
2023年是生成式AI的元年,基座模型领域,OpenAI凭借先发优势独占鳌头,一家独大,LLM应用也多为简单的‘套壳’模式。然而,到了2024年,生成式AI领域便进入了蓬勃发展期,特别是下半年,基座模型领域呈现出百花齐放的态势:Anthropic、Google,乃至国内的阿里巴巴、DeepSeek等纷纷崛起,在性能上追平甚至赶超OpenAI。与此同时,大模型应用也开始迈入‘智能体’(Agent)时代,越来越多的AI应用正加速落地,尤其是在AI编程领域,更是率先展现出巨大的潜力。近日,知名技术博主Simon Willison在其博客文章《LLMs in 2024》中,对过去这波澜壮阔、具有里程碑意义的一年进行了深入盘点,我们来一起回顾:
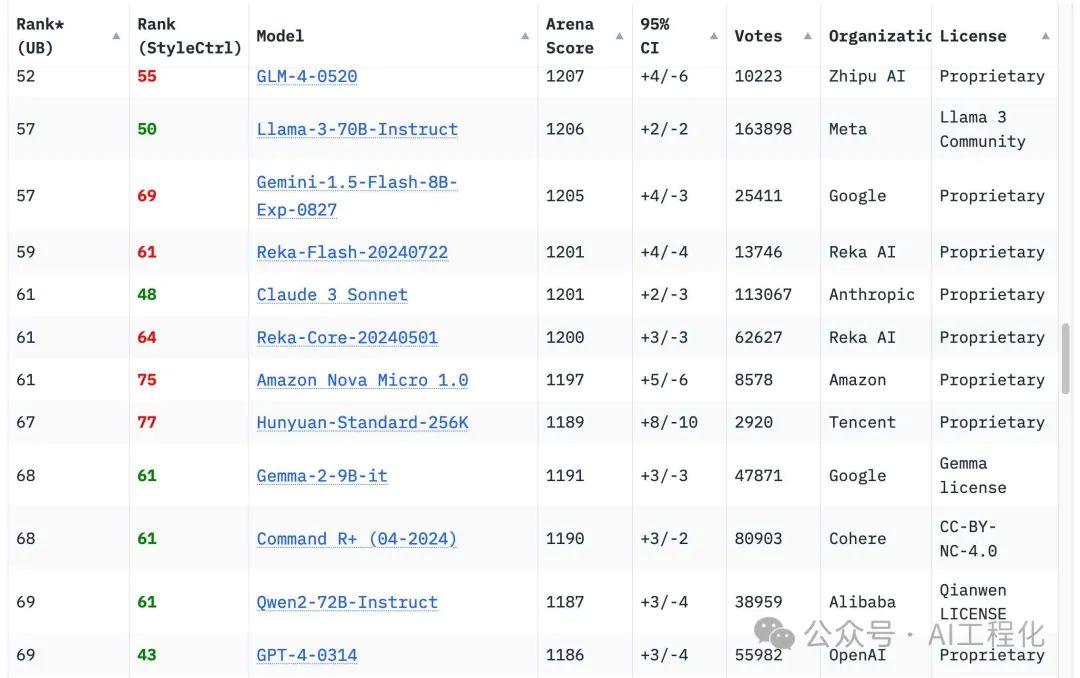
1. GPT-4 壁垒的瓦解(The GPT-4 barrier was comprehensively broken): 2023年,复现GPT-4 似乎是无法企及的梦想,仿佛OpenAI掌握着不为人知的秘诀。但2024年,这种局面被彻底打破。Chatbot Arena排行榜上,18个机构的70个模型纷纷超越了初代GPT-4,宣告了技术上的巨大跃迁。谷歌的Gemini 1.5 Pro率先突围,不仅在性能上比肩GPT-4,更以其百万甚至两百万token的超长上下文输入能力和视频输入功能,极大地拓展了LLM的应用场景。Anthropic的Claude 3系列也表现不俗,其中Claude 3.5 Sonnet更是凭借其出色的表现,成为许多人的日常首选。曾经被视为难以逾越的GPT-4,如今已不再是神话,这背后是众多机构共同努力和技术快速进步的体现。
2. 笔记本上的 GPT-4 级模型(GPT-4 class models run on my laptop): 令人难以置信的是,我2023年的M2 MacBook Pro笔记本电脑,这台去年年初还只能勉强运行GPT-3级别模型的设备,现在居然能流畅运行多个GPT-4级别的模型,例如Qwen2.5-Coder-32B和Meta的Llama 3.3 70B。这标志着模型训练和推理效率在过去一年中取得了飞跃性的进步。曾经需要数据中心服务器才能运行的模型,现在可以在个人设备上轻松运行,这充分体现了技术进步的巨大潜力。Meta的Llama 3.2系列也值得特别关注,其中1B和3B模型以其小巧的体积,却展现出超越预期的惊人性能。我甚至可以在我的iPhone上使用MLC Chat应用运行3B模型,它能够以每秒20个token的速率生成文本,比如关于“数据记者爱上陶艺家的圣诞电影情节”,这展示了小型化模型同样具有巨大潜力。
3. LLM 价格的暴跌(LLM prices crashed): 过去一年,顶级托管LLM(hosted LLMs)的价格出现了戏剧性的下降。OpenAI的GPT-4,曾经高达30美元/百万token,现在只需要2.5美元/百万token,而GPT-4o mini更是降至惊人的0.15美元/百万token。其他供应商的价格更具竞争力,例如谷歌的Gemini 1.5 Flash仅为0.075美元/百万token。这种价格暴跌源于市场竞争加剧和模型效率的显著提升。这不仅降低了LLM的使用成本,也大幅减少了运行提示所需的能源,对环境保护起到了积极作用。以我的个人经验为例,使用谷歌的Gemini 1.5 Flash 8B为我68000张照片生成描述,成本仅需1.68美元,这样的价格在去年是无法想象的。
4. 多模态应用的兴起(Multimodal vision is common): 多模态LLM(Multimodal LLMs)已成为2024年的重要趋势。如果说一年前,GPT-4 Vision还算是多模态的代表,那么今年几乎所有主要的模型供应商都推出了自己的多模态模型,包括Anthropic的Claude 3系列、谷歌的Gemini 1.5 Pro(支持图像、音频和视频输入)、Qwen2-VL、Mistral的Pixtral 12B以及Meta的Llama 3.2视觉模型等。为了更好地利用这些模型,我升级了自己的LLM CLI工具,使其可以通过附件支持多模态输入。很多人抱怨LLM的进步速度放缓,但他们可能忽略了多模态模型领域的巨大进步。能够利用图像、音频和视频等多种模态的输入,为LLM的应用场景打开了全新的可能性。
5. 语音和实时摄像头模式的突破(Voice and live camera mode): 音频和实时视频模式的出现堪称科幻照进现实。OpenAI在2023年推出了ChatGPT的语音功能,但那时的实现方式仅仅是将语音转为文本(speech-to-text)再进行处理。而今年5月发布的GPT-4o真正实现了多模态音频输入和输出,不再需要单独的语音转文本和文本转语音(text-to-speech)模型。虽然Skye的演示声音因为酷似斯嘉丽·约翰逊而未能发布,但随后推出的ChatGPT高级语音模式依然非常出色,它不仅能够通过语调的细微变化来提升表达力,甚至能够模仿不同的口音。更令人兴奋的是实时视频模式,ChatGPT和Google Gemini都支持将手机摄像头实时拍摄的画面发送给模型,并即时进行讨论和分析。这些新功能虽然才刚刚出现,但预示着LLM在人机交互领域具有巨大的潜力。
6. 提示驱动应用生成的普及(Prompt driven app generation): 2024年,我们惊喜地发现LLM可以通过提示构建完整的交互式Web应用。Anthropic的Claude Artifacts功能允许用户直接在Claude界面内使用LLM生成的交互式应用。例如,我仅仅通过简单的提示就利用Claude生成了一个“提取URL”的应用,并在随后一周内,用类似的方法搭建了14个小工具,这充分说明了该功能的强大和便捷性。其他公司,如GitHub、Mistral Chat等也推出了类似的功能。Chatbot Arena团队甚至专门为此类应用推出了新的排行榜,这表明提示驱动应用生成已经成为一个普遍的功能,可以有效地应用于各种主流模型。作者正在Datasette项目中尝试类似的功能,希望用户可以通过提示构建自定义的组件和数据可视化界面。这种通过提示生成自定义界面功能如此强大且易于构建,预计在2025年,它将广泛出现在各种产品中。
7. 最佳模型免费访问的短暂窗口(Universal access to the best models): 今年有几个月,我们迎来了GPT-4o、Claude 3.5 Sonnet和Gemini 1.5 Pro这三大顶尖模型的免费访问期。OpenAI在5月份向所有用户免费开放GPT-4o,而Claude 3.5 Sonnet在6月份发布时也是免费使用的。这对于那些过去只能使用GPT-3.5级别模型的用户而言,无疑是一个福音,他们终于可以体验到真正强大的LLM的能力。然而,随着OpenAI推出ChatGPT Pro订阅服务,只有每月支付200美元的用户才能访问最强大的模型o1 Pro,免费访问顶尖模型的时代似乎已经结束。由于o1系列模型(以及未来类似模型)的核心思想在于通过消耗更多的计算资源来获得更出色的性能,免费访问顶尖模型可能将成为历史。
8. “智能体”概念的迷雾(“Agents” still haven’t really happened yet): “智能体” (agents)这个词汇如今已经被过度滥用,它缺乏明确的定义,而且相关技术的发展也面临诸多挑战。对于“智能体”,人们主要有两种理解:一种是认为智能体可以代表用户自主行动,比如像一个旅行社;另一种则认为智能体是能够使用各种工具并循环运行解决问题的系统。无论如何定义,我们都必须正视其“轻信”(gullibility)的弱点。LLM会相信我们告诉它的任何事情,所以一个不能区分真假信息的智能体如何能够可靠地为我们做决策呢?提示注入(prompt injection)问题依然是一个亟待解决的难题,尽管我们从2022年就开始讨论,但2024年仍然没有看到明显的进展。因此,我倾向于认为,我们所设想的“智能体”可能只有等到通用人工智能(AGI)出现时才能实现。
9. 评估的重要性(Evals really matter): 2024年,我们更加清楚地认识到,对于LLM驱动的系统,良好的自动化评估至关重要。正如Anthropic的Amanda Askell所说,好的系统提示背后的秘密是“测试驱动开发”。这意味着我们应该先定义测试,然后寻找一个能够通过这些测试的系统提示。拥有强大的评估套件,能够帮助我们更快地采用新模型、更好地迭代,并构建比竞争对手更加可靠和实用的产品功能。Vercel的Malte Ubl也强调了评估的重要性。尽管如此,如何更好地实施评估仍然缺乏指导,这也是我一直在努力解决的问题。
10. “苹果智能”的落后(Apple Intelligence is bad): 作为一名Mac用户,我对于Apple的MLX库的推出感到非常满意,它使得在Mac设备上运行LLM模型变得更加高效。但同时,我也对Apple的“Apple Intelligence”功能感到失望。尽管Apple在保护用户隐私和防止误导方面做出了努力,但这些功能与前沿LLM的能力相比,仍然显得非常薄弱。作为一名经常使用LLM的资深用户,我非常清楚这些模型的能力,而Apple的LLM功能仅仅是前沿LLM的苍白模仿,这让人感到非常遗憾。
11. 推理规模扩展模型的出现(Inference-scaling “reasoning” models): 2024年最后一个季度,以OpenAI的o1模型为代表,出现了一种新型的LLM,开启了模型发展的新方向。这些模型不再仅仅依赖于大量的训练数据和计算资源,而是将“思维链”(chain-of-thought)提示技巧融入模型本身。它们在推理过程中会“说出来”,这其实是在消耗更多的计算资源来解决更复杂的问题。谷歌、Alibaba和DeepSeek等公司也纷纷发布了类似的模型。这种推理时缩放定律(inference scaling)为LLM的未来发展提供了新的思路。
12. 中国模型的崛起(Was the best currently available LLM trained in China): DeepSeek v3的发布是2024年末最值得关注的新闻之一。这是一个拥有6850亿参数的巨大模型,其性能可与Claude 3.5 Sonnet媲美。更令人印象深刻的是,它的训练成本仅为557.6万美元,这远低于其他类似的模型。这表明中国在LLM训练技术方面取得了显著进展。或许正是美国对中国出口GPU的限制,反而激发了中国工程师在训练优化方面的巨大创造力。
13. 单个提示的能源消耗减少(The environmental impact got better): 得益于模型效率的不断提高,无论是托管模型还是可以在本地运行的模型,其能源消耗和环境影响都在过去几年中显著下降。OpenAI现在的提示费用仅为GPT-3时代的百分之一,这充分说明了效率提升的巨大作用。Google Gemini和Amazon Nova的提示费用也并不亏本,这表明LLM服务在经济上是可行的。这意味着,对于大部分的个人使用场景,我们完全没有必要为LLM的能源消耗而感到内疚。
14. 大规模基础设施建设对环境的影响(The environmental impact got much, much worse): 虽然单个提示的能源消耗减少,但为支持LLM模型所进行的巨大规模基础设施建设对环境的影响依然不容忽视。谷歌、Meta、微软和亚马逊等科技巨头正在花费巨额资金建设新的数据中心(datacenters),这对电力网和环境都造成了巨大的压力。甚至有人在讨论建设核电站,但核电站的建设需要很长时间,这导致了人们对于LLM基础设施建设是否会形成泡沫(bubbles)的担忧。这让我想起了19世纪世界各地疯狂建设铁路的情形,虽然最终留下了大量有用的基础设施,但也造成了大量的破产和环境破坏。
15. “垃圾”一词的流行(The year of slop): “垃圾”(slop)一词在2024年逐渐流行起来,它指的是未经请求且未经审查的AI生成内容。我认为“垃圾”非常贴切,它揭示了我们在使用生成式AI时最应该避免的方式。“垃圾”一词甚至入围了牛津年度词汇,这足以证明人们对AI生成内容质量的担忧和重视程度。
16. 合成训练数据(Synthetic training data works great): “模型崩溃”(model collapse)的概念并没有成为现实,反而合成训练数据展现出强大的生命力。AI实验室越来越依赖于合成数据进行训练,并采用大模型生成训练数据供小模型学习的方式。这表明,精心设计的训练数据是模型训练的关键。仅仅抓取互联网数据进行训练的时代已经成为过去。
17. LLM 使用难度的增加(LLMs somehow got even harder to use): LLM 在某种程度上变得更难用了。我们拥有了能用人类语言对话的计算机系统,但要想真正利用它们的能力,你需要深入的理解和丰富的经验。你需要理解模型的工作方式,知道它们所拥有的工具,了解它们存在的各种缺陷。此外,模型系统和工具数量的不断增加,也使得其复杂性进一步增加。同时,用户对模型的工作方式及其能力的理解也越来越不准确。我们需要更多的教育内容,而不是依靠那些夸大其词的宣传。
18. 知识分布的不均(Knowledge is incredibly unevenly distributed): 尽管很多人都已经听说过ChatGPT,但了解Claude的人却并不多。那些积极关注LLM领域发展的人与普通大众之间的知识差距依然巨大。信息传播速度之快,使得许多人都无法跟上最新的进展。在这样的背景下,我们更需要做的是弥合知识鸿沟,让更多的人了解LLM的实际应用,而不是被夸大的宣传所误导。
19. 对 LLM 的理性批判(LLMs need better criticism): 对LLM的批评是必须的,这项技术确实存在许多问题,例如环境影响、伦理问题、可靠性问题等。与此同时,我们也需要关注其积极的应用,并引导人们正确地使用它们。我们不能一味地批评LLM,也不能盲目地吹捧它们。我们需要保持理性和客观,在批判的同时,也需要挖掘LLM的价值。
笔者小结
进入2025年,AI领域将走向何方,可以确定的是AI大戏才刚刚开场,越来越多的人认识到这次AI似乎和前几次不一样。
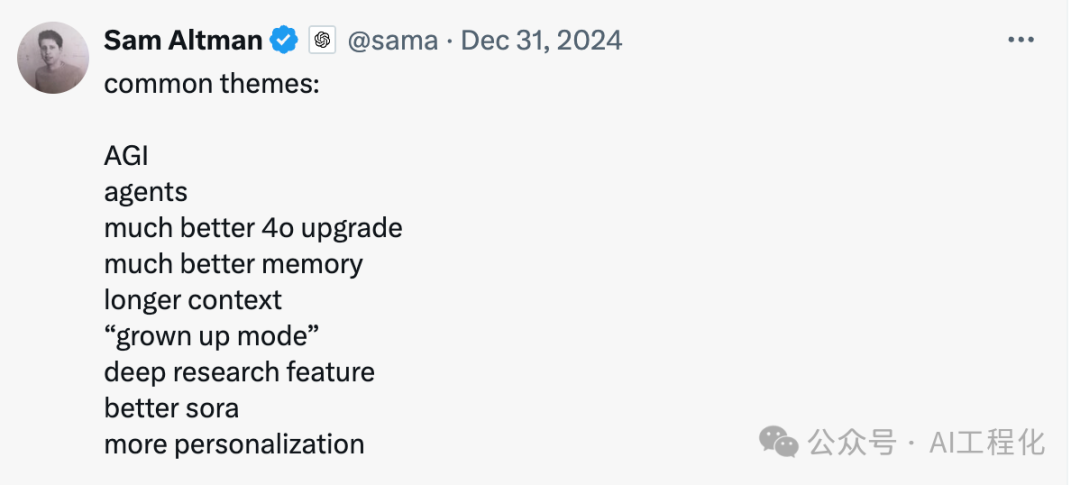
展望未来的具体变化,我们可以从Sam Altman透露的OpenAI进展中窥见一斑:基座模型的性能将持续提升,不断刷新大模型的能力边界,我们正在加速逼近通用人工智能(AGI)。与此同时,随着模型能力的跃迁,LLM应用或将迎来‘iPhone时刻’,真正的智能体有望横空出世。而多模态技术、端侧小模型的蓬勃发展,也将进一步丰富LLM应用的交互体验和应用场景,催生出具有颠覆性的‘杀手级应用’(Killer App)。
(文:AI工程化)