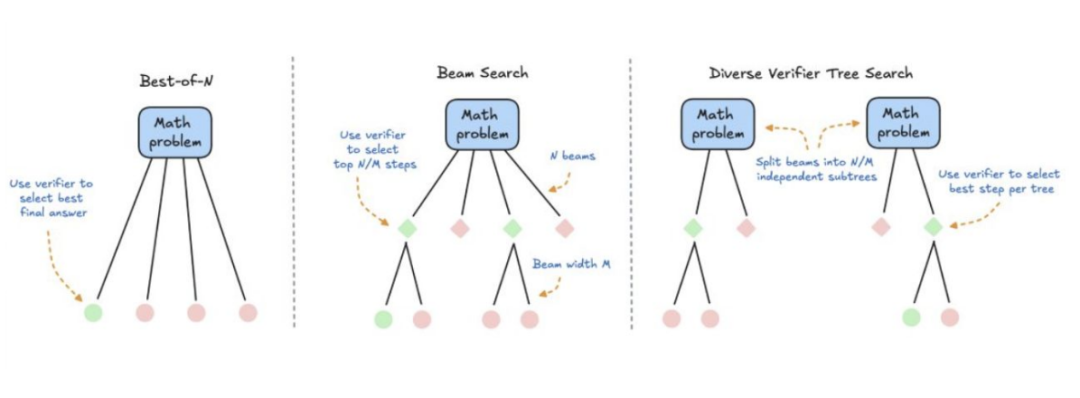
验证器和奖励模型因此变得至关重要。它们可分为两类:一类是程序化验证器,如用于代码生成的编译器和单元测试,这类验证器准确但泛化能力差;另一类是学习型验证器,通过学习人类偏好来评估输出的质量。构建一个能理解复杂、通用人类价值观的通用奖励模型(Generalist Reward Model),被认为是该领域的“圣杯”,但其开发难度极大。同时,后训练的优化算法也在不断迭代,从PPO发展到DPO,再到结合了奖励模型的GRPO,整个技术栈日益复杂和精细。
演进中的模型架构:从混合专家到多模态
在模型架构层面,多个趋势正在走向成熟:
-
混合专家模型(Mixture-of-Experts, MoE)日益普及。如DeepSeek、Mistral以及传闻中的GPT-4,都采用了这种架构。它通过一个路由器将输入导向不同的“专家”子网络,只激活部分参数,从而在保持巨大模型容量的同时,显著降低了单次推理的计算成本。
-
上下文窗口急剧增长,部分模型已宣称支持千万级token的上下文。但用户需警惕“虚假宣传”,在“大海捞针”测试中评估模型在超长文本中的真实信息提取能力。
-
多模态能力持续进步。模型已能熟练地处理图文混合输入。然而,能够无缝理解和生成文本、图像、音频、视频等多种模态的全能模型(Omni-modal models)仍处于非常早期的研究阶段。
-
Tokenization(分词)作为当前模型的一个基础环节,依然是一个“顽固的‘变通’方案”,是导致模型拼写错误、算术不佳、难以处理某些语言等诸多问题的根源。直接在字节(bytes)层面进行建模的Transformer架构,可能是解决这一问题的潜在方向。
跨越边界:AI在多模态与科学领域的渗透
基础模型的概念正被应用到越来越广泛的领域。视频模型正迎来其“ChatGPT时刻”,生成质量和可控性大幅提升。在机器人技术领域,通用模型已能让机器人在前所未见的环境中执行新任务。世界模型(World models)则致力于模拟环境中的动态变化,为机器人训练乃至交互式娱乐体验提供基础。
在更专业的科学领域,基础模型的应用也方兴未艾。以自监督方式在基因组序列上训练的DNA基础模型,有望用于突变效应预测和基因组设计。除此之外,从蛋白质设计(Generate:Chroma)、药物动力学预测(Iambic)到材料科学(Orbital),AI模型正在成为科学发现的新引擎。然而,这些专业领域面临的最大瓶颈是高质量数据的稀缺,这限制了其市场成熟度和应用广度。
02
指数时代:
从技术突破到全面爆发
两大技术突破:解锁规模化的钥匙
当前这轮AI技术浪潮的爆发,并非偶然,而是源于两个关键的技术突破,它们分别解决了数据和计算的规模化瓶颈。
第一个突破是自监督学习(Self-Supervised Learning)。该方法允许模型从海量未标注的数据中自行学习。传统监督学习需要昂贵的人工标注数据(例如,将图片标记为“猫”或“狗”),而自监督学习通过巧妙设计的任务,让模型从数据自身寻找监督信号。例如,模型可以被训练来预测一句话中被遮盖的词语,或者根据前半句话补全后半句。通过这种方式,互联网上浩如烟海的文本、代码和图像都成为了可用的训练材料,从根本上解决了数据供给的规模化问题。
第二个突破是注意力架构(Attention Architecture),其最知名的实现即“Transformer”模型。这一架构革命性地提升了计算效率和模型对上下文的理解能力。在Transformer出现之前,处理长序列数据(如长篇文章)的模型效率低下且难以并行计算。注意力机制则允许模型在处理每个词语时,都能同时“关注”到输入序列中的所有其他词语,并动态评估它们的重要性。这不仅使模型能够精准捕捉长距离的语义依赖,更关键的是,其计算过程高度可并行化,完美契合现代GPU等并行计算硬件的特性,从而为模型规模的急剧扩张铺平了道路。
从量变到质变:“涌现”与指数级扩张
当模型在数据和计算两个维度上实现规模化后,一个关键的现象出现了——“涌现”能力(Emergent Behavior)。研究表明,当模型规模(以训练所用的计算量,即FLOPs衡量)达到某个临界点后,其在特定任务上的性能会突然从接近随机猜测的水平,跃升至具备相当高的准确率。这在模块化算术、多任务自然语言理解等领域尤为明显。这种非线性的性能飞跃意味着,单纯地扩大模型规模,就能解锁前所未有的新能力。
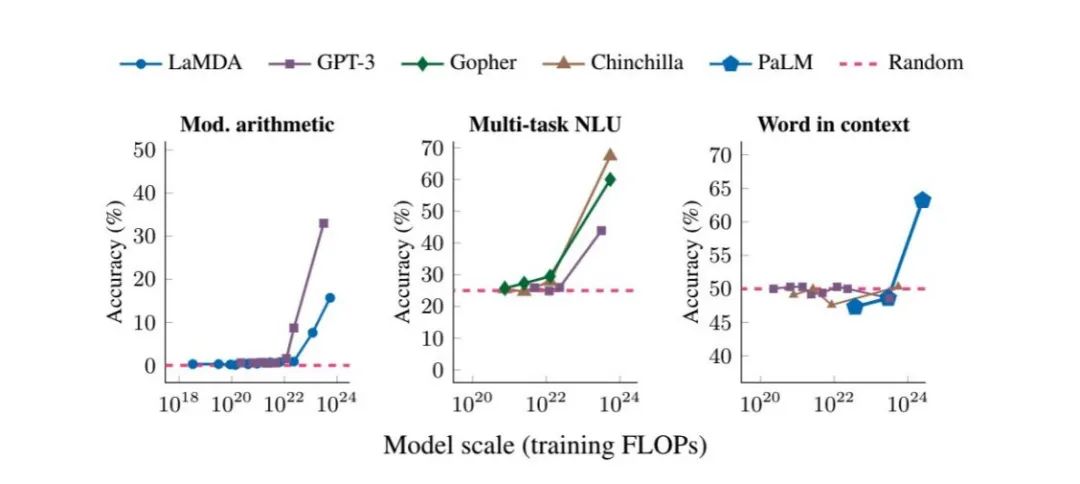
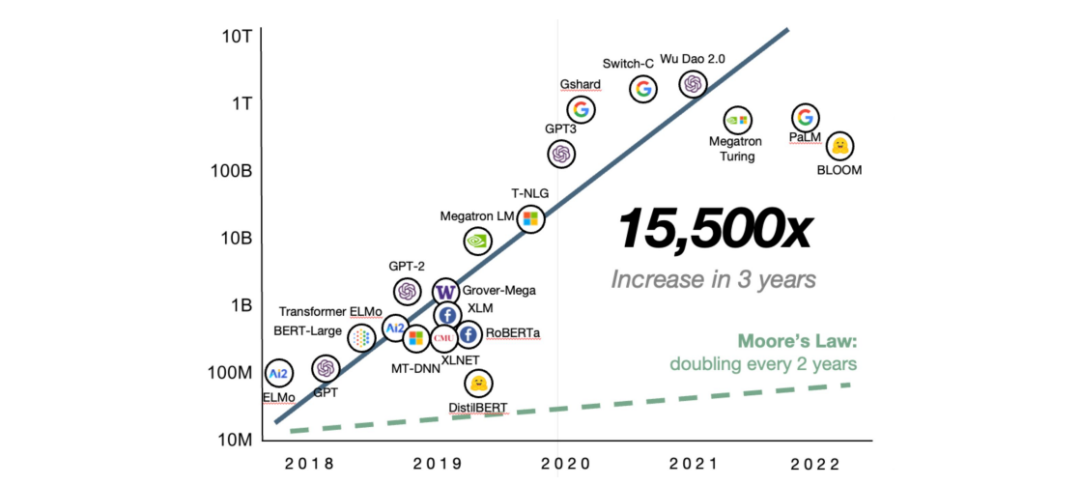
这一发现直接催生了业界对模型规模的极致追求。在2018年至2022年的短短几年间,顶尖语言模型的参数量实现了爆炸式增长,从千万级(如ELMo)一路飙升至万亿级(如Switch-C)。其增长速度达到了惊人的三年15,500倍,将遵循“每两年翻一番”规律的摩尔定律远远甩在身后。
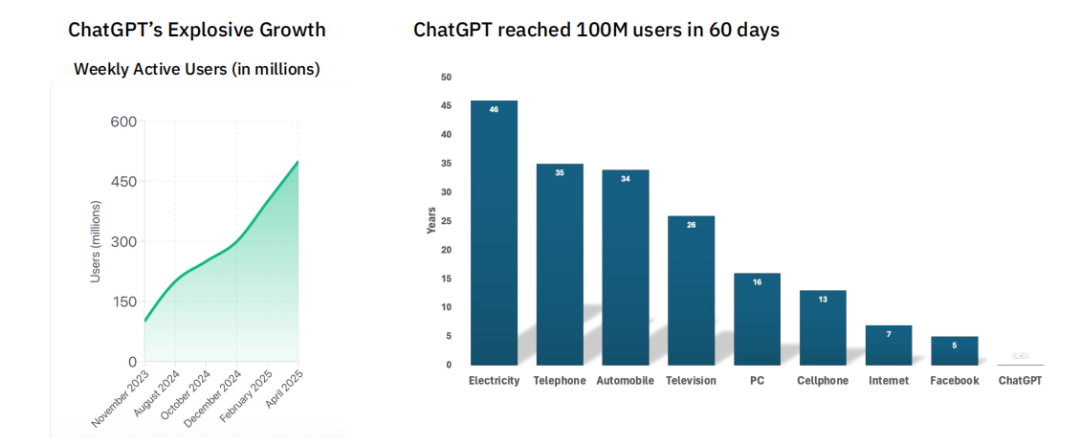
市场印证:空前的采纳速度与商业化效率
技术上的指数级进步迅速转化为市场上的现象级成功。ChatGPT的问世,创造了人类科技史上最快的用户增长记录。它仅用60天时间就吸引了1亿用户,相比之下,互联网达到同样规模用了7年,Facebook用了近5年。这一数据清晰地表明,生成式AI满足了真实而广泛的用户需求。
与用户增长同样迅猛的,是其商业化变现的速度。一批AI原生应用在极短时间内就实现了惊人的收入规模。例如,GitHub Copilot在三年内达到约4亿美元的年化收入;Midjourney用两年时间、约40名员工的团队,创造了约2亿美元的年化收入;而更年轻的Cursor仅用一年时间、约20名员工,就实现了约1亿美元的年-化收入。这些案例共同指向一个事实:AI应用正以极高的资本效率和极精简的团队结构,创造着前所未有的商业价值。
全面加速:技术指标与模型能力的持续跃升
这股指数级增长的势头,正贯穿于基础模型技术的所有核心指标。从2023年初到2025年春季,模型的上下文窗口(即一次性处理信息量的上限)从数千个token扩展至约100万个token,增幅高达100-500倍。达到GPT-4级别模型的训练成本预计将从1亿美元降低至10万美元,实现了超过1000倍的成本缩减。同时,训练模型所需的总计算量也增长了超过1000倍,反映出业界仍在坚定地投入算力以换取更强的模型能力。
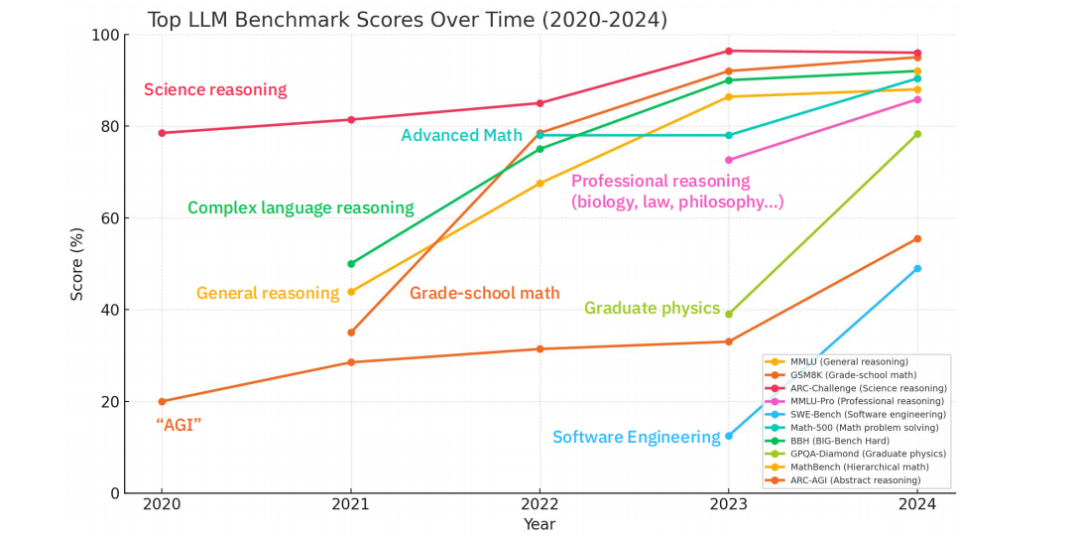
性能的提升同样直观。在各项学术和专业基准测试中,大型语言模型(LLM)的得分曲线持续陡峭上扬,在2024年已在科学推理、高级数学、软件工程等多个领域接近甚至超越了人类顶尖水平。
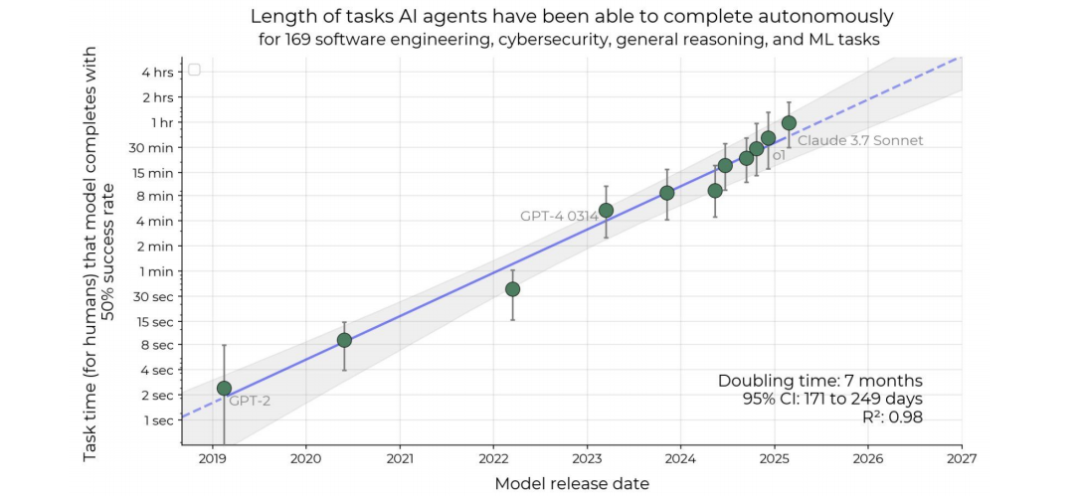
更具实际意义的是,AI能够自主完成任务的时间跨度也实现了指数级飞跃。在短短五年内,AI智能体能够稳定完成的任务时长从1秒钟跃升至1小时以上,其能力倍增周期仅为7个月。这意味着AI正从一个只能执行瞬时指令的工具,演变为能够处理复杂、长期任务的可靠助手。
在特定专业领域,LLM的能力已经开始超越人类专家。例如,在多项综合诊断任务中,AI模型已展现出比人类医生更高的准确性。在解决国际数学奥林匹克(IMO)级别的复杂几何问题上,AI的准确率已超过地球上99.999%的人口。这种超越不仅局限于文本和逻辑推理,在图像生成领域,扩散模型(Diffusion Models)同样在两年内实现了从略带卡通感的生成(如2022年的Imagen)到照片级逼真度(如2024年的Visual Electric)的巨大飞跃,展现了其在多模态能力上的同步进化。
03
用例与应用:
AI对知识工作的全面重塑
随着基础模型能力的指数级增长,其应用范围正以前所未有的深度和广度渗透到各个行业。从重塑信息获取方式,到颠覆软件工程的全生命周期,再到为所有高技能知识工作者配备Copilot,生成式AI正从根本上改变价值创造的方式。
核心应用:从通用搜索到垂直领域的“信息中枢”
搜索与信息综合至今仍是大型语言模型(LLM)最核心、最具标志性的应用场景。这一需求催生了两类产品形态。一类是通用型搜索与问答引擎,如Glean、Perplexity和Bench,它们致力于为用户提供一个能回答任何问题的统一入口,直接挑战传统搜索引擎的地位。
另一类则是数量更为庞大的垂直领域专用解决方案。据估计,已有超过1000家初创公司围绕这一模式找到了产品市场契合点(Product-Market Fit)。这些公司将LLM的理解和综合能力应用于特定行业,打造专用的“信息中枢”。
例如,AlphaSense和Tetrix服务于投资领域,Harvey专注于法律行业,Trunk Tools面向建筑业,而OpenEvidence则深耕医疗健康领域。这种垂直化策略通过整合行业特有数据和工作流,提供了远超通用工具的价值,形成了一个繁荣的创业生态。

颠覆性影响:软件工程迎来范式革命
软件工程是迄今为止受到AI冲击最为深刻的领域。在短短两到三年内,软件工程Copilots(SWE Copilots)已经发展成为一个年收入规模近20亿美元的庞大市场。其中的明星产品Cursor,更是创造了软件即服务(SaaS)领域有史以来最快的增长记录,年化收入已接近10亿美元。
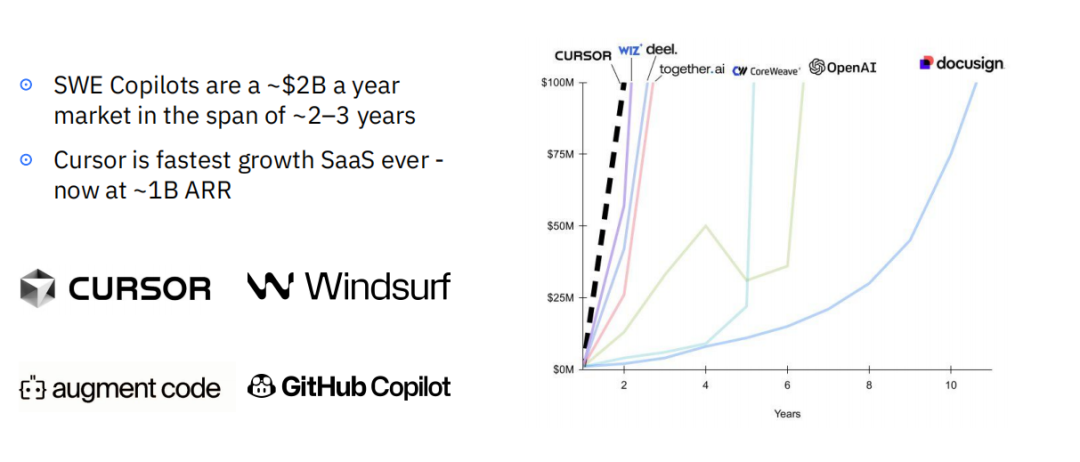
AI代码生成工具的影响力已经不容忽视。根据YC创始人Garry Tan的观察,在其2025年冬季批次的创业公司中,有25%的公司其代码库中95%的行数是由LLM生成的。这标志着一个“氛围编程”(vibe coding)时代的到来,开发者只需描述意图,即可由AI完成大量具体的编码工作。
资深工程师甚至表示,在体验过Cursor这类工具后,他们过往80%的技术技能价值骤降,而剩余20%的架构设计和系统思考等核心能力的杠杆效应则被放大了至少10倍。
AI的影响力已经贯穿了整个软件开发生命周期(SDLC)。从代码审查(Graphite)、文档撰写(Dosu)、代码迁移(Mechanical Orchard),到原型设计(Lovable)、测试与QA(Ranger),几乎每个环节都在被AI重塑。
这预示着未来所有开发者工具类的产品,都必须在一个以AI代码生成为默认选项的世界里重新思考自身定位。更进一步,以All Hands和Replit为代表的自主软件工程(Autonomous SWE)工具,正朝着完全自动化的方向探索,试图将开发者从繁琐的实现细节中彻底解放出来。

全面渗透:为所有高技能专业人士配备AI副驾驶
软件工程领域的成功模式正在被快速复制到所有需要专业知识和高度技能的职业中。一个清晰的趋势是,针对不同专业人士的AI copilot和智能体正在大量涌现,旨在增强其生产力、自动化重复性工作。
这个新兴的应用矩阵覆盖了从硬件到创意,从工程到金融的广泛领域。

与此同时,所有形式的创意表达也正在被AI彻底重塑。
未来趋势:从专业辅助到个人生活的全面整合
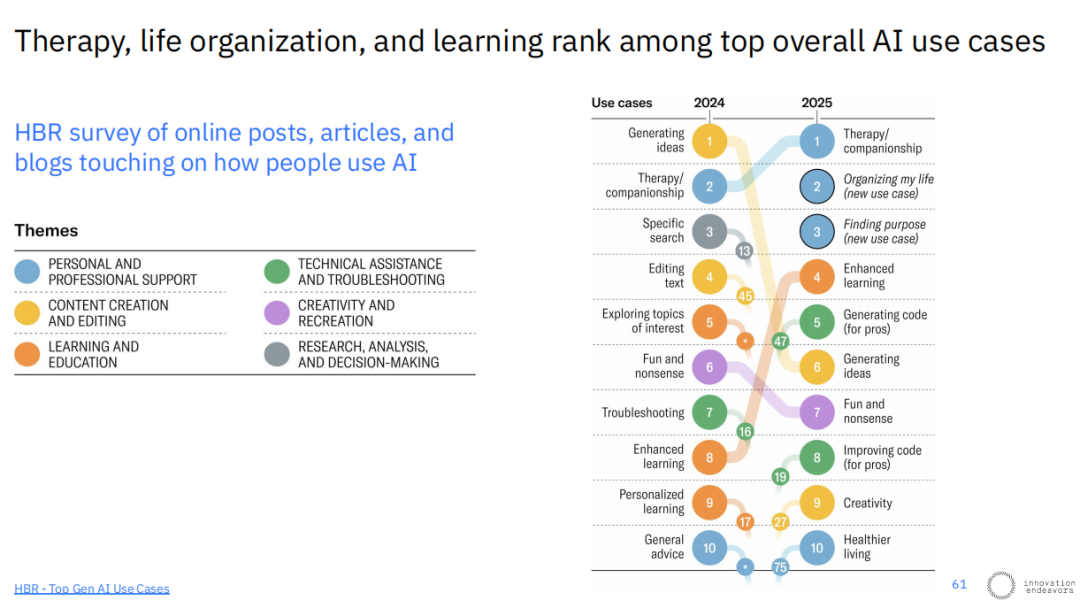
除了在专业领域的应用,AI也正日益融入人们的个人生活。根据哈佛商业评论对用户使用模式的调查,AI的核心用例正在发生演变。
在2024年,“生成想法”是首要用例,而到了2025年,“治疗/陪伴”和“组织我的生活”跃升为前两大需求。这表明用户正从将AI视为一个纯粹的生产力工具,转向将其看作一个能够提供情感支持和个人管理辅助的伙伴。
这一趋势与AI在教育、教练和陪伴领域的应用兴起相吻合。同时,AI的用例也变得更加多样化,包括垂直领域的写作(Gale)、语言学习(Speak)、语音智能体(FerryHealth)以及处理非结构化数据的“记录系统”(Clarify)等。AI正在从一个解决特定任务的工具,演变为一个深度整合进个人与职业生活方方面面的基础设施。
04
智能体崛起:
构建下一代AI应用的模式与挑战
基于大型语言模型(LLM)的应用正在经历一次意义深远的成熟过程,其演进路径清晰地展示了从单一功能到复杂系统的转变。最初的应用,如早期的Notion AI,主要依赖模型本身的核心能力进行文本生成或摘要。
随后,我们看到了检索增强生成(RAG)技术的兴起,以GitHub Copilot为例,它将模型与特定的数据集相结合,通过检索相关代码或文档来提供更精准、更具上下文的辅助。
如今,我们正迈入一个新的阶段:智能体(Agents)。以Deep Research等新兴应用为代表,它们不仅整合了模型和数据,还赋予了模型使用工具(Tools)的能力,标志着AI应用正在从被动的响应者转变为主动的任务执行者。
解构智能体:循环、工具与复杂任务
智能体的核心机制可以被理解为一个在环境中利用工具循环作业的模型。这个过程始于人类的指令,大型语言模型(LLM)接收指令后,并非直接生成最终答案,而是规划出需要执行的动作(Action)并调用相应的工具。
这些工具可以是文件系统搜索、代码编写与执行、API调用,甚至是模拟人类浏览网页的行为。模型通过工具与外部环境(Environment)进行交互,获取执行结果或新的信息作为反馈(Feedback)。
这个反馈会再次输入模型,帮助其进行下一步的判断和规划,形成一个“规划-执行-反馈”的闭环。这个循环会持续进行,直到任务完成或达到预设的停止条件。
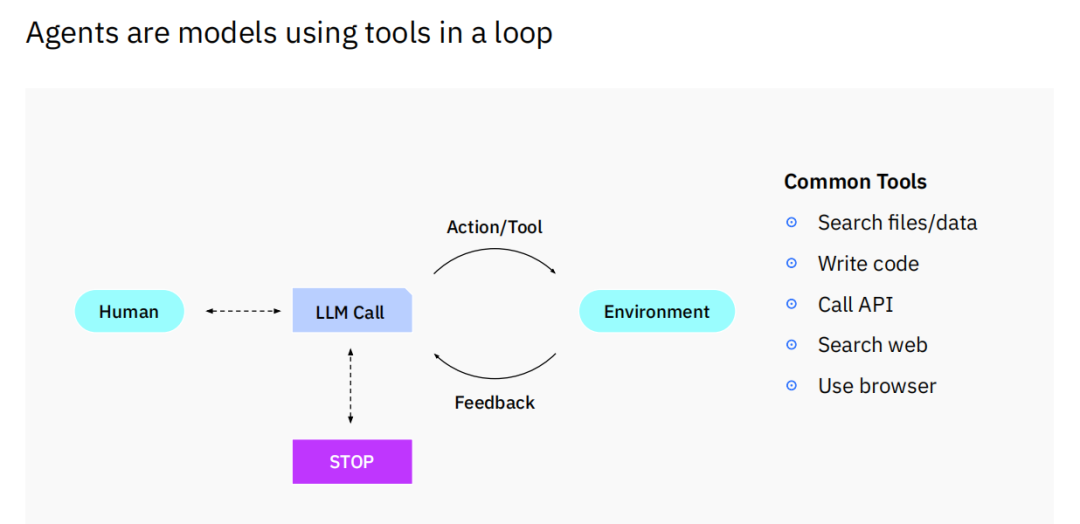
这种循环作业的模式赋予了智能体处理高度复杂任务的能力。一些领先的智能体初创公司的产品,在处理一个看似简单的用户请求时,内部可能会发生极其复杂的连锁反应。

这种多步骤、递归式的任务处理能力,是智能体与传统LLM应用最根本的区别。
专才的胜利:通用智能体为何尚未到来
尽管智能体技术前景广阔,但市场现实表明,通用型智能体(Generalist agents)的商业化道路依然充满挑战。一些尝试构建能够处理用户日常生活中各种任务的通用智能体的初创公司,尽管在技术上实现了相似的能力,却始终难以找到稳定的用户需求和产品市场契合点,最终走向沉寂。
Alex Graveley关于其ai_minion项目停运的分享便是一个例证,他提到尽管产品能力与备受关注的OpenAI Operator类似,但并未获得市场认可。
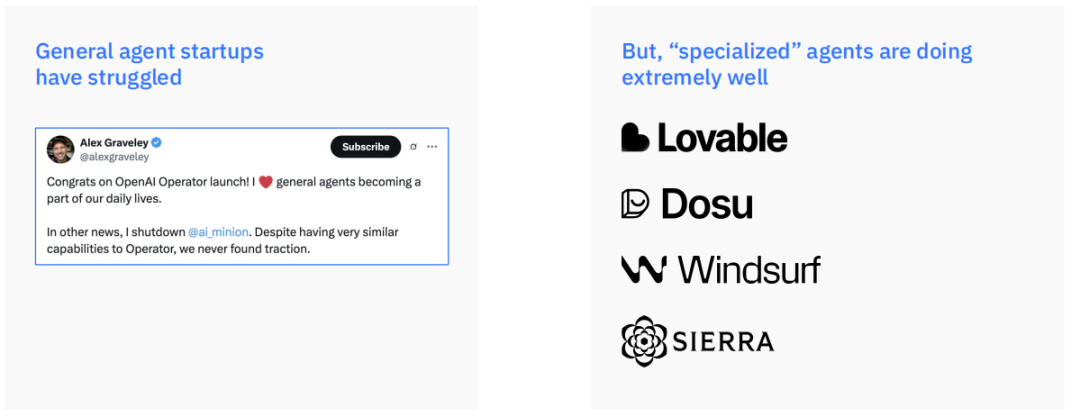
与此形成鲜明对比的是,那些专注于特定领域的“特化”智能体(Specialized agents)却表现得异常出色。诸如Lovable、Dosu、Windsurf和Sierra等公司,通过将智能体技术应用于特定、明确的业务场景,获得了强大的产品市场契得。
它们的成功说明,在当前阶段,智能体的价值并不在于其能力的广度,而在于其在特定垂直领域内解决实际问题的深度和可靠性。用户更倾向于为能稳定解决某个具体痛点的工具付费,而不是一个功能强大但行为不可预测的通用助手。
成功的关键:期望管理与产品设计
智能体产品的成功与否,很大程度上取决于用户期望的管理。以备受争议的AI软件工程师Devin为例,社区对其评价呈现出两极分化。一部分用户在体验后认为“它很少能真正起作用”,而另一部分用户则称赞其为“公司里最有生产力的工程师”。
这种差异的根源,并不仅仅在于产品本身,更在于用户是否投入时间去学习如何与智能体有效协作。学习使用智能体本身就是一项技能。成功的团队懂得如何引导用户建立合理的期望。
这种期望管理最终需要通过细致的产品设计来实现。成功的智能体产品在三个关键层面找到了平衡。首先是在人机协作的平衡上,产品需要明确自身是全自动执行还是需要人类监督,并提供诸如“智能体收件箱”(Agent Inbox)这样的审核与管理工作流。更重要的是,产品必须清晰地告知用户应该在何时、何地使用它,以及更重要的,何时何地不应该使用它。
其次是明智的用例选择。成功的智能体往往切入那些现有工作流中失败率或错误率较高的环节,或者作为“第一遍”审查工具,用于在早期发现问题。在这些场景下,覆盖更多检查点的重要性超过了单点上绝对的正确性,并且任务本身的试错风险较低。
最后,在产品与设计层面,智能体必须能够“展示其工作过程”,让用户理解其决策路径,从而建立信任。同时,内置的修正机制,如编辑、撤销、重做等,是必不可少的,它赋予了用户最终的控制权。通过最小化用户的认知负荷和针对特定工作流进行设计,才能将一个强大的技术模型,转化为一个用户真正愿意信赖和使用的产品。
超越单一模型:系统性思维的崛起
成功的AI产品团队往往不再将大型语言模型(LLM)视为一个单一的、万能的黑箱。相反,他们更多地从“系统”的视角来构建解决方案。
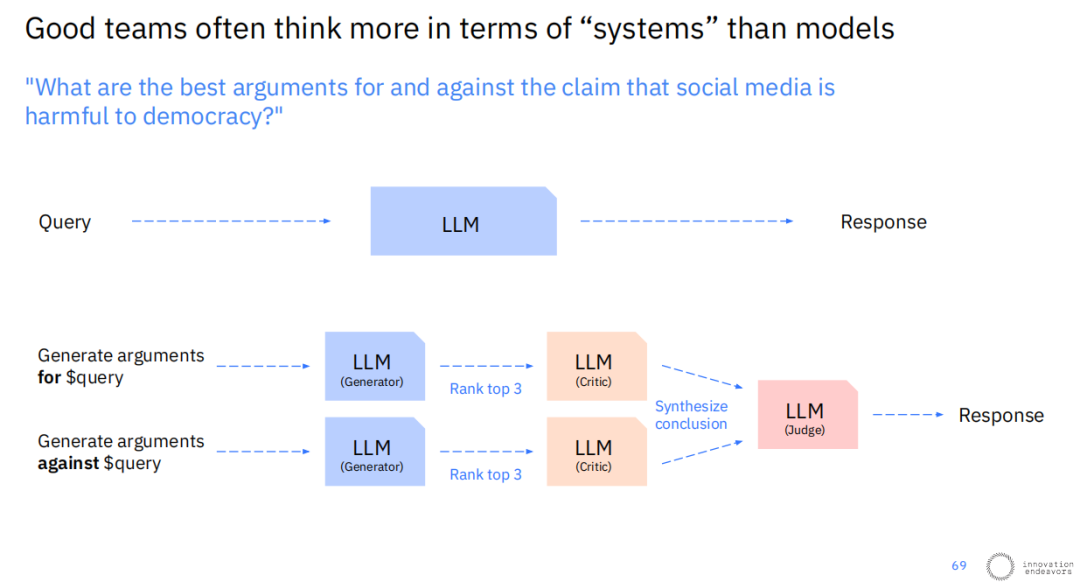
这种思维方式的转变,是应对复杂和开放式问题的关键。例如,当面对一个需要辩证分析的问题,如“社交媒体对民主有害的最佳论据和反对论据是什么?”,一个简单的、直接向LLM提问并获取回答的流程,其结果的深度和可靠性往往有限。
一个系统性的方法则会截然不同。它会将这个复杂问题分解为多个独立的子任务。系统可能会首先并行调用两个LLM实例(生成器),一个专门生成支持该主张的论据,另一个则生成反对该主张的论据。随后,系统会再调用两个LLM实例(批判家),分别对正反两方的论据进行评估和筛选,各自选出排名最高的几个论点。
最后,一个更高阶的LLM实例(裁判)会将这些经过筛选的、高质量的正反论据进行综合,形成一个结构化、逻辑严密且观点平衡的最终回答。这种多步骤、多角色的协作流程,其产出质量远非单次调用所能比拟。
OpenAI的首席产品官Kevin Weil也证实了这种趋势,他提到在公司内部,模型集成(ensembles of models)的使用远比外界想象的要普遍。一个复杂问题可能会被拆解成10个不同的子问题,并动用20次不同的模型调用来解决。
这其中可能混合使用了针对不同任务微调的特化模型,也可能因为延迟或成本的考量而选用了不同规模的模型。每一个调用都可能配有为其量身定制的提示词(prompt)。其核心思想,正是将一个宏大、模糊的高阶任务,分解为一系列具体、可控的低阶任务集合。
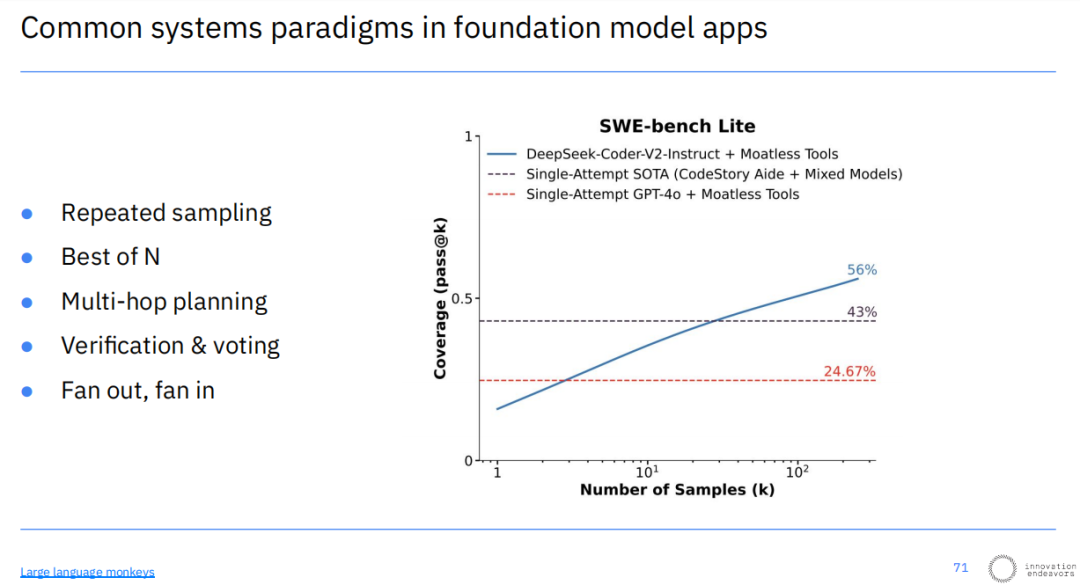
这种系统范式催生了许多具体的实现技术,例如通过多次采样生成多个候选答案,然后从中选出最优的“Best of N”方案;通过多步规划(Multi-hop planning)来解决需要长程推理的问题;以及利用验证和投票机制来提升结果的准确性。
在一项针对软件工程任务的基准测试(SWE-bench Lite)中,采用多样本方法的系统(DeepSeek-Coder-V2-Instruct)其问题解决覆盖率达到了56%,显著高于仅依赖单次尝试的先进模型(43%),更是远超单次尝试的GPT-4o(24.67%)。这充分证明了系统性方法在提升AI能力上限方面的巨大潜力。
随着这些系统变得日益复杂,手动搭建和调优的难度也越来越大。因此,更高层次的编程框架应运而生,旨在将开发者从繁琐的手动调优中解放出来。
像DSPy和Ember这样的框架,允许开发者以声明式的方式定义AI系统的逻辑流程,而框架本身则能自动优化底层的提示词、模型选择和执行策略,这预示着AI系统构建正在走向自动化和工程化。

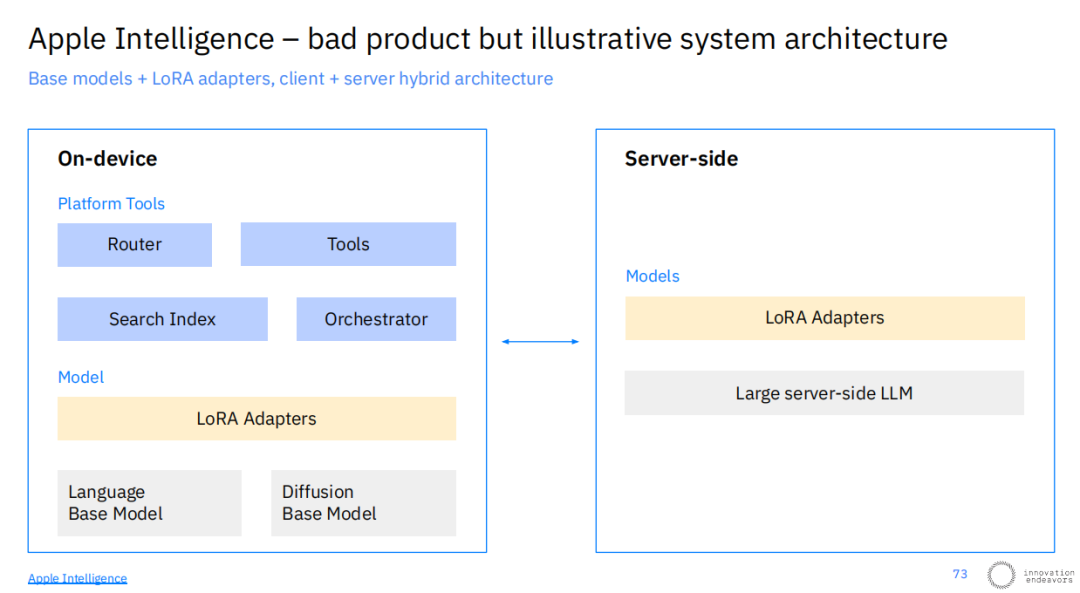
苹果公司发布的Apple Intelligence便是这种复杂系统架构在消费级产品中的一个极佳例证。其系统设计横跨设备端和服务器端。在设备端,一个复杂的“大脑”包含路由器(决定任务在端侧还是云端处理)、工具集、搜索索引和任务编排器。同时,设备上还运行着相对较小的基础语言模型和扩散模型,并通过LoRA适配器进行轻量化定制。
当任务超出端侧能力时,请求会被安全地发送到服务器端,由更强大的大型语言模型处理。这种混合架构,正是为了在保护隐私、降低延迟和利用强大云端算力之间取得平衡,它本身就是一个精心设计的AI系统。
检索的持久战:为何RAG依然是核心
尽管模型的上下文窗口在不断扩大,但检索增强生成(RAG)技术在可预见的未来仍将是构建高质量AI应用的核心组件。对于大多数非简单的应用场景,RAG在质量、成本和延迟方面均以数量级的优势胜过单纯依赖长上下文窗口的模型。
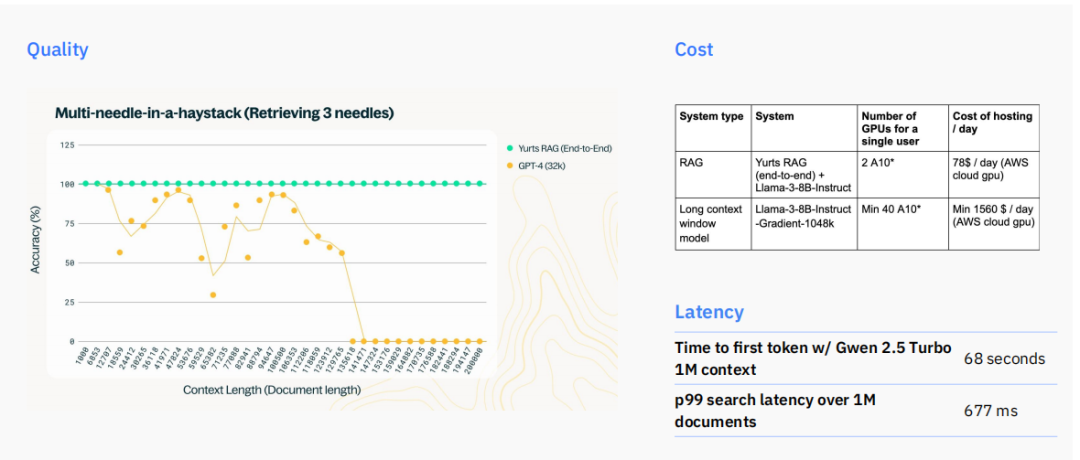
在质量方面,一项“大海捞针”测试显示,当需要从海量信息中精确检索并利用3个关键信息点时,基于RAG的系统(Yurts RAG)能够持续保持近乎100%的准确率。相比之下,即使是拥有超长上下文能力的GPT-4(32k),其准确率也会随着上下文长度的增加而剧烈波动,甚至出现显著下降。
在成本和延迟方面,差距同样明显。运行一个RAG系统,单个用户每天的托管成本可能仅为78美元,而一个依赖Llama-3-8B长上下文模型的系统,成本则至少为1560美元/天。
在响应速度上,使用Gwen 2.5 Turbo模型处理1M token的上下文,生成第一个词元需要长达68秒,而在超过100万份文档中进行p99搜索延迟仅为677毫秒。这些数据清晰地表明,检索是实现兼具高性能和高效率的必经之路。
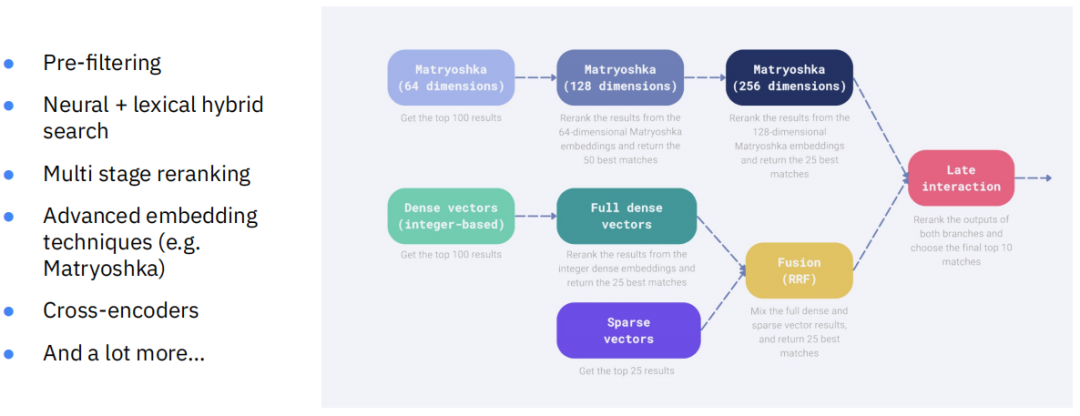
现代的检索管道本身就是一个极其复杂的系统,信息检索已成为应用AI领域最被低估的核心技能之一。一个先进的检索流程可能包括:首先进行预过滤,然后进行结合了关键词和向量的混合搜索,得到初步结果。
接着,通过多阶段重排(Multi stage reranking)来优化结果排序,例如使用Matryoshka嵌入技术,从粗粒度到细粒度逐步筛选。之后,还可能使用计算成本更高的交叉编码器(Cross-encoders)进行最终的精排。整个流程融合了多种技术,以确保在最终提交给LLM之前,上下文信息的信噪比达到最高。
成功初创公司的核心关注点
那么,顶尖的应用AI初创公司究竟在执着于什么?答案并非仅仅是追逐最新的模型。他们的精力更多地投入在以下几个方面:
首先是评估(Evaluations)。“你即是你的评估”——这句话道出了核心。没有科学、可靠的评估体系,就无法衡量产品的改进,也无法做出正确的技术决策。
其次是Data curation。正如Greg Brockman所言,手动检查数据可能是机器学习中价值与声望比率最高的活动。高质量、经过精心清洗和标注的数据,是训练、微调和评估模型的基础,其重要性无论如何强调都不为过。
他们还致力于用用户体验(UX)来解决研究层面的问题。当一个技术问题在研究层面难以完美解决时,他们会思考如何通过巧妙的工作流设计或产品交互,来规避或弥补技术的不足。
此外,他们将搜索与检索(Search & Retrieval)放到了极高的战略位置,投入在检索工程上的精力可能是模型本身的10倍。他们深刻理解,送入模型的信息质量直接决定了输出质量。
最后,他们普遍将模型层视为“最后的手段”(last resort)。他们的优化顺序是:优先优化提示词(Prompt),其次是优化系统工程(Systems engineering),再次是模型后训练(Post train),最后才是成本高昂的预训练(Pre-train)。这种系统性的思考方式贯穿了他们产品开发的始终。
从产品到生态:分化、权衡与未来
在产品层面,差异化正在通过更深层次的创新实现。以AI笔记应用市场为例,尽管该领域早已挤满了Fireflies.ai、Otter.ai等众多玩家,但Granola通过彻底重塑AI笔记的用户体验模式,成功进入并赢得了市场。
这表明,设计驱动的公司和创始人,在当前AI产品同质化严重的背景下,拥有巨大的机会。然而,整体来看,当前基础模型应用的UX设计模式仍处在非常早期的阶段,许多界面让人联想到功能机时代或早期PC软件,显得生硬和笨拙,这既是挑战,也是创新的空间。

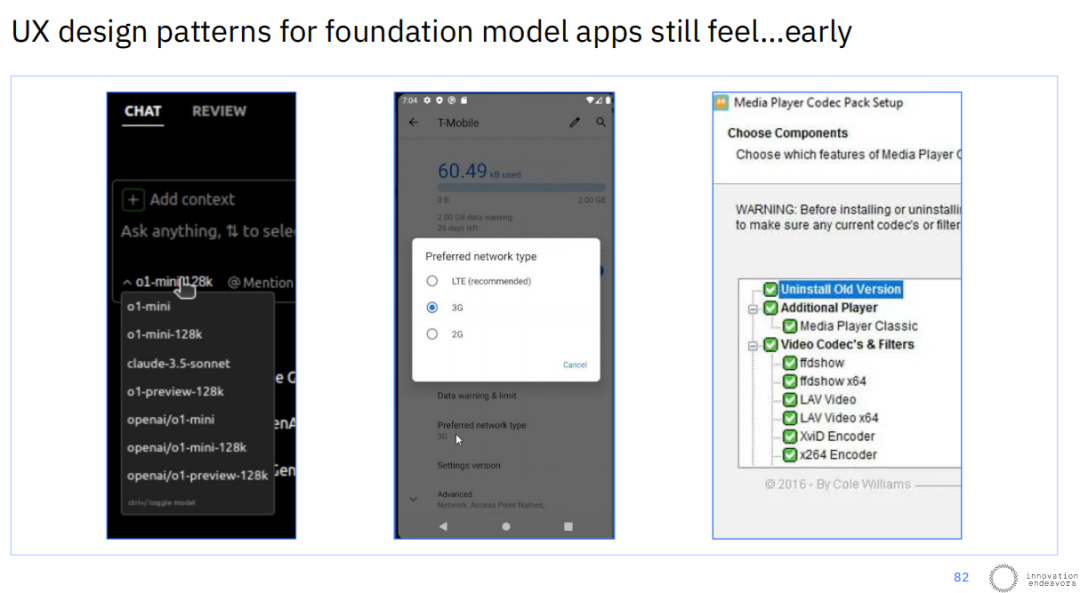
AI初创公司还必须在一个核心的战略困境中做出抉择:是围绕当前模型的缺陷构建复杂的工作流,还是等待模型能力的下一次跃升。一个典型的例子是AI头像生成。过去,像Lensa这样的应用需要用户上传多张照片,经过复杂的微调流程,才能生成定制化的头像。
而现在,随着GPT-4o等模型的出现,用户只需提供一张图片和一段文字描述,通过上下文学习(In-context learning)就能即时获得高质量的、风格化的图像,这使得原先整个复杂的流程变得多余。
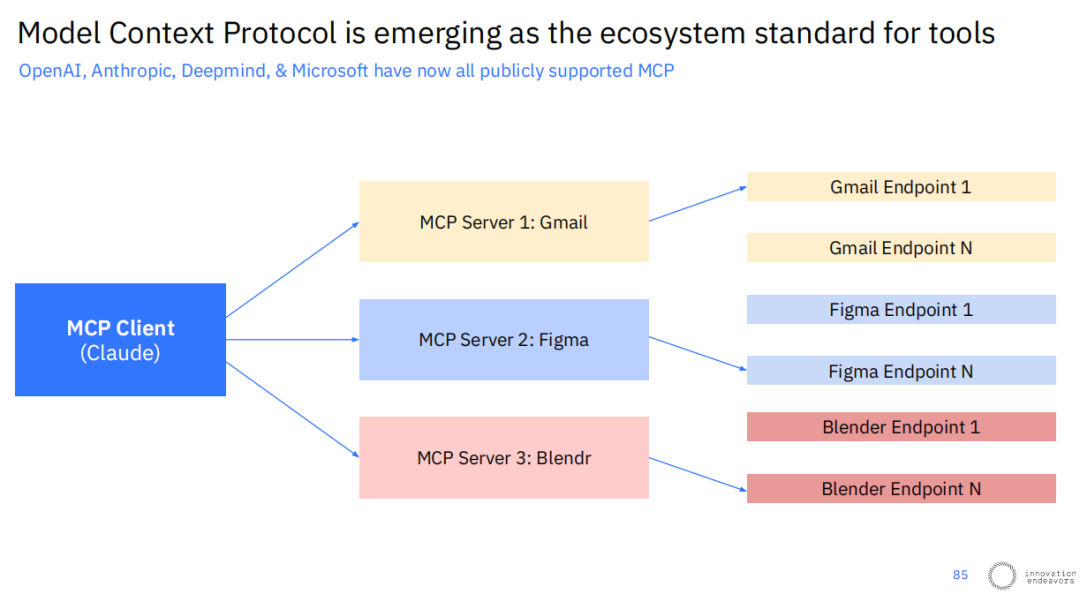
面对智能体需要与各种外部工具交互的现实,生态系统层面也开始出现标准化的努力。模型上下文协议(Model Context Protocol, MCP)正逐渐成为一个行业标准,获得了OpenAI、Anthropic、Deepmind和微软等巨头的公开支持。
MCP旨在为AI模型(客户端,如Claude)与不同应用程序(服务器,如Gmail、Figma)之间提供一个统一的交互接口。理论上,这能极大地简化工具的集成过程。
然而,标准化与性能之间存在着天然的张力。研究和实践都表明,智能体工具的使用界面对最终效果的影响是巨大的。即便是微小的界面变化,比如在代码编辑器工具中提供“带语法检查的编辑”选项,或是在搜索工具中提供“迭代式搜索”功能,都会对任务的成功率产生显著影响。

最后,一个常被忽视的差异化维度是“个性”。大多数面向普通消费者的AI产品都朝着遵循指令、类似研究助理的工作流进行优化。但不同的应用场景需要截然不同的AI个性。
例如,在设计领域,用户需要的是创造力和随机性;在教育领域,需要的是权威性和适度的引导;而在心理治疗领域,则更侧重于提问而非直接给出答案。已有研究表明,未经严格对齐的基础模型在某些创造性任务上甚至能胜过对齐后的模型,这说明“个性”本身就是一个可以被设计和优化的产品特性。

这一切复杂应用的背后,是一个日趋成熟的基础设施生态系统。从提供模型推理服务的Fal.ai和Together.ai,到数据管理的Datalog.ai,再到评估与可观测性平台Braintrust和Langfuse;从嵌入服务Voyage AI,到检索数据库LanceDB,再到各种框架、智能体工具和特定领域(如视频、文档处理)的基础设施,一个完整的产业链正在形成,为构建下一代AI产品提供了坚实的支撑。
更深层次地,这场由基础模型驱动的革命,甚至正在催生半导体行业的复兴,大量专注于Transformer架构的新型芯片初创公司涌现,预示着从软件到硬件的全栈式创新浪潮才刚刚开始。


05
市场结构与动态:
资本、巨头与应用的重塑
人工智能领域的市场结构与动态正在经历一场由资本、技术和商业模式共同驱动的剧烈变革。资本的流向是市场热度最直接的指标,而数据显示,资金正以前所未有的规模和速度向AI领域,特别是基础模型公司集中。
资本的洪流:AI投资的空前集中
风险投资的格局在过去几年发生了根本性的转变。2024年,全球约有10.5%的风险投资额流向了基础模型(Foundation Model)公司,总额高达330亿美元。这一比例相较于2020年的仅约0.03%,增长了数百倍,显示出资本市场对底层技术平台的巨大信心。这一趋势在2023年已初现端倪,当年投向基础模型实验室的资金达到了150亿美元,占全球风险投资总额的5.3%。
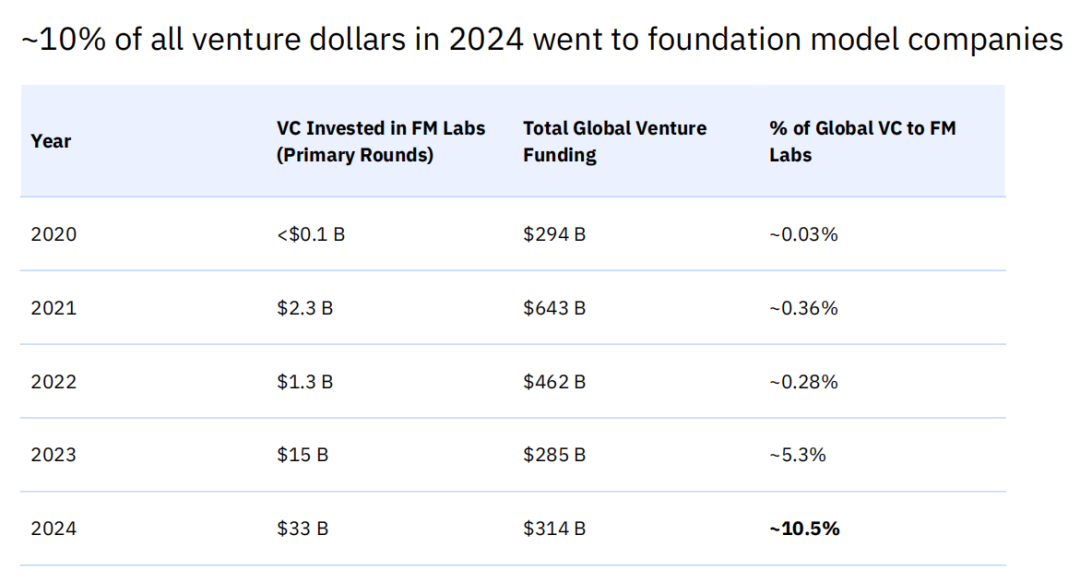
进入2025年,这一趋势愈演愈烈。数据显示,2025年迄今为止,已有超过50%的风险投资被部署到了AI相关的公司。这是一个惊人的数字,标志着AI已经从一个重要的投资赛道,转变为整个风险投资生态的绝对中心。资本的这种高度集中,正在深刻地影响着市场的竞争格局和技术演进的方向。
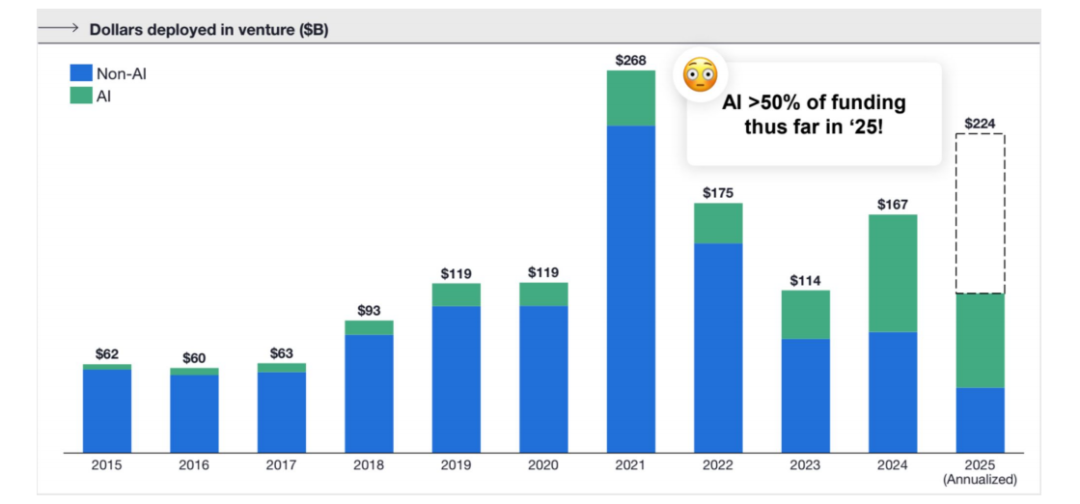
基础模型公司的分化与生存策略
在资本的助推下,头部的基础模型初创公司正在以惊人的速度实现收入增长。OpenAI预计其2025年的收入将达到127亿美元,相较于2024年的37亿美元,增长超过三倍。同样,Anthropic也证实其年化收入在第一季度达到了20亿美元,相比上一时期实现了超过一倍的增长。
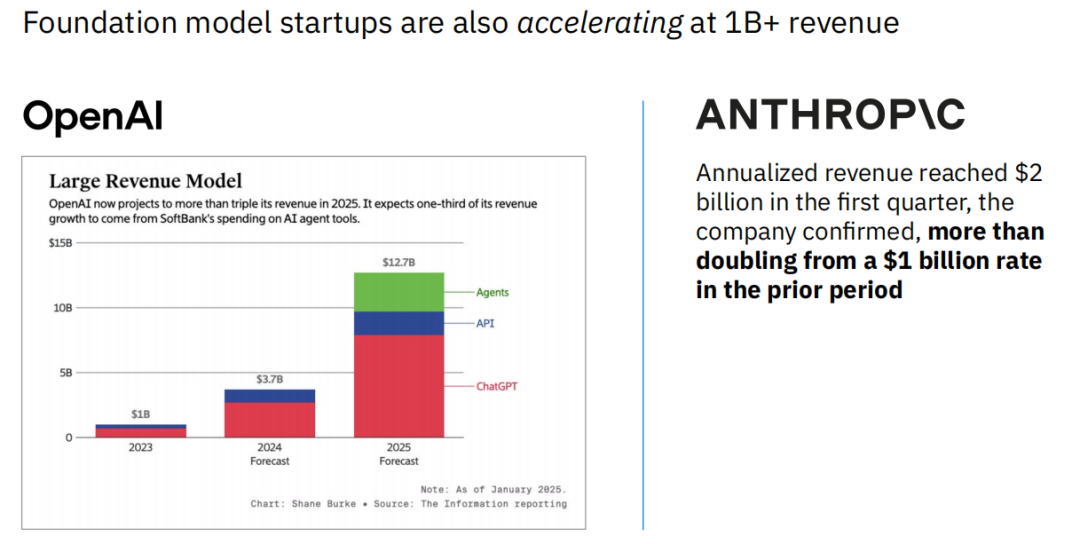
然而,在高速增长的背后,这些巨头的商业模式正在出现明显的分化。根据收入构成的估算,OpenAI正日益成为一家消费者应用公司,其约73%的收入来自于ChatGPT的订阅服务。相比之下,Anthropic则更像是一家API公司,其高达85%的收入来自于向开发者和企业提供的模型调用接口。这种战略上的分野,预示着它们未来不同的发展路径。
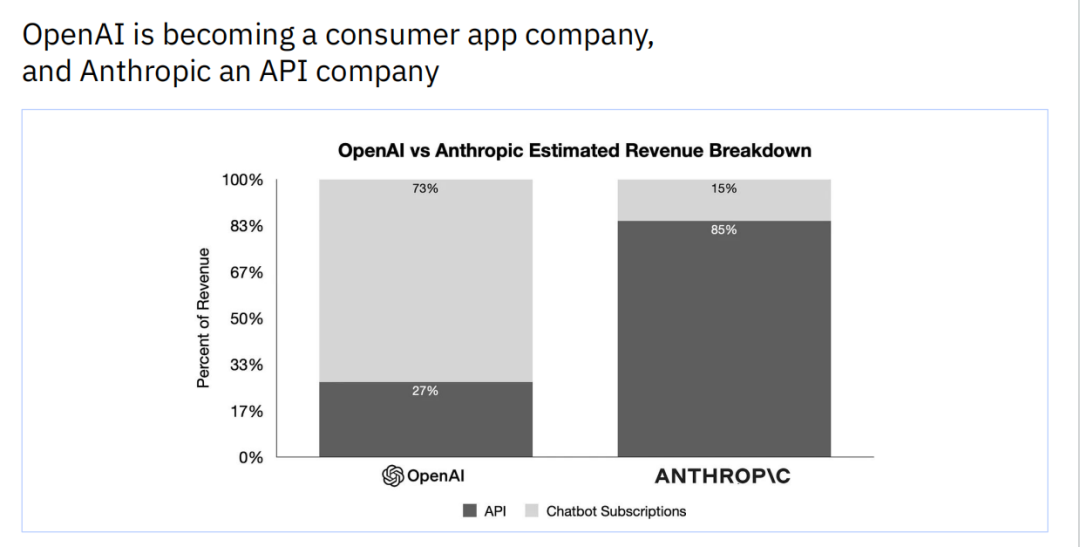
这种分化背后,是一个更深层次的战略考量:为了生存和建立长期的护城河,领先的模型公司很可能必须向上游移动,成为应用层公司。单纯提供底层模型API的商业模式,面临着被商品化的巨大风险。
因此,我们看到OpenAI不仅被报道正在开发类似X的社交媒体平台,还在洽谈收购AI代码初创公司Windsurf。与此同时,Anthropic也聘请了Instagram的联合创始人来担任其产品负责人。这些举动都清晰地表明,控制应用和用户入口,正在成为基础模型公司下一阶段竞争的关键。
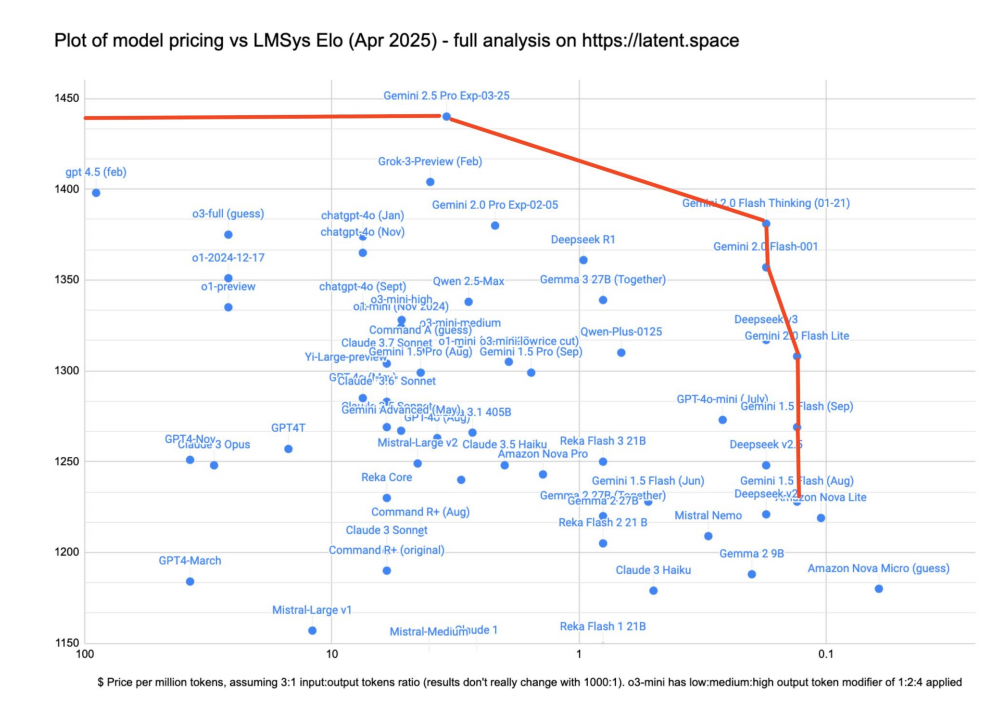
在这场竞争中,起步稍晚的谷歌,正展现出越来越难以阻挡的势头。截至2025年4月,谷歌的Gemini系列模型在速度与质量的帕累托前沿曲线上占据了绝对的统治地位。从高性能的Gemini 2.5 Pro,到高性价比的Gemini 1.5 Flash,再到各种不同规模的变体,谷歌凭借其规模经济优势,几乎在每一个细分性能区间都提供了业界领先或极具竞争力的选项。这充分体现了基础模型竞赛本质上是一场资本和规模的游戏。
寻找粘性:从应用层到物理世界
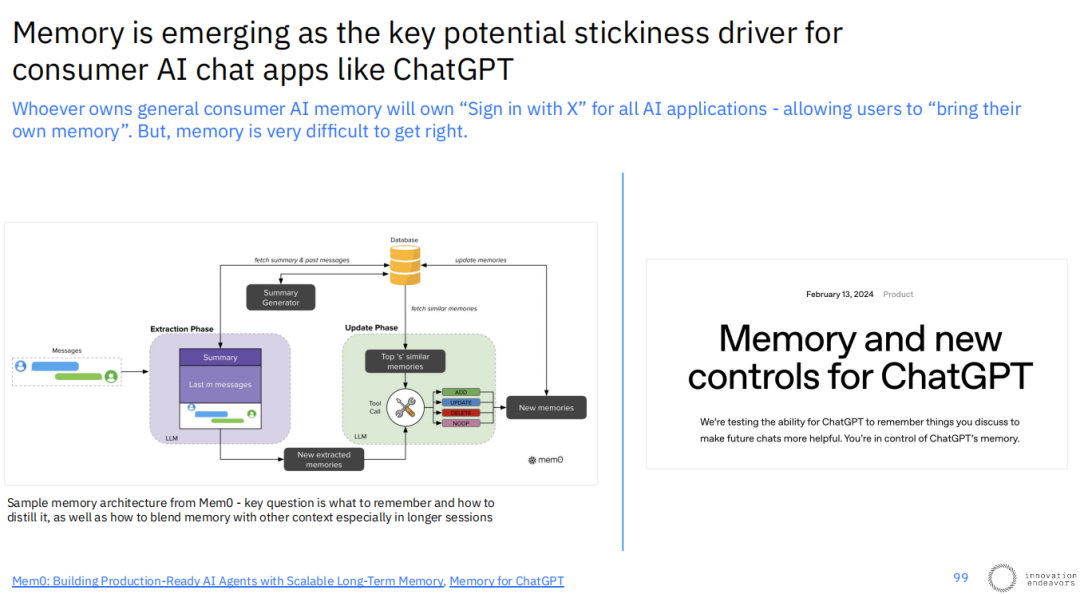
对于面向消费者的AI聊天应用而言,“记忆”(Memory)功能正在成为一个关键的潜在用户粘性驱动力。谁能掌握通用消费级AI的记忆,就可能掌握未来所有AI应用的“用X登录”入口,允许用户将自己的偏好、历史和上下文“携带”到任何应用中。
然而,实现一个好的记忆系统极其困难。其核心挑战在于,如何从冗长的对话中有效提取、总结和更新需要被记住的核心信息,并将其与新的上下文恰当地融合。
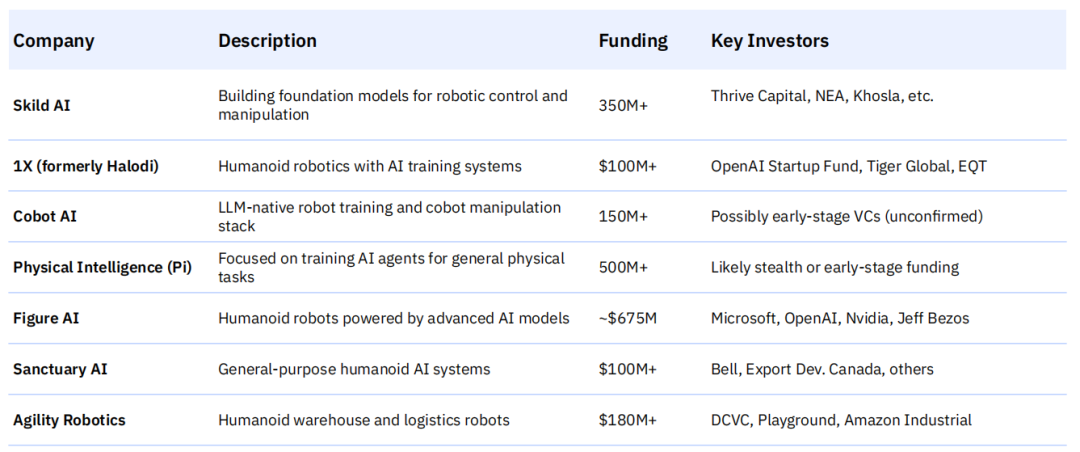
当我们将目光从纯软件领域投向物理世界,一个重要的问题浮出水面:在机器人等物理领域的基础模型公司,能否像图像和文本领域的公司一样“对抗地心引力”,实现类似的快速发展和高估值?这些领域的运营复杂性远高于纯软件,但其定价模式却与软件相似。尽管如此,大量资金已经涌入这个赛道。
从Skild AI、Figure AI到Physical Intelligence,众多初创公司正在构建用于机器人控制、人形机器人和通用物理任务的基础模型,并获得了数亿美元的巨额融资,其投资者不乏微软、英伟达、OpenAI等行业巨头。
应用层的爆发与隐忧
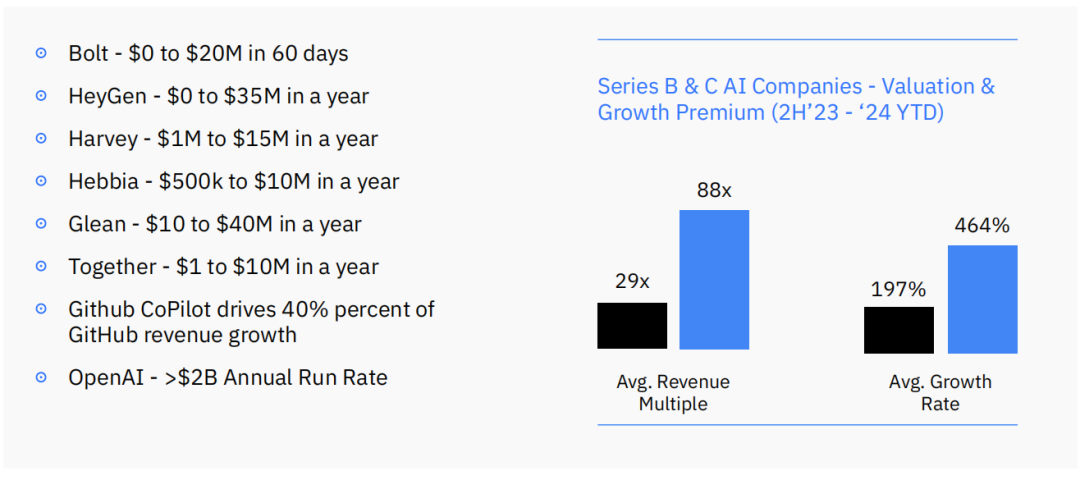
AI应用层本身也正经历着前所未有的收入增长和高估值。一些AI原生应用展现了堪称恐怖的增长速度,例如Bolt在60天内实现2000万美元收入,HeyGen在一年内从零增长到3500万美元。整体来看,B轮和C轮的AI公司,其平均收入倍数和增长率远超传统SaaS公司。
如今,AI原生应用的总年化运行收入(ARR)已经达到了数十亿美元的规模。从Midjourney、Cursor到ElevenLabs,一批年收入过亿甚至数亿美元的公司已经出现,覆盖了图像生成、代码、音频、企业搜索等多个领域。
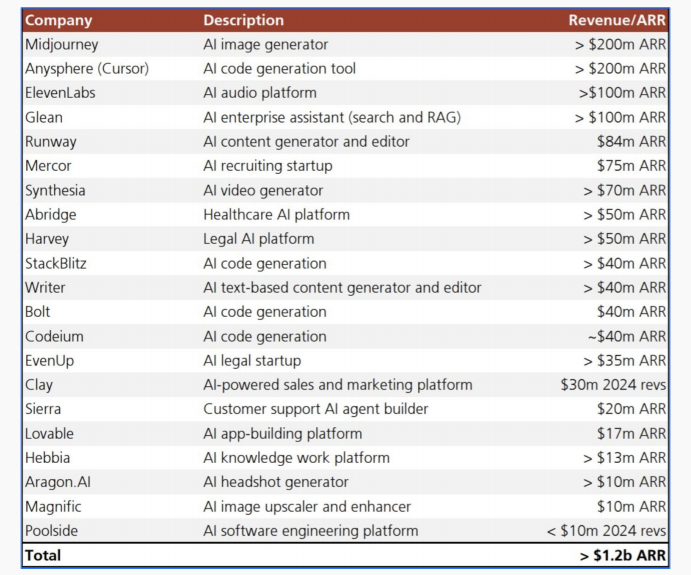
这种强劲的增长正在从根本上重塑人们对于软件付费的预期。有观点认为,在未来几年,专业人士每月为AI工具支付5000至10000美元将并非不合理。OpenAI甚至计划向使用高级AI代理进行高水平研究的用户收取高达每月20000美元的费用。这种定价模式的转变,源于AI为用户创造的巨大价值。
一个值得关注的现象是,即便在位者拥有所有可以想象的优势,AI初创公司依然能够赢得市场。AI并非一种简单的“维持性创新”,它在构建产品的方式上与传统软件有着本质不同。例如,在代码辅助领域,初创公司Cursor正在挑战GitHub Copilot;在创意工具领域,Krea正在与Adobe Firefly展开竞争。
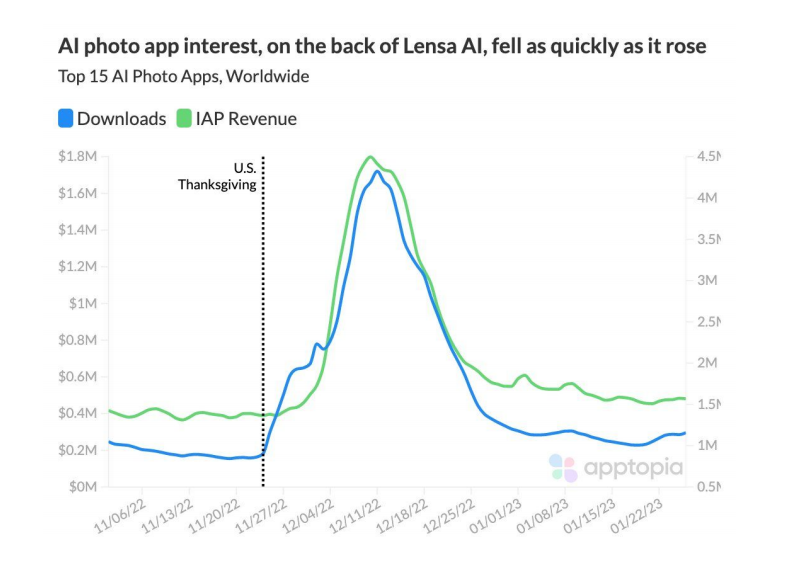
然而,繁荣之下亦有隐忧。AI初创公司的收入增长存在巨大的“新奇效应”风险,许多产品的收入曲线呈现出“快速崛起又快速陨落”的形态。AI照片应用Lensa的流行度便是一个典型案例,其用户兴趣和应用内收入在达到顶峰后迅速回落。
总体而言,AI市场在许多维度上都存在明显的“泡沫”感。许多公司在没有建立起清晰的产品市场契合点的情况下,每年就烧掉超过5000万美元用于模型训练。法国AI初创公司H在获得2.2亿美元种子轮融资仅三个月后,三位联合创始人便宣告离职,这无疑是市场过热的一个注脚。
在整个产业链的底部,GPU生态系统的市场结构与传统的CPU生态有着深刻的不同,这催生了新一代“GPU云”供应商的崛起。传统的云服务商(如Google Cloud)通常将硬件与云服务捆绑销售,而GPU工作负载的特性决定了用户更关心单位预算内能获得多少额外的计算时间,而非增值软件服务。
因此,像CoreWeave这样的新型供应商,专注于提供纯粹的GPU算力,并采用更符合AI训练需求的长期固定合同,从而获得了市场的青睐。

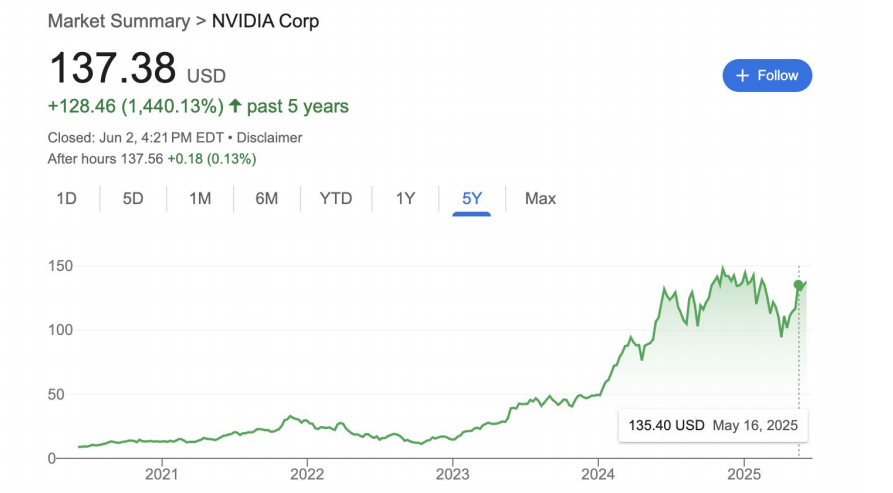
但无论市场如何变化,英伟达及其GPU生态系统依然是这场变革中“有保证”的赢家。根据其财报,AI推理token的生成量在短短一年内就增长了十倍。其股价在过去五年的飞涨,是其在AI浪潮中核心地位的最有力证明。
06
未来已来:
AI原生公司的运作范式
AI的普及正在从根本上改变公司的运作方式。顶尖的公司正在越来越多地采纳一种新的信条:“学会使用AI,否则就离开。”这不仅仅是一句口号,而是一种正在成为现实的组织变革。
组织与人的重塑
在未来,有效使用AI将不再是一项特殊技能,而是对组织中每个人的基本期望。它就像今天使用电脑或互联网一样,是所有行业的基本工具。停滞不前几乎等同于缓慢的失败,因为不拥抱变化就意味着被时代抛弃。
这种变革直接体现在团队结构上。小而精、资本效率高的团队正在成为新常态。例如,AI初创公司Gamma在仅有30名员工的情况下,就实现了盈利和5000万美元的年化运行收入,而其上一轮融资仅为1200万美元。这表明,AI极大地放大了个人和小型团队的杠杆。
团队的构成也在快速变化。一位成长阶段初创公司的产品副总裁表示,他越来越看不出设计师和产品经理之间的区别。而一家上市公司的首席营销官则称,AI完全改变了他的招聘思路,他不再招聘专家,而是招聘能够熟练使用AI工具的通才。

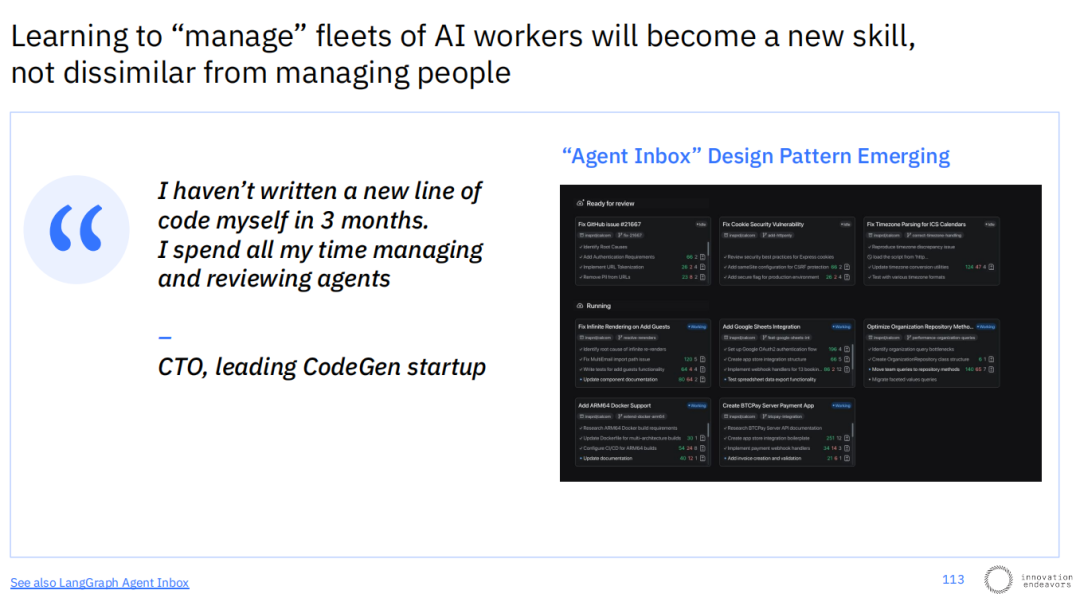
一种全新的管理技能正在出现:学习“管理”AI工作者集群,这与管理人类团队并无本质不同。一位顶尖代码生成初创公司的首席技术官坦言:“我已有三个月没写过一行新代码了。我所有的时间都花在管理和审查智能体上。” “智能体收件箱”(Agent Inbox)这样的设计模式正在兴起,它提供了一个界面,让管理者可以审查、批准和修正AI智能体完成的任务,就像管理一个团队的工作队列一样。
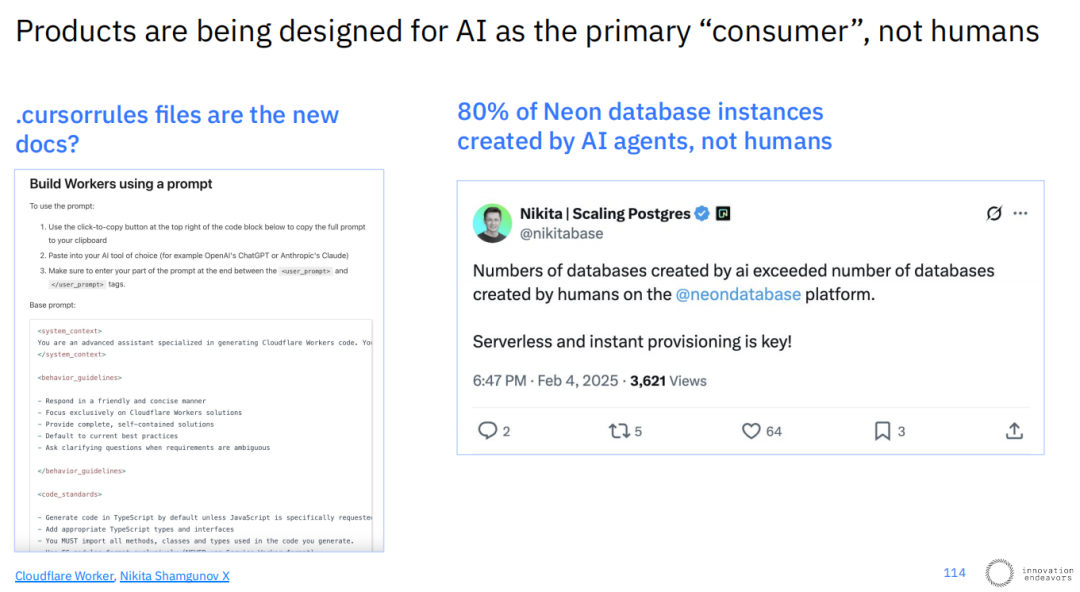
一个更深层次的范式转变是,产品开始被设计为以AI为主要“消费者”,而不仅仅是人类。例如,.cursorrules文件正在成为新的文档,它直接告诉AI如何与项目进行交互。在Neon数据库平台上,由AI代理创建的数据库实例数量已经超过了由人类创建的数量。这预示着一个未来:软件和系统的构建,将越来越多地围绕机器的可读性和可操作性展开。
价值的创造与毁灭
这场变革必然伴随着价值的毁灭与重塑。一些传统的工作模式和商业实体将面临巨大挑战。过去外包给代理机构和咨询公司的职能,如视频制作,将可能被内化。高度专业化的工作岗位和面向专家的工具,将面临来自“通才+AI”组合的冲击。
而主要围绕沟通和信息传递的中间管理岗位,如项目经理,其价值也可能被侵蚀。同时,那些在位者,如处理非结构化数据的CRM公司、创意工具公司和开发者工具公司,都处在AI冲击的“火线”上。任何不愿经历文化和组织变革阵痛的公司,都将面临被淘汰的风险。
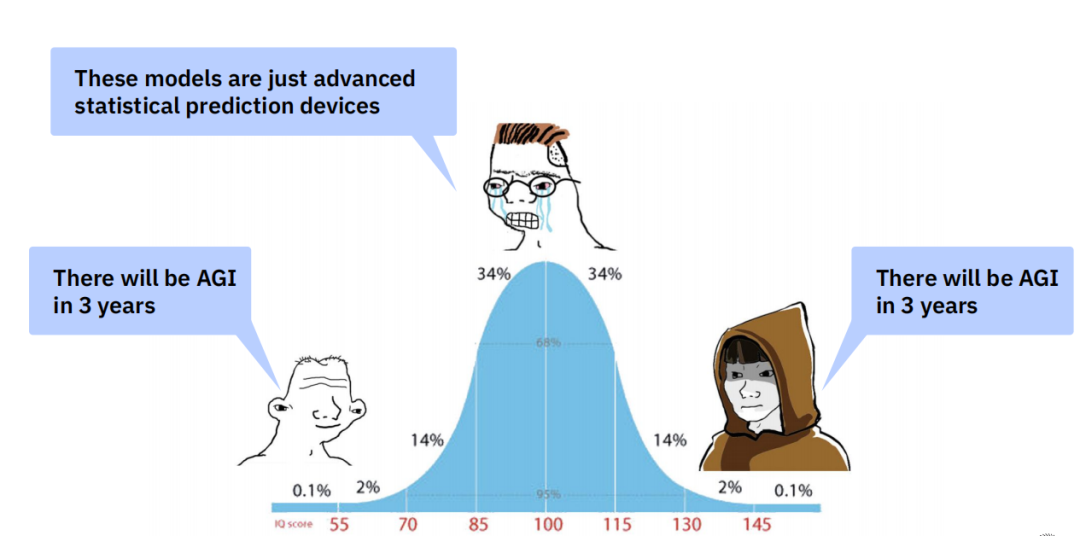
关于通用人工智能(AGI)是否临近的讨论,最聪明的AI研究者们的看法也呈现出有趣的分化。一个广为流传的智商分布图形象地描绘了这种现象:处于智力分布曲线两端的人(新手和顶尖专家)都倾向于认为AGI将在3年内到来,而处于中间的大多数专家则认为,这些模型只是先进的统计预测设备。这反映了对于AGI本质和实现路径的深刻分歧。
07
未来蓝图:
AI原生时代的机遇与重构
随着人工智能从底层技术渗透到应用的方方面面,一个全新的商业和社会图景正在被绘制。这不仅是现有模式的优化,更是一场深刻的重构。对于有远见的构建者而言,这意味着一片充满机遇的蓝海,其中蕴藏着重塑核心行业、创造新型服务以及定义下一代基础设施的可能。
软件开发的范式迁移
人工智能代码生成能力的普及,将对软件开发这一核心的现代工业活动产生深远且不可逆转的下游影响。其冲击力将贯穿整个软件开发生命周期(SDLC),并从根本上改变我们组织、构建和交付软件的方式。
首先,整个软件开发生命周期本身正面临重塑。在一个AI越来越多地承担代码编写工作的世界里,为人类协作而设计的传统流程,例如持续集成与持续部署(CI/CD)、Git版本控制以及可观测性工具,其底层逻辑都将受到挑战。
当代码的生成速度、数量和模式都发生数量级的变化时,我们现有的流程和工具必须随之进化,以适应一个以机器为主要生产力的全新开发范式。
其次,软件工程的重心正在发生一场“右移”的结构性转变。过去,产品经理和设计师的工作止于交付规格文档或设计稿,之后便进入漫长的工程开发阶段。而现在,借助强大的AI代码生成工具,这些非技术角色已经能够独立构建功能完善的原型,甚至直接向代码库提交拉取请求(Pull Request)。
这模糊了传统意义上产品、设计与工程之间的角色边界,也催生了对新型工具的需求,例如专为这些“公民开发者”设计的集成开发环境(IDE)。
这种角色的模糊化,最终将导向“AI原生”的软件组织形态。在这样的组织里,工程、产品和设计之间的严格分野将不复存在,团队协作的模式被彻底改写。任务管理工具所管理的对象,将不仅仅是人类工程师,更是成群的AI智能体。这种转变必然要求组织结构的相应调整,并催生出全新的协作与管理需求。
随之而来的是,软件的验证、测试与护栏的重要性被提到了前所未有的高度。当大量的代码由AI自动生成时,如何系统性地保证其质量、安全性和正确性,成为了一个核心挑战。过去被认为是利基领域的技术,如负载测试、形式化验证等,可能会成为主流的必备环节。
而“代码审查”这一活动,其内涵也将发生根本性变化,从人与人之间的交流,转变为人审查机器、甚至机器审查机器的全新工作流。我们甚至可能需要更好的方法,来自动化“产品”层面的反馈,例如通过运行大规模的合成用户体验研究,来快速验证产品方向。
数据即服务(DaaS)
大型语言模型(LLM)已经从根本上改变了我们与数据交互的每一个环节:收集、创建、结构化、理解和转换。这种能力的跃升,预示着“数据即服务”(Data-as-a-Service)这一商业模式将迎来一场深刻的文艺复兴,新的物种将从中诞生。
一个核心的突破在于,我们现在能够收集以前无法触及的数据。可以设想,利用语音智能体,我们能够以极低的成本大规模地进行用户访谈或市场调研;通过电子邮件智能体,能够以全新的方式大规模地征集数据。LLM的对话能力,使得从个人身上深度提取灵活、非结构化的洞察成为可能。
同时,LLM赋予了我们结构化过去无法结构化的数据的能力。例如,将成千上万个非标准化的个人网站,自动转化为元数据丰富、格式统一的结构化数据库。这等于解锁了互联网上沉睡已久的巨量信息价值。
在数据交付的“最后一公里”,LLM也扮演着关键角色。用户不再需要被束缚在预定义的数据模式或仪表盘中,而是可以通过自然语言,按需获取定制化的数据和分析结果。这使得数据消费的体验变得前所未有的灵活和强大。
更具颠覆性的是,我们可以将合成数据与真实数据智能地结合。LLM极擅长模仿真实用户或人群,从而生成高度逼真的合成数据。这些数据可以用来解决冷启动问题、增强稀疏的数据集,或者在保护隐私的前提下进行系统测试。
这一切最终将催生出全新的商业模式。当AI能够将收集特定数据的成本、精力或时间降低1000倍时,过去在经济上不可行的业务便成为了可能。例如,我们可以构建一个“主动式”的专家访谈平台,它能够自动识别潜在的专家,并主动发起个性化的访谈邀约,从而颠覆传统的研究和咨询行业。
下一代创意工具的护城河
在创意表达领域,AI同样带来了明显的颠覆机会。然而,当底层的生成模型趋于商品化时,真正的护城河将建立在AI本身之外。
一种有效的防御机制是构建网络。新的社交网络形式可能会围绕AI驱动的内容民主化而建立,允许用户“分叉”(fork)或“混音”(remix)他人生成的AI内容,从而形成独特的社区文化和网络效应。为AI原生创作者打造的专属市场,也可能成为新的平台级机会。
其次,当内容的生产变得极其容易时,底层的运行环境(Runtimes),如游戏引擎或图形渲染基础设施,其价值反而会变得更加重要。因为高质量地呈现和交互这些海量内容,本身就是一个技术壁垒。
工作流的特异性是另一个关键的差异化维度。相较于开发通用的、功能齐全的创意工具,那些专注于特定类型创作者(例如,专门服务于品牌设计师,或专门服务于摄影师)的深度工作流产品,更容易建立起用户粘性。
一个巨大的创新机会在于,将传统的、精确可控的编辑模式与AI的生成能力相结合。这能让创作者在快速的灵感“氛围原型”(vibe prototyping)和经典的、基于图层的精细化编辑之间无缝切换,实现两全其美。
最后,一个常被忽视的现实是,许多专业的创意设计领域缺乏一个像VSCode之于编程那样的、开源且具有丰富插件生态系统的核心编辑器。这使得为这些领域构建“副驾驶”(copilot)变得异常困难。因此,一个潜在的路径是,首先为某个创意领域(如视频编辑)打造出它的“VSCode”,建立起平台和生态,然后再在此基础上构建强大的AI辅助工具。
寻找AI时代的“石油”:数据、科学与基础设施
数据,很可能将持续是推进AI系统发展的最大瓶颈。因此,寻找新颖、巧妙的方式来生产更多、更高保真度的数据,本身就是一个巨大的商业机会。
例如将数据作为产品的副产品来生成,例如开发一款免费应用,其核心商业模式是它在后台生成的、用于机器学习的高质量数据。创建用于强化学习的高质量仿真环境,即一个“用于RL的Ansys”,让企业可以方便地创建、管理和运行智能体训练环境,也是一个明确的方向。
AI与科学的结合,将在化学、生物学、材料学、数学等各个领域产生深远影响。这里的核心瓶颈同样是数据。因此,机会在于开发新型的数据捕获工具,例如专为AI分析而设计的、能够进行大规模筛选和感知的生物显微镜。
另一个方向是构建“生成+验证”的闭环系统,即所谓的“AI科学家”,它将生成式模型的预测能力与传统的计算建模(如计算流体动力学)和真实的湿实验室自动化相结合,形成一个从提出假说、进行实验到验证结果的自动化科学发现循环。
这一切的实现,都离不开新一代的AI基础设施。随着生成式模型的发展,企业将需要管理和处理日益复杂的音频、视频、图像、文本等多模态数据。同时,越来越多的基础设施(如数据库、虚拟机、API)正由AI智能体而非人类直接调用,这将极大推动无服务器、按需扩展、强隔离的架构成为主流。
更重要的是,我们需要为AI系统设计全新的基础设施原语,例如专为AI智能体设计的网络浏览器、计算沙盒、支付和身份验证接口。当成群的智能体在用户的环境中运行时,授权和细粒度访问控制等传统基础设施问题,其复杂性将被放大百倍,亟待新的解决方案。
最后,当我们开始将AI应用视为复杂的“系统”时,相应的基础设施和工具需求也随之改变。我们需要更强大的工具来优化、测试和评估这些由多个模型和组件构成的复杂系统。一个清晰的创业机会是,提供一流的、通用的奖励模型和验证器,它们将像今天的嵌入模型一样,成为一个标准的模型类别。
同时,随着企业越来越希望在自己的领域内应用强化学习,提供易于使用的领域特定RL工具和基础设施,将解决一个巨大的痛点。最终,结合强大的“生成器”模型和独立的“验证器”系统,将成为构建可靠、可信AI产品的关键架构模式。

(文:Founder Park)