

0x0. 前言
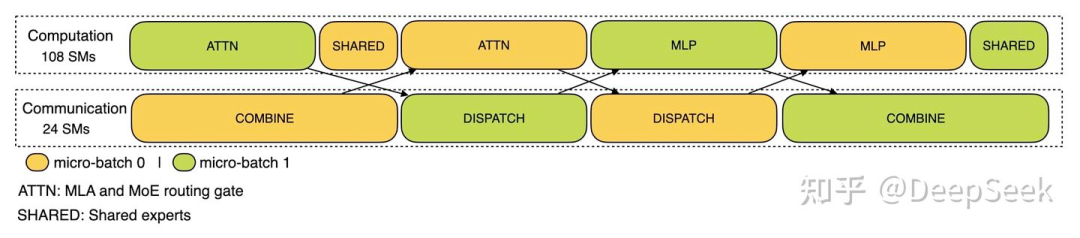
在DeepSeek V3的blog(https://zhuanlan.zhihu.com/p/27181462601) 中提到的TBO作用在Prefill阶段时,我们可以从它的调度图上看到对于计算的Stream使用了108个SM,而通信的Stream则使用了剩下的24个SM。之前一直比较好奇这个SM划分是怎么做到的,最近关注到Flashinfer引入了CUDA Green Context可以比较方便的来实现这个功能(要求CUDA 12.0+),所以这里就基于Flashinfer相关的实现来简单了解一下CUDA Green Context的实现。从NV论坛和CCCL的支持来看这个feature似乎也是处于实验阶段, 在CUDA-Samples里面也找不到例子,所以我这里的介绍只是起一个科普作用,可以关注后续的演进。
相关的PR为:https://github.com/flashinfer-ai/flashinfer/pull/1163
0x1. CUDA Green Context和普通Context的区别
根据CUDA Green Context的文档:https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__GREEN__CONTEXTS.html#group__CUDA__GREEN__CONTEXTS_1g6115d21604653f4eafb257f725538ab6
在CUDA 12.0+中引入了CUDA Green Context,它和普通Context的区别在于:
-
CUDA Green Contexts 提供了资源隔离功能,可以让每个上下文在执行时不干扰其他上下文,这对于需要高并发的任务尤为重要。 -
对于多线程的应用程序,CUDA Green Contexts 可以有效降低因上下文切换导致的性能损失,使得多线程的 CUDA 应用能更顺畅地运行。 -
通过在多个上下文之间进行并行处理,能够提高 GPU 的使用率,从而提升整体计算吞吐量。适合需要执行多个独立运算的场景。
普通的CUDA Context Stream无法实现资源隔离或要实现资源隔离需要做一些很tricky的魔法,并且普通的多Stream并行执行kernel的时候也容易因为某个kernel用满了SM导致无法overlap。可以参考https://mp.weixin.qq.com/s/Y6r-rjBEEN5akPHmx6jS3w 这里的cuda kernel执行和nsys图。而CUDA Green Context Stream可以通过划分SM实现资源隔离让overlap更容易做到,这是我的理解。
0x2. CUDA Green Context怎么用
FlashInfer中引入CUDA Green Context的代码就对应下面这个代码片段:
from typing import List, Tuple
import cuda.bindings.driver as driver
import cuda.bindings.runtime as runtime
import cuda.cudart as cudart
import cuda.nvrtc as nvrtc
import torch
from cuda.bindings.driver import CUdevice, CUdevResource
def _cudaGetErrorEnum(error):
"""获取CUDA错误枚举的名称字符串
Args:
error: CUDA错误对象,可能是driver、runtime或nvrtc的错误类型
Returns:
错误名称的字符串表示
"""
if isinstance(error, driver.CUresult):
# 处理CUDA Driver API错误
err, name = driver.cuGetErrorName(error)
return name if err == driver.CUresult.CUDA_SUCCESS else"<unknown>"
elif isinstance(error, runtime.cudaError_t):
# 处理CUDA Runtime API错误
return cudart.cudaGetErrorName(error)[1]
elif isinstance(error, nvrtc.nvrtcResult):
# 处理NVRTC编译错误
return nvrtc.nvrtcGetErrorString(error)[1]
else:
raise RuntimeError(f"Unknown error type: {error}")
def checkCudaErrors(result):
"""检查CUDA API调用的返回结果,如果有错误则抛出异常
Args:
result: CUDA API调用的返回结果,通常是一个元组
Returns:
如果没有错误,返回结果数据部分(去除错误码)
Raises:
RuntimeError: 如果CUDA调用出现错误
"""
if result[0].value:
# 如果错误码非零,说明有错误发生
raise RuntimeError(
f"CUDA error code={result[0].value}({_cudaGetErrorEnum(result[0])})"
)
# 根据返回结果的长度来决定返回什么
if len(result) == 1:
returnNone# 只有错误码,没有数据
elif len(result) == 2:
return result[1] # 返回数据部分
else:
return result[1:] # 返回多个数据项
def get_cudevice(dev: torch.device) -> CUdevice:
"""获取指定PyTorch设备对应的CUDA设备句柄
Args:
dev: PyTorch设备对象
Returns:
CUDA设备句柄
"""
try:
# 尝试直接获取CUDA设备
cu_dev = checkCudaErrors(driver.cuDeviceGet(dev.index))
except RuntimeError as e:
# 如果失败,先初始化设备再获取
runtime.cudaInitDevice(dev.index, 0, 0)
cu_dev = checkCudaErrors(driver.cuDeviceGet(dev.index))
return cu_dev
def get_device_resource(cu_dev: CUdevice) -> CUdevResource:
"""获取指定CUDA设备的SM(流处理器)资源
Args:
cu_dev: CUDA设备句柄
Returns:
设备的SM资源对象
"""
return checkCudaErrors(
driver.cuDeviceGetDevResource(
cu_dev, driver.CUdevResourceType.CU_DEV_RESOURCE_TYPE_SM
)
)
def split_resource(
resource: CUdevResource,
num_groups: int,
min_count: int,
) -> Tuple[CUdevResource, CUdevResource]:
"""将SM资源按指定数量分割成多个组
Args:
resource: 要分割的SM资源
num_groups: 要分割成的组数
min_count: 每组最少的SM数量
Returns:
分割后的资源组列表和剩余的资源
"""
results, _, remaining = checkCudaErrors(
driver.cuDevSmResourceSplitByCount(
num_groups, # 分组数量
resource, # 原始资源
0, # useFlags - 使用标志,0表示默认
min_count, # 每组最小SM数量
)
)
return results, remaining
def create_green_ctx_streams(
cu_dev: CUdevice, resources: List[CUdevResource]
) -> List[torch.Stream]:
"""为每个SM资源组创建对应的Green Context和Stream
Args:
cu_dev: CUDA设备句柄
resources: SM资源组列表
Returns:
对应每个资源组的PyTorch Stream列表
"""
streams = []
for split in resources:
# 为每个分割的资源创建描述符
desc = checkCudaErrors(driver.cuDevResourceGenerateDesc([split], 1))
# 创建Green Context,这是CUDA 12.0+的新特性
# Green Context允许在不同的SM分区上并发执行多个kernel
green_ctx = checkCudaErrors(
driver.cuGreenCtxCreate(
desc, # 资源描述符
cu_dev, # 设备句柄
driver.CUgreenCtxCreate_flags.CU_GREEN_CTX_DEFAULT_STREAM # 创建标志
)
)
# 在Green Context中创建Stream
stream = checkCudaErrors(
driver.cuGreenCtxStreamCreate(
green_ctx, # Green Context
driver.CUstream_flags.CU_STREAM_NON_BLOCKING, # 非阻塞Stream
0, # priority - 优先级,0表示默认
)
)
# 将CUDA Driver API的Stream转换为PyTorch的Stream
streams.append(torch.cuda.get_stream_from_external(stream))
return streams
def split_device_green_ctx(
dev: torch.device, num_groups: int, min_count: int
) -> Tuple[List[torch.Stream], List[CUdevResource]]:
r"""
将设备分割成多个Green Context,为每个组和剩余的SM返回对应的Stream和资源。
Green Context允许在不同的SM分区上并发执行多个kernel。
Args:
dev: 要分割的设备
num_groups: 要分割成的组数
min_count: 每组所需的最少SM数量,会根据对齐和粒度要求进行调整
Returns:
streams: 对应于Green Context的torch.Stream对象列表
resources: 对应于Green Context的CUdevResource对象列表
Example:
>>> from flashinfer.green_ctx import split_device_green_ctx
>>> import torch
>>> dev = torch.device("cuda:0")
>>> streams, resources = split_device_green_ctx(dev, 2, 16)
>>> print([r.sm.smCount for r in resources])
[16, 16, 100]
>>> with torch.cuda.stream(streams[0]):
... x = torch.randn(8192, 8192, device=dev, dtype=torch.bfloat16)
... y = torch.randn(8192, 8192, device=dev, dtype=torch.bfloat16)
... z = x @ y
... print(z.shape)
...
torch.Size([8192, 8192])
Note:
返回的streams和resources的长度为 ``num_groups + 1``,
其中最后一个是剩余的SM。
Raises:
RuntimeError: 当请求的SM分配超过设备容量时:
``num_groups * round_up(min_count, 8) > num_sm``
"""
# 1. 获取CUDA设备句柄
cu_dev = get_cudevice(dev)
# 2. 获取设备的SM资源
resource = get_device_resource(cu_dev)
# 3. 将SM资源分割成指定数量的组
results, remaining = split_resource(resource, num_groups, min_count)
# 4. 将分割的结果和剩余资源合并成一个列表
resources = results + [remaining]
# 5. 为每个资源组创建对应的Green Context和Stream
streams = create_green_ctx_streams(cu_dev, resources)
return streams, resources
可以看到这个CUDA Green Context的使用相对还是比较简单的,主要就是通过cuDevResourceGenerateDesc来生成资源描述符,然后通过cuGreenCtxCreate来创建Green Context,最后通过cuGreenCtxStreamCreate来创建CUDA Green Context的Stream。
用法也比较简单,可以参考这里的单测代码:
@pytest.mark.parametrize("device", ["cuda:0"])
@pytest.mark.parametrize("num_groups", [1, 2, 3])
@pytest.mark.parametrize("min_count", [16, 32])
def test_green_ctx_kernel_execution(
device: str,
num_groups: int,
min_count: int,
):
streams, resources = green_ctx.split_device_green_ctx(
torch.device(device), num_groups, min_count
)
num_partitions = num_groups + 1
assert len(streams) == num_partitions
assert len(resources) == num_partitions
for stream in streams:
with torch.cuda.stream(stream):
x = torch.randn(8192, 8192, device=device, dtype=torch.bfloat16)
y = torch.randn(8192, 8192, device=device, dtype=torch.bfloat16)
z = x @ y
print(z.shape)
这个用法只是展示了一下怎么利用FlashInfer的CUDA Green Context来实现SM的分割和创建多Streams,并没有看到如何利用CUDA Green Context来实现kernel overlap相关例子。我尝试使用这里提供的api来实现一个没有依赖的M,N,K=8192,8192,8192的torch.matmul和torch.sigmoid的kernel overlap,使用10个SM做torch.sigmoid,剩下的SM做torch.matmul。但是测试之后发现这个性能相比于baseline直接顺序执行的版本反而耗时高了快2倍,不确定是不是FlashInfer CUDA Green Context这里的打开方式不正确,之后有这个feature的发展或者相关应用的话继续关注一下。
(文:GiantPandaCV)