

henry 发自 凹非寺
量子位 | 公众号 QbitAI
Agent能力每7个月翻一番!
根据非营利研究机构METR最新发布的报告,这一规律已在9项基准测试中得到了验证。
这些任务涉及编程、数学、计算机使用、自动驾驶等领域,表明大模型正在不断向着高度自动化迈进。
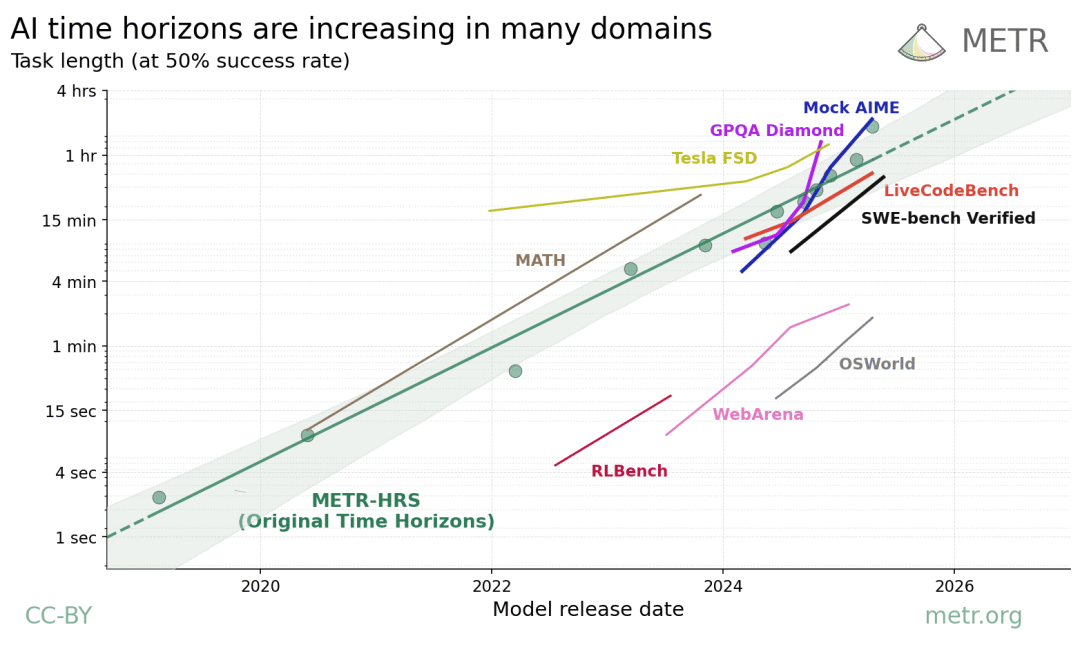
报告指出:在软件开发、数学竞赛、科学问答等任务中,agent已能完成相当于人类花费50–200分钟才能完成的任务,并且这种能力还在快速提升——大约每2–6个月就能翻一番。
在计算机操作任务中,虽然任务时长较短,但增长率与软件开发等任务一致。
Agent在自动驾驶任务的性能增长速度则较慢,约20个月翻一番。
在视频理解任务中,模型能够在时长1小时的视频上取得50%的成功率。
作为一家致力于研究前沿人工智能系统能力及其风险的研究团队,METR此次的报告又进一步拉近了AI自主化的时间线,快来和我们看看报告有哪些内容吧。
Agent的摩尔定律
在此前的测试中,METR将评估范围聚焦于软件开发和研究类任务,并发现AI agent的能力呈现出一种“摩尔定律”式的增长趋势——平均每七个月,其可完成任务的time horizon就会翻一番。
而在最新报告中,METR将这一评估方法拓展至更广泛的领域,并继续追问一个关键问题:AI的能力,是否能在更广泛的任务中,以time horizon翻倍的方式不断跃升?
不过我们首先要问的是,什么是time horizon?
举例来说,人类平均花30分钟完成一个任务,AI如果能在这类任务上有一半成功的概率,那就说它的time horizon是30分钟。如果它成功率还远高于一半,例如达到80%,那说明它其实能胜任更长、更复杂的任务。
概括地说,time horizon就是agent在任务上可稳定完成的时间跨度。
由于time horizon越长≈任务越难≈需要更多策略推理与计划能力≈智能体的智能水平越高,所以time horizon的翻倍也被称为agent的摩尔定律。
由于AI在不同任务中的能力差别极大,所以现在的问题是:这个指数级增长规律,会在其他领域也成立吗?
如何跨领域衡量time horizon?
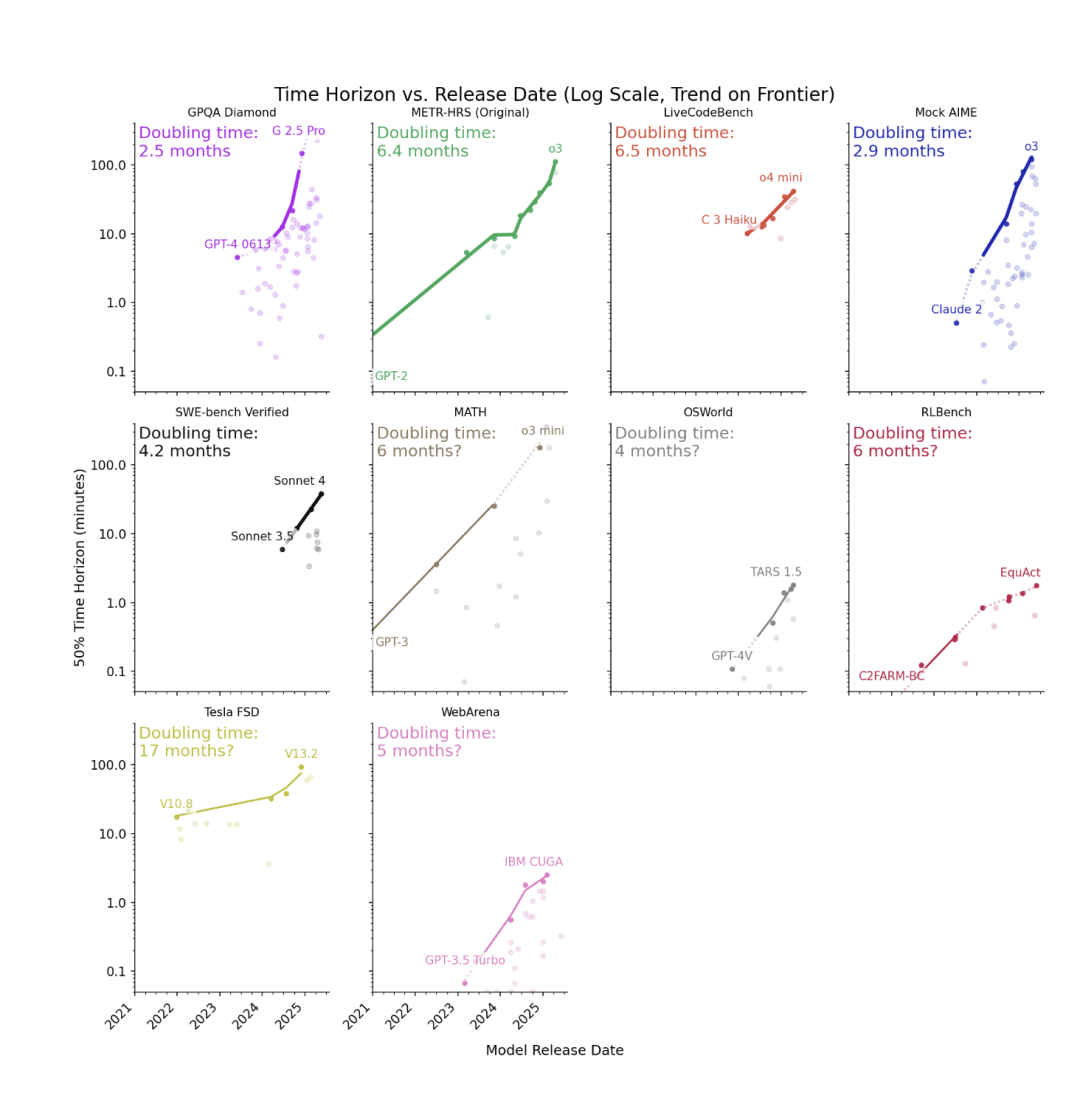
为了证明上面的问题,报告选取了9个benchmark,包括软件开发(METR‑HRS、SWE‑bench)、计算机使用(OSWorld、WebArena)、数学竞赛(Mock AIME、MATH)、编程竞赛(LiveCode-Bench)、科学问答(GPQADiamond)、视频理解(Video‑MME)、自动驾驶(Tesla FSD)和机器人仿真(RLBench)。
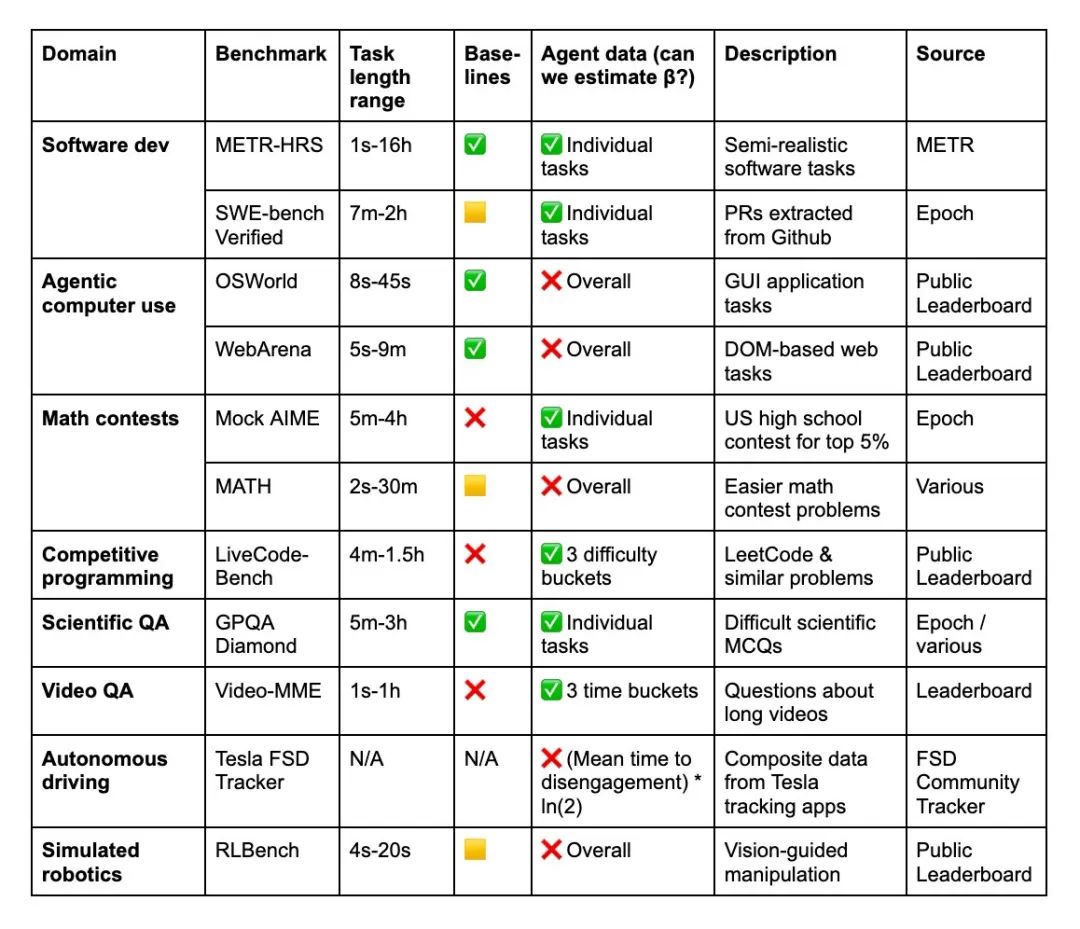
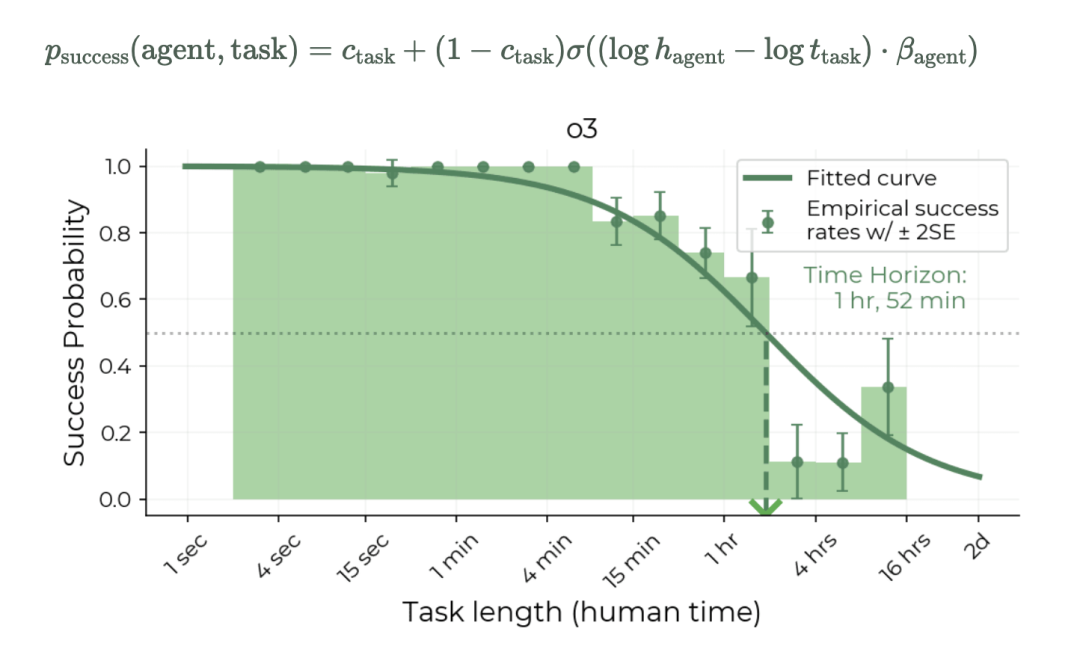
对每个benchmark,METR构造了概率模型来估算agent的time horizon。报告采用最大似然估计(MLE)或简化估计方法,处理不同benchmark的标签粒度以估算出每个领域AI随时间的time horizon增长曲线。
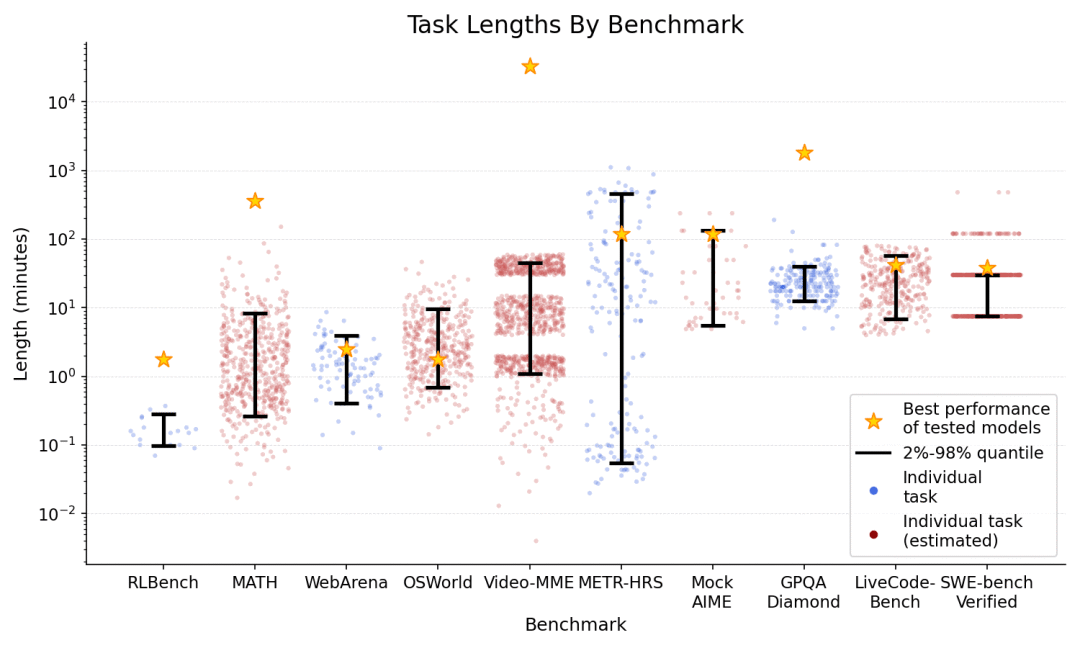
值得注意的是,不同基准测试的time horizon边界相差超过100倍。许多推理和编码基准测试的集群时间都在1小时或以上,但在计算机的使用时间(OSWorld、WebArena)仅为约2分钟,而这可能源于agent在使用鼠标时发生的误触。
研究发现:智能体能力按月翻番
除了我们开头提到的智能体的能力变化,报告还测试了当前主流的几家大模型的能力。例如,像o3这样的前沿模型在METR任务上的表现一直高于趋势水平,翻倍时间快于7个月,在9个基准测试的翻倍时间中位数约为4个月(范围为2.5至17个月)。
最后,time horizon并非对于所有的基础测试中都重要。由于有些基准中难题的难度要远大于简单题,而在另一些基准中,难题却和简单题相差无几。因此,对于agent来说,在这些基准测试中time horizon并不能完全反映其性能。
例如,LeetCode(LiveCodeBench)和数学问题(AIME)的难度要远高于简单问题,但长视频上的Video-MME问题并不比短视频上的难多少。
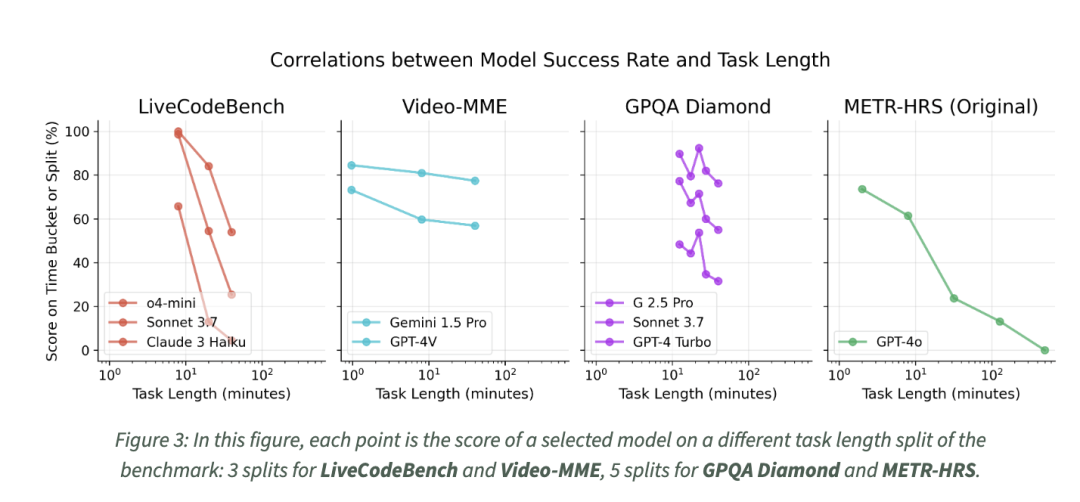
可见,agent的性能并不只是看“会更多技巧”,而是看是否能处理更长、更复杂任务。
从几秒、几分钟,到几十分钟、几小时,agent的可处理范围正在跨越级别提升;如果翻倍趋势持续,未来几年内可能看到AI完成“几天→几周”的任务成为可能。
总结这一研究可以看到一个很清楚的规律:从代码推理到数学竞赛,从GUI控制到自动驾驶,没有一个任务域显示出智能增长的“乏力”。在多数场景中,AI正全速向更大跨度、更深记忆、更复杂规划演进。
(文:量子位)