
超低延迟的端到端语音模型!首次生成音频仅需53ms,比同级别模型快3-5倍!

VITA-Audio是一款由VITA团队开源的端到端语音模型,首次生成音频仅需53毫秒,比同类7B参数模型快3-5倍。它具有超低延迟、首向前向传播生成等优势,并支持多种任务。
VITA-Audio是一款由VITA团队开源的端到端语音模型,首次生成音频仅需53毫秒,比同类7B参数模型快3-5倍。它具有超低延迟、首向前向传播生成等优势,并支持多种任务。
Orpheus TTS 是一款全新的开源 TTS 模型,支持接近人类的自然情感表达、超低延迟(25-50毫秒)以及强大的零样本语音克隆功能。该模型提供从 150M 到 3B 参数四种不同规模的选择。
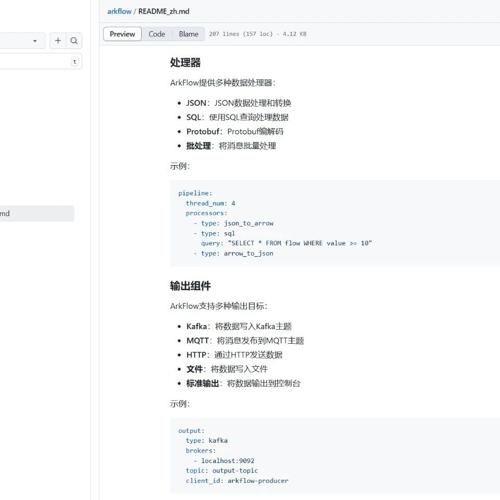
ArkFlow 是一款高性能的 Rust 流处理引擎,支持 Kafka、MQTT 和 HTTP 等多种数据源,并具备强大的 SQL 处理能力。