

今天是2025年7月18日,星期五,北京,晴。
今天继续看Agent进展,回到大模型调用工具能力的话题。
这个话题分成两个:
一个是数据层,训练数据占啥样,代表的中文数据有哪些;
一个是实践层,有了这个数据,是怎么拼接成prompt的,可以使用什么工具进行训练,loss可以怎么变。
这都是很具体的实践问题,做个记录。
一、代表性的Agent-tool use训练数据集
可以归纳一下中文agent的tool-use训练数据。
1、MSAgent-Bench-中文Agent数据集
MSAgentBench数据集,包括598k的训练集和对应的验证集,测试集,数据集主要包括四种:AI模型API,通用API,API无关通用sft数据,API检索增强数据。
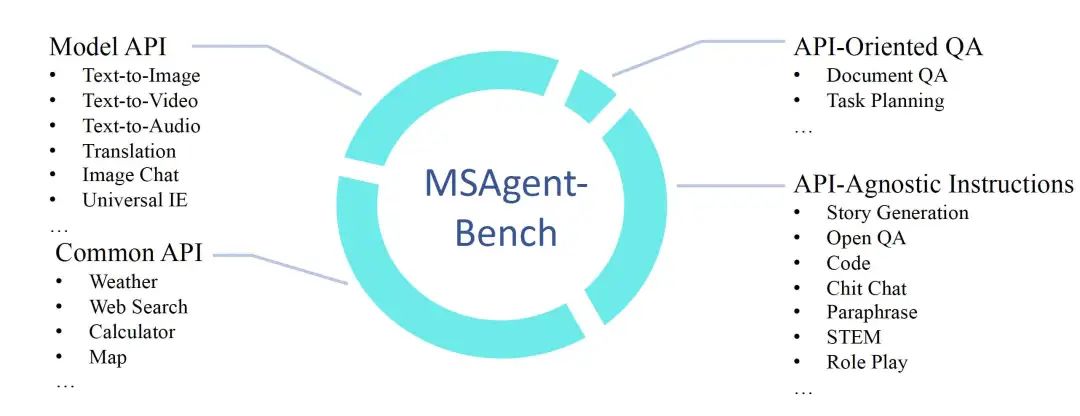
数据的样例子如下:

此外,其中关于怎么评估,比较重要,可以看下:
插件调用的准确率,评估api_name后面的是否正确;
插件url的准确率,评估url的地址是否正确;
插件传入参数的准确率,评估parameters对应的参数是否正确;
插件整体的准确率,评估生成的function calling是否完全正确,整个json可以被load的格式。
地址在:https://www.modelscope.cn/datasets/iic/MSAgent-Bench
2、MSAgent-Bench(React版)
MSAgent-Bench(React版)是MSAgentBench的react版本,可以兼容react格式的tool learning使用。
数据格式为每行一个样本,里面包含了id和converstions两个字段,其中conversations里面包含了system,user,assistant三种字段。

其中:
system表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
user表示用户的输入prompt,分为两种,通用生成的prompt和调用插件需求的prompt
地址在:https://www.modelscope.cn/datasets/iic/ms_agent
二、代表性的Agent-tool use训练工具
当有了数据集之后,那么就可以展开训练,而训练这块,目前也已经高度小白化了,典型的,关于Agent工具调用tooluse能力训练实践,可以看swift平台,有具体的介绍,地址在:https://swift.readthedocs.io/zh-cn/latest/Instruction/Agent%E6%94%AF%E6%8C%81.html,可以进行文本Agent和多模态Agent的训练。
这里整理出来,看几项细节:
1、关于训练数据
数据上,核心就是tools,message以及对应的agent template,其中tools是对工具信息的描述。agent template就是训练时候的常用template,用来组装prompt,详细说明如下:

其中,template很多样,不同的模型可以不同,如:https://github.com/modelscope/ms-swift/blob/main/swift/plugin/agent_template/init.py
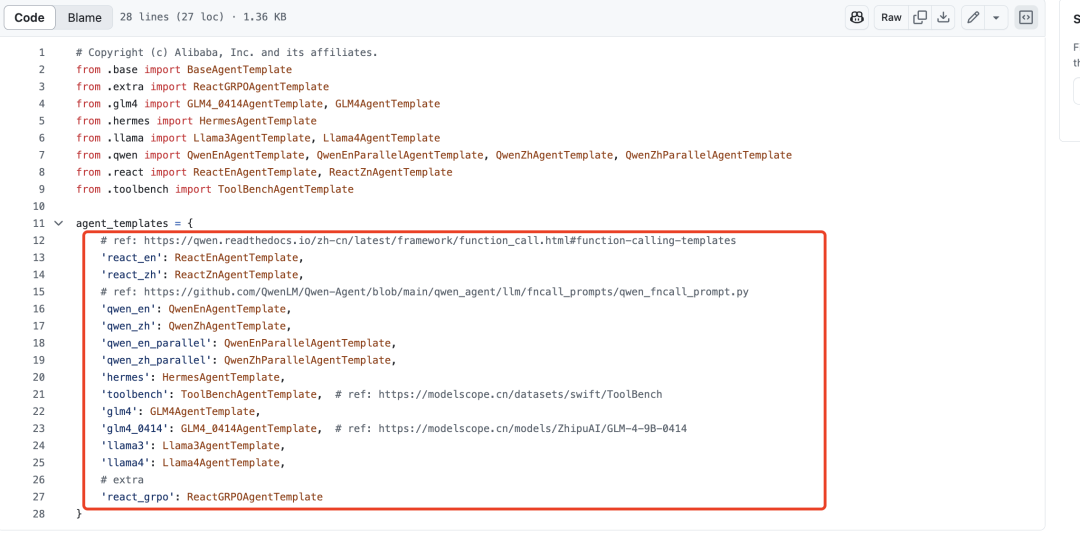
例如,hermes:https://github.com/modelscope/ms-swift/blob/main/swift/plugin/agent_template/hermes.py
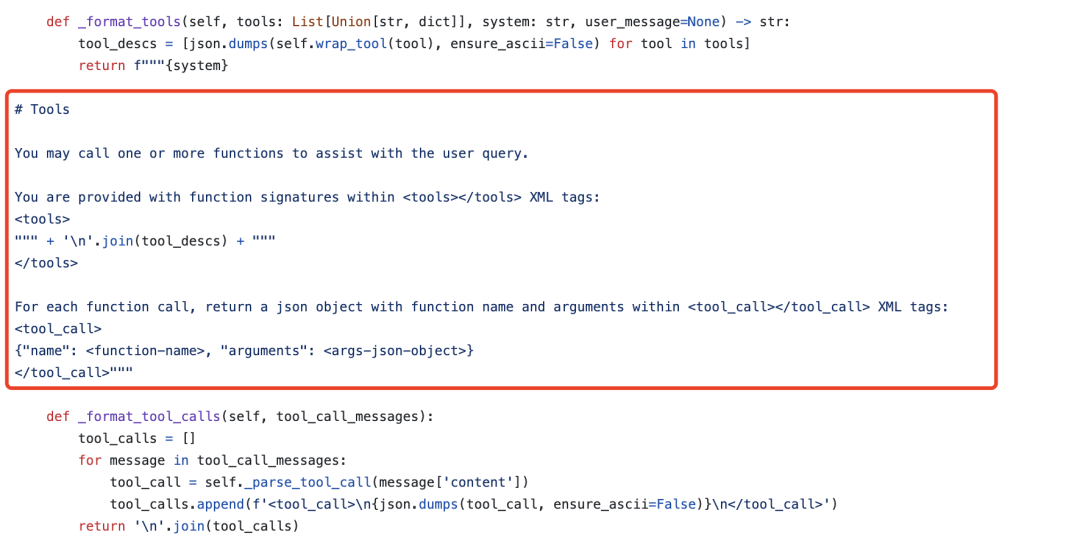
另一个就是tool的定义,其中会设定tools的一些信息,包括名称等,例如:

但是,一旦tool很多,就会造成上下文爆炸,上下文很长、很长。
基于这些细节信息,我们来看几个例子:
1)文本Agent的训练数据

agent_template为hermes,序列化为prompt为:
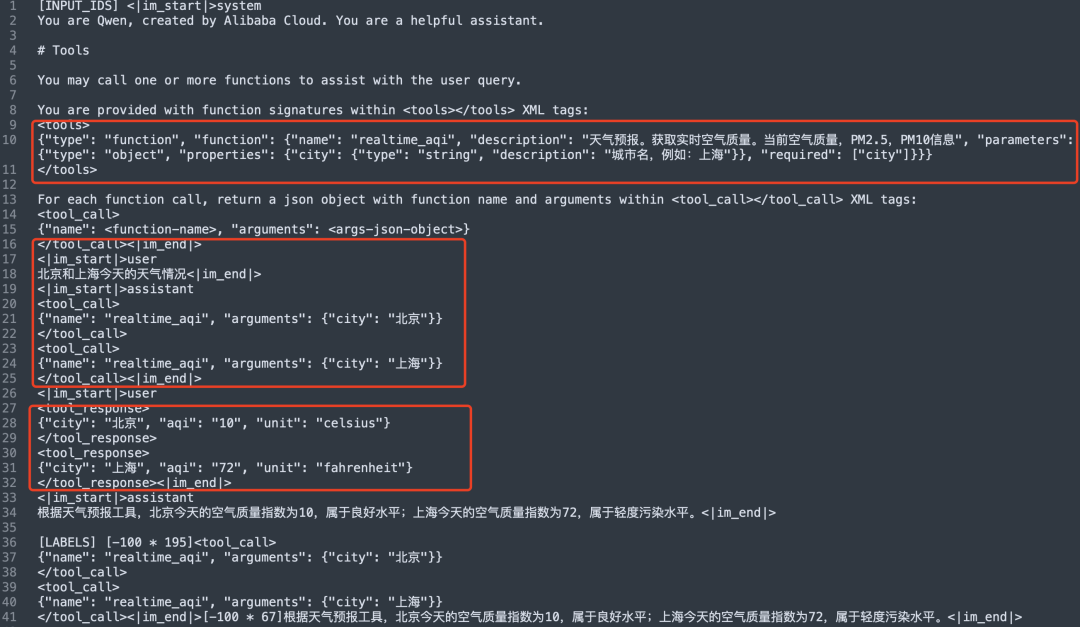
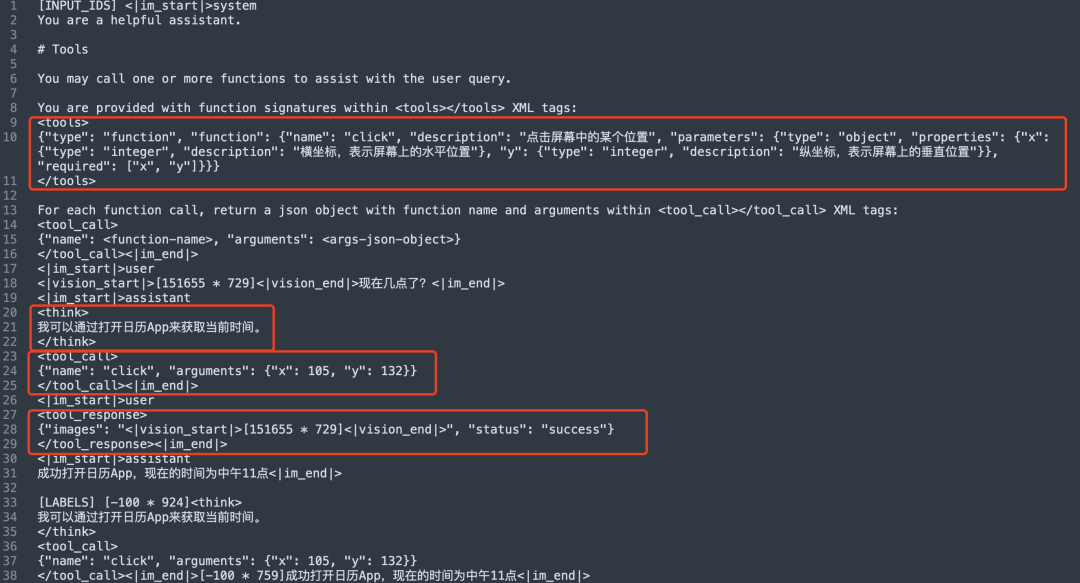
2)多模态Agent的训练数据

agent_template为hermes,序列化为prompt为:
3、关于loss计算的设定
在训练的过程中,除了数据之外,最重要的就是loss的设定了。
loss_scale可以对模型输出部分的训练损失权重进行调节,例如在ReACT格式中,可以设置–loss_scale react。
{"Action:": [2.0, 2.0], "Action Input:": [2.0, 2.0], "Thought:": [1.0, 1.0], "Final Answer:": [1.0, 1.0], "Observation:": [2.0, 0.0]}
也就是:
‘Thought:’和’Final Answer:’部分权重为1,’Action:’和’Action Input:’部分权重为2,’Observation:’字段本身权重为2,’Observation:’后面的工具调用结果权重为0。
这个的逻辑是:loss_scale机制在SWIFT中是非常重要的机制之一,在pretrain和sft任务中,可训练token的loss是均匀的,即每个token平等的进行bp,但在某些情况下,某些token的权重比较大,需要被额外关注, 在这种情况下就需要更高的权重,所以可以进行指定。
参考文献
1、https://swift.readthedocs.io/zh-cn/latest/Instruction/Agent%E6%94%AF%E6%8C%81.html
2、https://www.modelscope.cn/datasets/iic/MSAgent-Bench
3、https://www.modelscope.cn/datasets/iic/ms_agent
(文:老刘说NLP)