
大语言模型在写作时有着奇特的「口头禅」!

来自佛罗里达州立大学的研究人员最近发表了一项有趣的研究,他们分析了52亿个词汇单元,揭露了一个令人意外的现象:在科学写作中,某些词汇的使用频率突然暴增,而元凶竟然是大语言模型!
科学家的重大发现
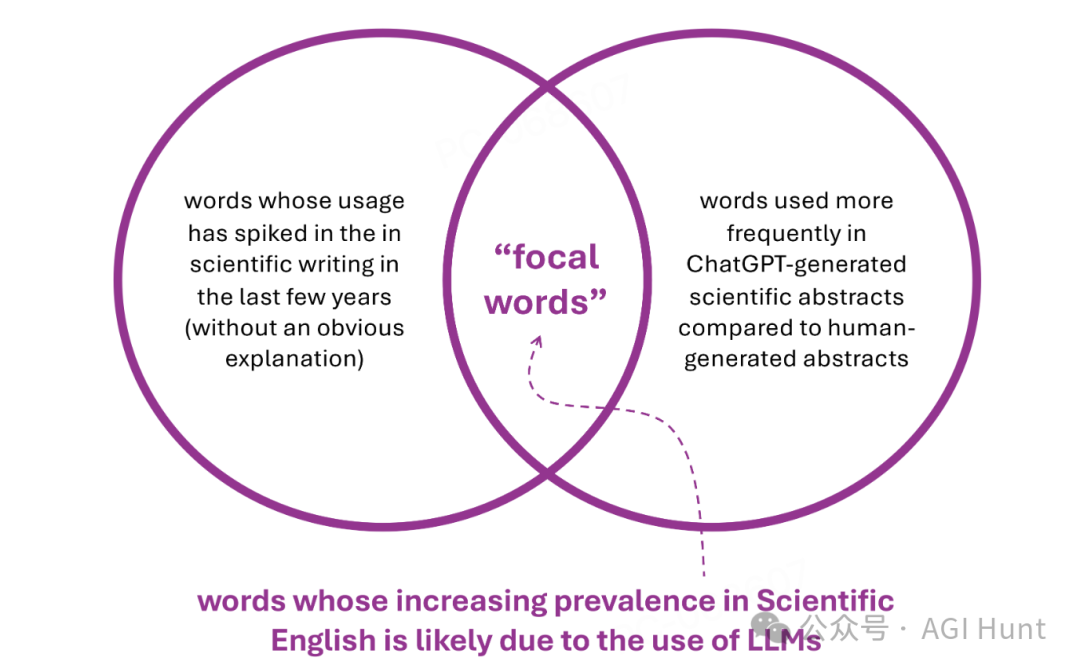
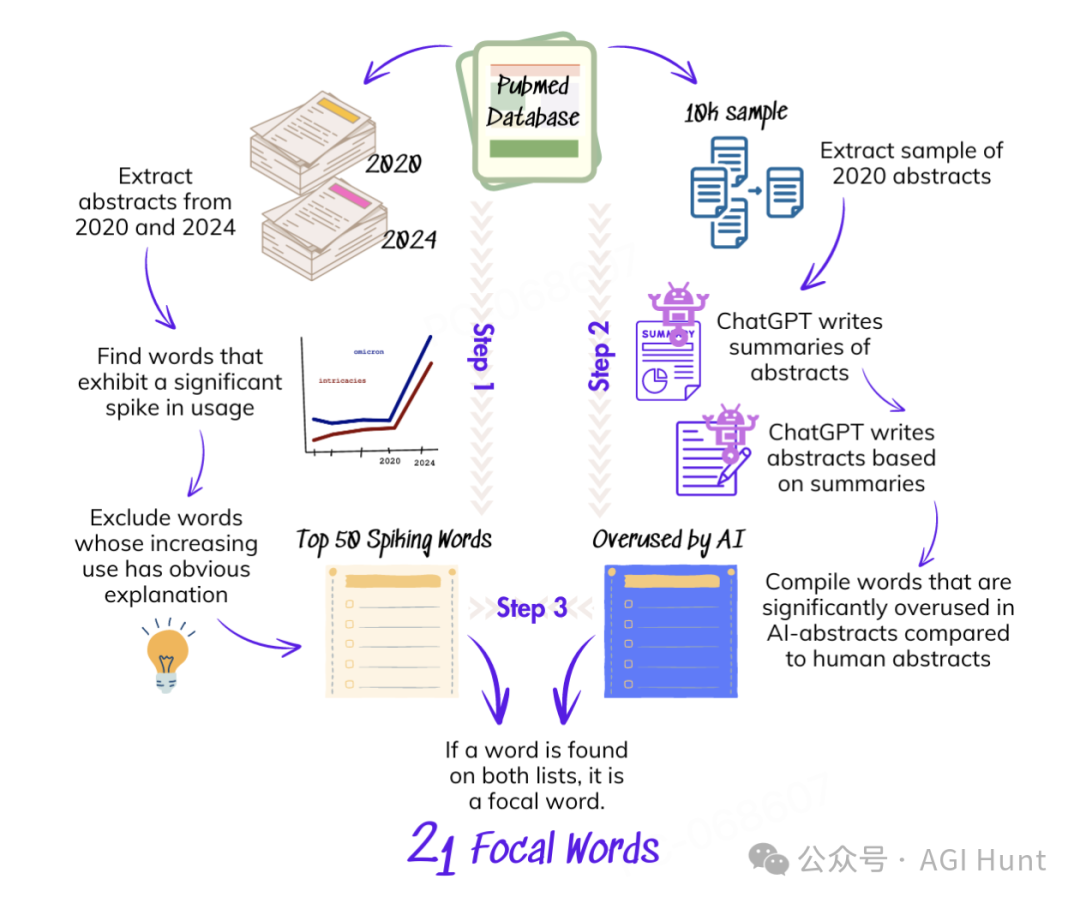
研究团队对2670万篇PubMed论文摘要进行了深入分析,通过一个三步走的研究方法,他们锁定了那些自2020年以来使用频率显著增加的词汇。
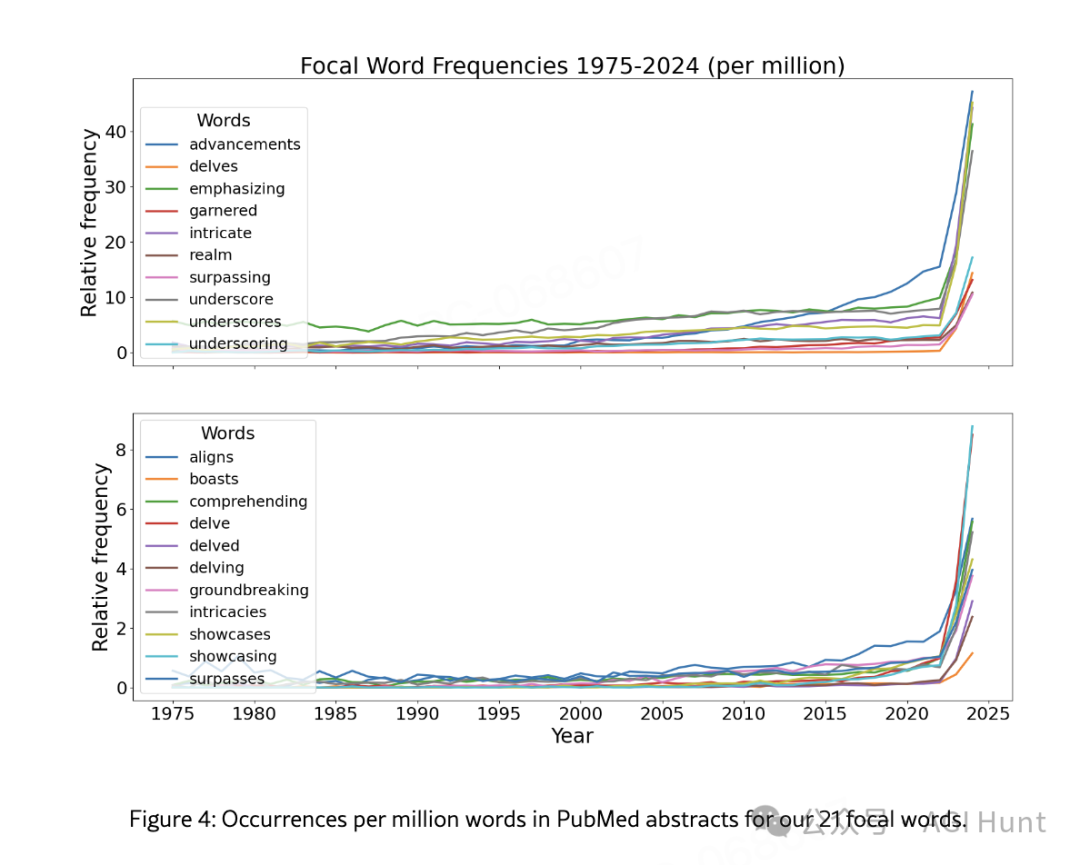
研究发现,像「delve」(深入探讨)、「intricate」(错综复杂的)和「underscore」(强调)这样的词汇,在科学论文中的出现频率突然暴增。

而这种现象与科研人员开始使用大语言模型写作的时间点惊人地吻合!
为什么会这样?
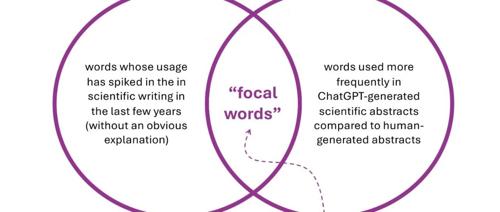
研究人员提出了一个有趣的问题:为什么大语言模型会偏爱这些特定词汇呢?
他们对可能的原因进行了全面调查:
-
模型架构问题?
-
算法选择的影响?
-
训练数据的偏差?
但有意思的是,这些常见的「嫌疑人」都被排除了!

反而是人类反馈强化学习(RLHF)浮出水面,成为最有可能的「幕后推手」。研究者猜测,这可能与人类评估者的某些潜在偏好有关。
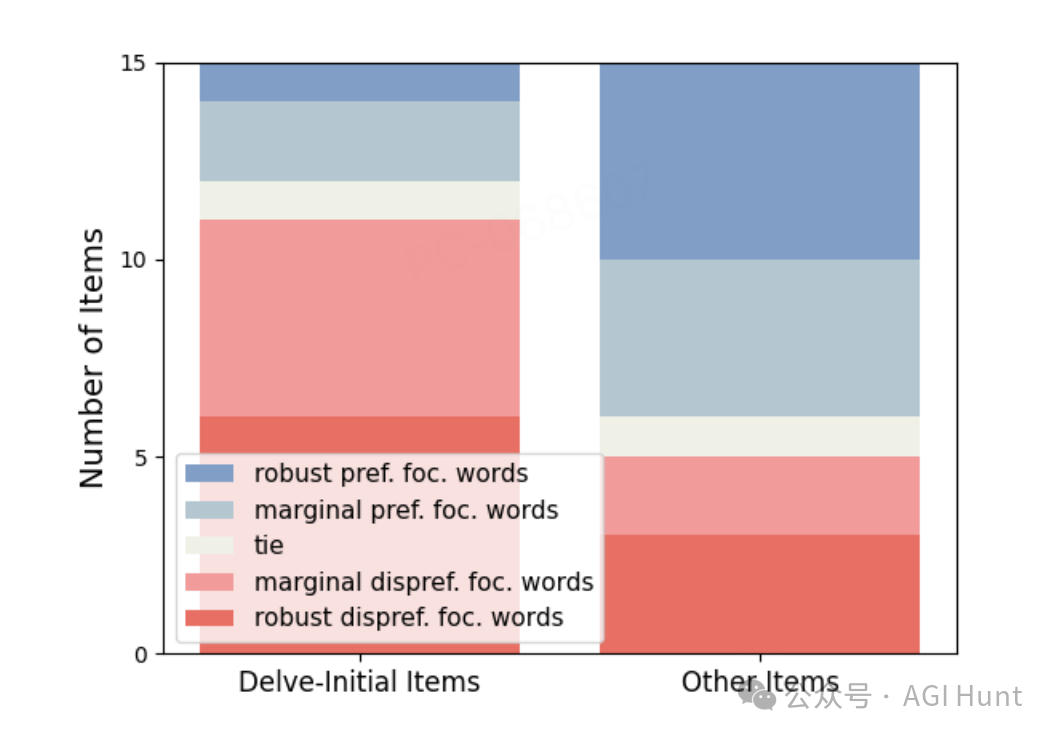
「词汇过载」的影响
这项研究揭示了一个令人深思的现实:大语言模型正在悄然改变全球语言使用习惯。
研究团队成功识别出了21个焦点词,这些词汇在科学写作中的使用频率出现了前所未有的增长。更重要的是,这种现象在最新的大语言模型中仍然存在。
不过,研究人员也指出了一个遗憾:由于大语言模型开发过程缺乏透明度,很多深层次的问题仍然无法得到彻底调查。
通过这项研究,我们第一次清晰地看到了AI对人类语言使用习惯的潜移默化影响。
值得让人思考的是:
当我们使用AI辅助写作时,是否也在不经意间被AI 改变了自己?
论文链接:https://arxiv.org/abs/2412.11385
(文:AGI Hunt)