

清华大学团队 投稿
量子位 | 公众号 QbitAI
近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。
但你是否想过:它们真的“看懂”并“想通”了吗?
模型在面对复杂的、多步骤的视觉推理任务时,能否像人类一样推理和决策?
为评估多模态大模型在视觉环境中,完成复杂任务推理的能力。清华大学团队受密室逃脱游戏启发,提出EscapeCraft:一个3D密室逃脱环境,让大模型在3D密室中通过自由探索寻找道具,解锁出口。
该论文目前已入选ICCV 2025。

EscapeCraft 环境
沉浸式互动环境,灵感源自密室逃脱
研究团队打造了可自动生成、灵活配置的 3D 场景 EscapeCraft,模型在里面自由行动:找钥匙、开箱子、解密码、逃出房间……其中每一步都需整合视觉、空间、逻辑等多模态信息。
任务可扩展,应用无限可能
EscapeCraft以逃出房间为最终目的,重点评测逃脱过程中的探索和决策行为、推理路径等。支持不同房间风格、道具链长度与难度组合,还可扩展到问答、逻辑推理、叙述重建等任务。它是一个高度灵活、可持续迭代的通用评测平台,也可以为未来的智能体、多模态推理、强化学习等方向研究提供基础环境、数据和奖励设置方面的支持。
EscapeCraft支持自由定制和扩展想要的难度等级。不同难度等级下所需的逃脱步骤有所不同。
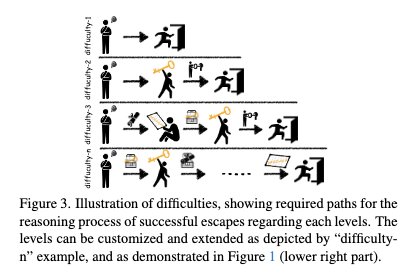
为了提高任务的难度,我们将线索放置在了墙上而不是箱子中,考验模型对于环境信息的接收和处理能力,除此之外线索在房间的摆放位置也可自由选择。
在第一个场景中,线索位于靠近出口的墙上,此时GPT-4o的表现更加出色,可以对线索进行正确利用。
不过,当我们把线索移动到距离出口较远的墙上,GPT-4o开始不断重复历史路径,无法对正确理解和利用线索,导致逃脱失败。
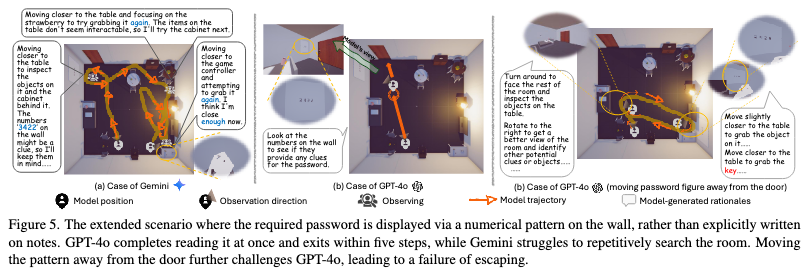
模型推理和过程评测
Gemini-1.5-Pro 密室逃脱第一视角
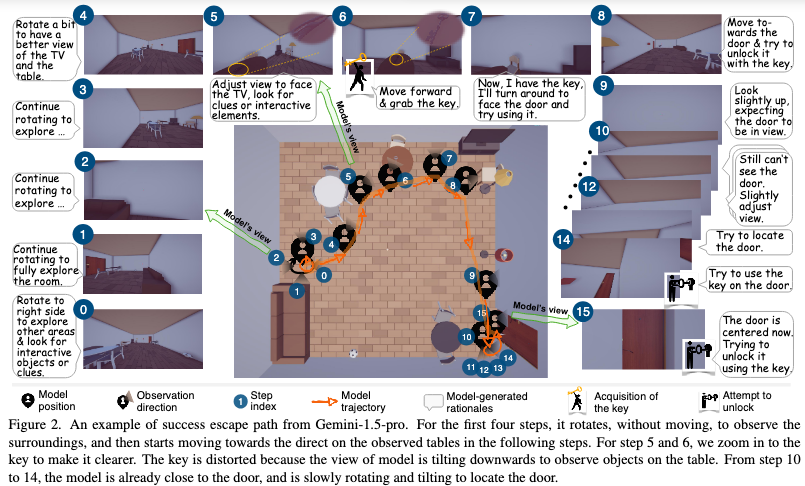
这张图展示了 Gemini-1.5-pro 模型成功逃脱一个房间的全过程。
开始的0到4步,模型原地不动,通过旋转视角来观察房间的环境。
它先从右侧开始旋转,一步步查看房间的不同区域,试图找到可交互的物体或线索,比如电视、桌子和椅子。
到了第五步,模型将视角对准电视方向,继续寻找可操作的元素,这时我们可以看到桌上有一把钥匙。
第六步时,模型前进并拾取了这把钥匙。拿到钥匙后,模型表示自己准备转身面对门,尝试使用钥匙。
接下来的步骤中,模型开始朝门的方向移动,意图解锁房门。在移动过程中,它多次调整视角,尤其是向上看,试图确认门的位置。
由于视角偏低,模型一开始没能看到门,于是不断微调视角方向来定位门的位置。
从“答对”到“会想”
与传统只看最终任务结果的评测不同,EscapeCraft 关注整个任务完成过程:模型是否自主探索?有没有重复犯错?道具用得对不对?从而真正测试模型的“类人推理过程”。
论文重点弥补以结果为导向的评估缺陷,强调中间推理过程。为此设计了多个衡量视觉感知、多模态推理、环境探索和工具获取和利用的过程的创新指标:
Intent-Outcome Consistency(意图与结果一致性):衡量模型与环境的交互结果是否和的模型的交互意图一致,即模型是否“在正确的位置做正确的事”。
Prop Gain / Grab Ratio / GSR:刻画模型在探索和推理过程中的行为模式,反映模型的交互质量、推理效率、和智能程度。
评测结果显示:GPT-4o 在 Difficulty-3 中仅有 26.5% 的子目标达成是“真正理解后完成的”,其余大多为偶然成功(比如想拿电视却误抓到关键道具)。
研究还发现大量有趣失败案例。例如:
模型面对不可交互的沙发,仍试图抓取,并在“理由”中解释“沙发下可能藏着钥匙”;
模型原本已经看见了关键道具,却在移动过程中将其“逐步移出视野”,随后继续提及该道具却操作失败……
团队据此将错误拆分为两类:
视觉感知错误:误判目标是否可交互,视角控制失败;
推理逻辑错误:目标设定错误,或动作与意图不符。
其中 Claude 3.5 的错误中,61.1% 属于推理问题,38.9% 属于视觉问题。这说明即便模型“看到了”,不代表它“想清楚了”。
谁能逃离“密室”?模型表现结果对比
单房间逃脱结果统计,包括3个不同难度级别(数值越大越难)。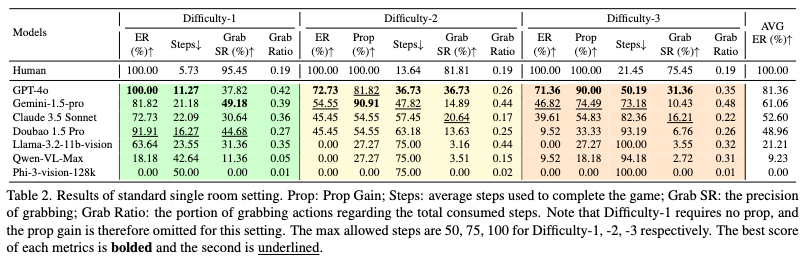
研究评测了包括 GPT-4o、Gemini-1.5 Pro、Claude 3.5、LLaMA-3.2、Qwen、Phi-3 等热门模型,发现:
在任务评价指标方面:
GPT-4o 逃脱成功率(ER)最佳,但在任务复杂度提升后仍频频出错;
国产大模型Doubao 1.5 Pro在最简单的关卡中,逃脱成功率超越Gemini 1.5 Pro和Claude 3.5 Sonnet;并且其交互成功率(Grab SR)超越GPT-4o和Claude 3.5 Sonnet;
即使模型逃脱成功率相同,EscapeCraft依然能利用道具获取率(Prop)、使用步数(Step),交互成功率(Grab SR)和交互率(Grab Ratio)对模型进行比较。
比如,在“Difficult-2”中,Gemini 1.5 Pro和Claude 3.5 Sonnet有相同的逃脱成功率和道具获取率,但是Gemini 1.5 Pro凭借较高的交互率,即使它的交互成功率较低,也能通过相对较少的步数成功逃脱;而Claude 3.5 Sonnet虽然交互率低,但每一步交互的成功率较高,体现出该模型完成任务时的“深思熟虑”。
在推理和探索行为方面:
Gemini 和 Claude 常在房间角落“卡住”,空间方向等判断失误,空转失败;
多数模型容易“反复抓错”或“认错道具”,他们的失败方式也各有特色:有的不会动、有的乱动、有的只移动不采取交互行动、有的动作对了但“目的不清”……;
子目标达成率虽高,但意图-结果一致性普遍低下,即“想要和沙发交互,但是意外地拿到钥匙”;
在多房间设定下,模型能从第一个房间学习到的逃脱经验有限,仅在两个房间关卡设定相似的条件下有辅助作用。
GitHub 地址:https://github.com/THUNLP-MT/EscapeCraft
论文原文:https://arxiv.org/abs/2503.10042v4
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
(文:量子位)