
近期,Google DeepMind研究者的一个工作引起了广泛讨论。
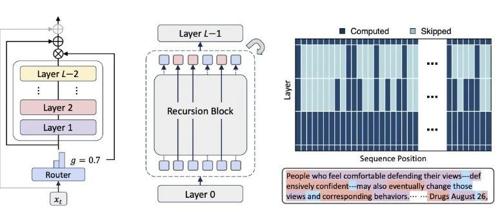
研究者们设计了一种很聪明的语言模型,它在处理一句话时,能像人一样判断哪些词更关键、需要“多想一想”(也就是进行更深度的递归计算)。
其次,它通过一个轻量级的“路由器”来决定让每个词在共享的网络模块里“循环”几次,对简单的词就少算几次,这样不仅让模型参数更少,也大大节省了计算资源。
最终的结果非常惊人:在同等训练成本下,这种“会思考”的模型表现显著优于传统模型,用更小的模型尺寸和更少的计算量,就达到了甚至超过了更大模型的性能。
有海外研究者评论道:

是否有其他思路来解决动态算力分配的问题呢?
我们使用秘塔深度研究:【传统Transformer模型的一个问题是针对每一个token消耗了固定的计算量,有什么其他的模型或算法是根据生成的难度动态进行算力分配的?】
下面是它的研究过程,生成了动态“问题链”:
https://metaso.cn/s/6MxpcgU
从它的报告中,还能发现很多其他解决该问题的比较有意思的思路,比如:
-
《D-LLM: A Token Adaptive Computing Resource Allocation Strategy for Large Language Models》 提出了一种根据token难度动态分配计算资源的机制,是目前少见直接对标“token-level算力分配”的工程方案,对推理效率影响很大。
-
《Mixture-of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models》 则来自DeepMind,和我一开始看的那篇Mixture-of-Recursions有异曲同工之妙——它也让每个token根据复杂度决定“走多深”,并从架构层面优化了整个计算图,很多细节值得深入对比。
-
《Leap-of-Thought: Accelerating Transformers via Dynamic Token Routing》 给我另一个角度的启发:不仅可以在深度上动态分配,也可以在token路径选择上做智能“路由”,将token引导到不同计算分支上,从而节省整体推理资源。
下面是最终生成的互动网页报告:

上下滑动可查看完整内容
(文:PaperAgent)