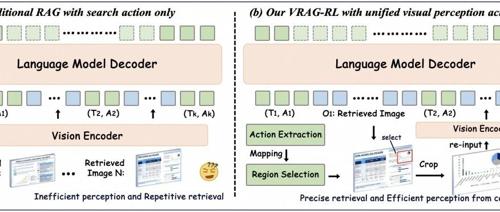
视觉感知RAG × 多模态推理 × 强化学习 = VRAG-RL 下午2时 2025/06/05 作者 PaperAgent 最新研究成果VRAG-RL通过引入强化学习和多模态智能体训练,解决视觉丰富信息检索增强生成任务中的挑战,显著提升了视觉语言模型在检索、推理和理解视觉信息方面的能力。