
清华团队靠强化学习让 7B 模型打败GPT-4o数学推理
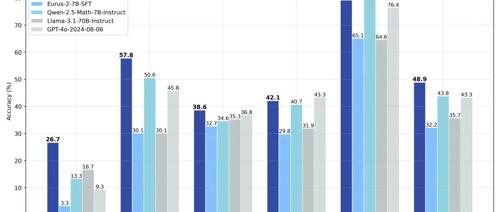
专注AIGC领域的专业社区分享了PRIME(Process Reinforcement through IMplicit REwards)算法在训练数学能力强大的7B模型方面的进展,该方法仅用8张A100、花费一万左右的成本,在不到10天内高效训练出了一个超过GPT-4和Llama-3.1-70B的7B模型Eurus-2-7B-PRIME,实现美国IMO选拔考试AIME 2024中准确率提升至26.7%。
专注AIGC领域的专业社区分享了PRIME(Process Reinforcement through IMplicit REwards)算法在训练数学能力强大的7B模型方面的进展,该方法仅用8张A100、花费一万左右的成本,在不到10天内高效训练出了一个超过GPT-4和Llama-3.1-70B的7B模型Eurus-2-7B-PRIME,实现美国IMO选拔考试AIME 2024中准确率提升至26.7%。