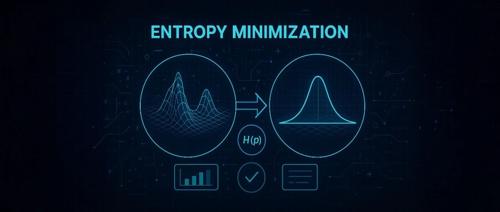
10步优化超越强化学习,仅需1条未标注数据!后训练强势破局 上午8时 2025/06/05 作者 新智元 化,就能显著提升大模型在推理任务上的表现,甚至超越依赖大量数据和复杂奖励机制的强化学习(RL)。EM