

Grok-4的基准测试数据在网上疯传。
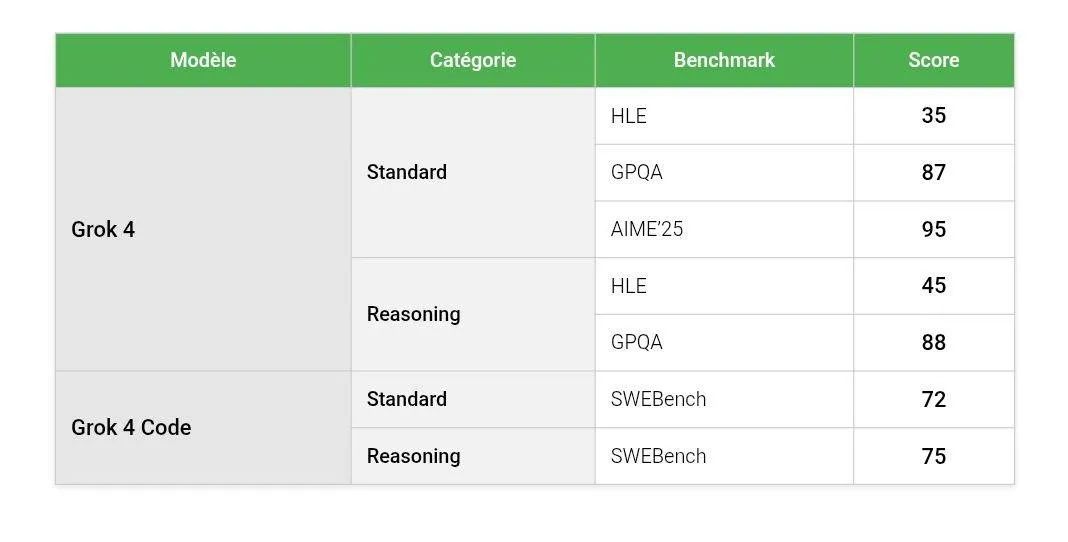
刚刚,API开发者ʟᴇɢɪᴛ(@legit_api)率先曝光了Grok-4和Grok-4 Code的测试成绩,数字让人倒吸一口凉气:HLE(人类最后的考试)上达到35%,使用推理后更是飙升到45%!

这是什么概念?
要知道,o3和Gemini在HLE上的得分仅为20%左右。而如果这个数据属实,Grok-4相当于直接翻了一倍多。
除了HLE,其他基准测试的表现同样一马当先:
-
GPQA达到87-88% -
SWE Bench上,Grok-4 Code拿下**72-75%**的成绩
leo 🐈(@synthwavedd)评论称:
这些如果是真的,都是SOTA(最先进)成绩。希望它在实际使用中也能这么好。
但并非所有人都买账。
K Aayush Mazumdar(@Tweeting_Aayush)立即提出了质疑:
SWE-Bench是验证过的吗?没有工具/框架的情况下?
SWE Bench测试的是模型解决真实软件工程问题的能力,如果使用了额外的工具或框架,成绩的含金量就要打折扣了。
更多人关心的是:这个模型到底什么时候发布?
Zhuo Wang(@ZhuoWang1022019)直接发问:
如果它这么好,什么时候发布?
The Mandorlarian(@mandorlarian)则表现得更加悲观:
兄弟我真的不能。不认为这个模型会发布,空洞的数字什么都不意味着。
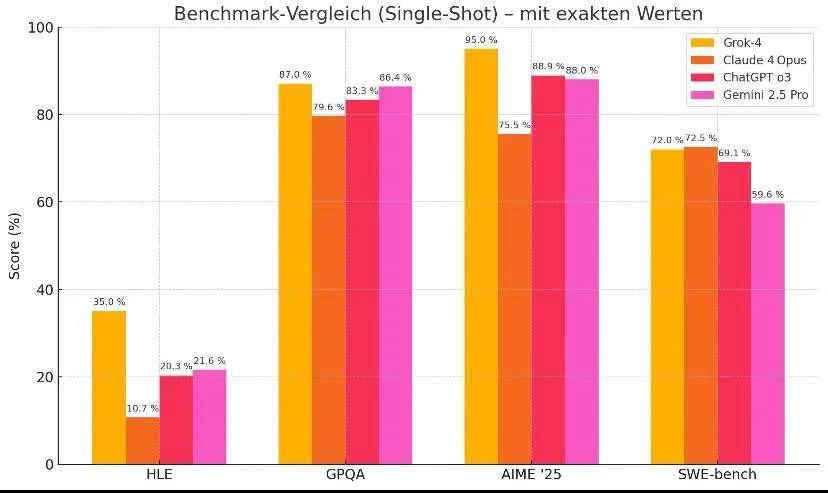
为了让大家更直观地理解这些成绩,mark erdmann(@markerdmann)贴出了与其他前沿模型的对比图:



从对比中可以看出,若数据准确,则Grok-4在多个维度上都超越了现有的所有顶尖模型。
但HLE 45%的成绩引发了最大的争议。
AI研究者xlr8harder(@xlr8harder)指出了一个关键问题:
我才意识到HLE的所有题目都已经公开,没有保留测试集。这太不幸了。
这说的是,如果测试题目都是公开的,模型就有可能在训练时“见过”这些题目,导致成绩虚高。
Ethan Mollick(@emollick)教授对此回应道:
如果Grok 4泄露的基准测试是对的,HLE有保留的问题集就非常有用了,因为传闻中的45%分数比o3和Gemini的20%左右有很大提升,这会相当令人印象深刻(假设没有数据污染)。
他还贴出了官方文档,证明HLE确实有保留测试集:

但质疑声并未平息。
Alfredo González-Espinoza(@AGonzalezEsp)坚持认为:
看起来数据被污染了。考虑到Grok 3在ARC-AGI测试上的结果,他们很可能使用了被污染的数据。
Hasan Can(@HCSolakoglu)表达了担忧:
HLE分数高度可疑,这将是一个基准创建者需要立即在隐藏集上测试的模型。但如果你问我,这都是脚手架和共识技巧。
有趣的是,itsdrizzy(@itsdrizzy4)从另一个角度分析了这些数据:
ArtificialAnalysis的独立基准测试显示o3在GPQA上得分82.7%,这意味着Grok 4比o3高出近10%。如果o1到o3(一代)从~75%提升到82.7%(7.7%的差异),Grok 4基本上就是o4级别(~5%的差异)。
除了各种质疑,也有支持者们在积极回应。
Jefferson Way(@TheJeffersonWay)为xAI辩护:
我是说他们有20万个GPU,以400 TPS运行grok 3 mini,为什么很难相信?
Prashant(@Prashant_1722)则兴奋地转发:
Grok 4和Grok 4 code 🔥🔥

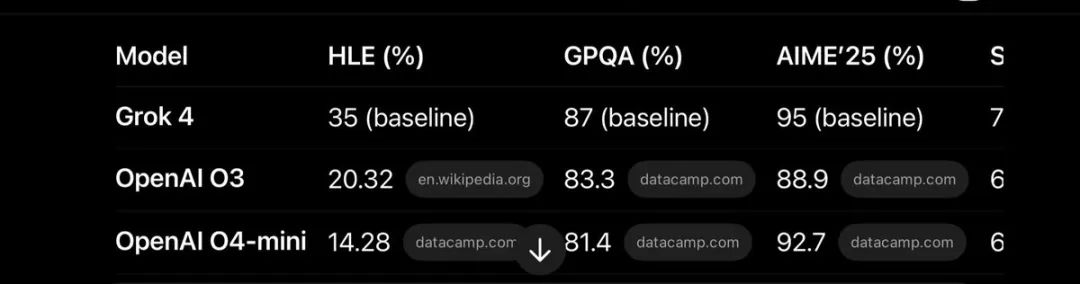
PDV Uberjeets CTO(@PDVhw)甚至贴出了更多细节图:

Sughu(@sughanthans1)总结道:
如果这是真的,Grok 4真的做到了。
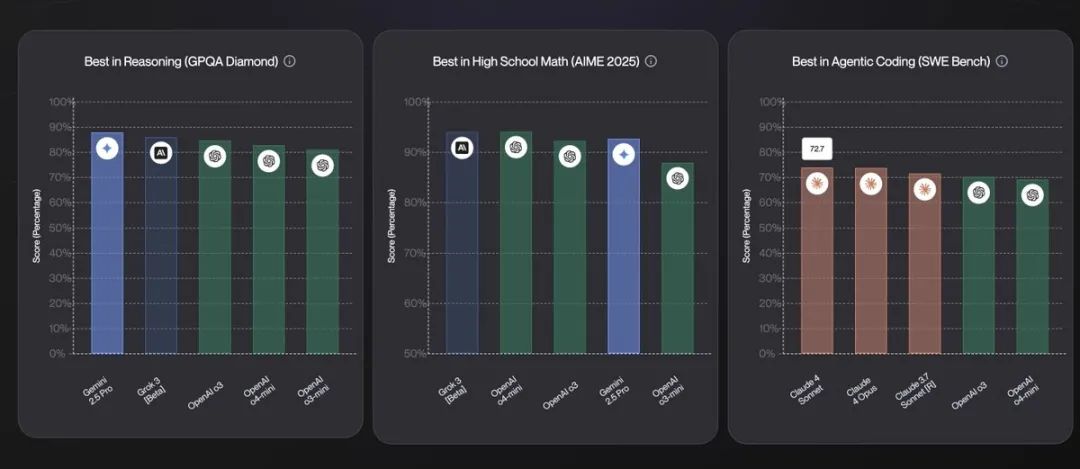
muzz(@muzzkek)则提醒大家需要看相对分数:
加上相对评分也不会要你的命。
而Mel Gibson 2.0(@AIMelGibson) 则提出了一个实际的观点:
我最感兴趣的是幻觉率,如果这能在基准测试上击败o3,但幻觉率也低得多,那我们就找到了什么。对我来说,这是阻止o3成为极其有用的模型的唯一因素。
CuteRobot(@lukeNukemAI)则思考得更远:
想象一下当所有基准测试都被打败时?他们将如何测试LLM?
不得不说,45%的HLE成绩若是属实,那马斯克的xAI 将后来居上,并真的将一骑绝尘了可能要。
但截止目前,相关数据仍为传言,未经官方证实。
而网友们,一边是兴奋和期待,一边是质疑和担忧。
这种撕裂也反映了当下大家的心态:我们既渴望突破,又害怕被欺骗。
无论Grok-4的成绩是否真实,有一点是确定的:这场关于AI能力边界的竞赛,才刚刚开始。
(文:AGI Hunt)