


本文主要作者来自上海交通大学和苏黎世大学,第一作者张宇昂,上海交通大学研究生,主要研究方向包括可微分物理机器人、多目标追踪和AIGC;共同一作胡瑜,上海交通大学博士生,主要研究方向为无人机视觉导航;共同一作宋运龙博士来自苏黎世大学,主要研究方向是强化学习、最优控制。通讯作者为上海交通大学的林巍峣教授和邹丹平教授。
想象一下:在未知森林、城市废墟甚至障碍密布的室内空间,一群无人机像飞鸟般快速穿梭,不依赖地图、不靠通信、也无需昂贵设备。这一设想,如今成为现实!
上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,该研究首次将可微分物理训练的策略成功部署到现实机器人中,实现了无人机集群自主导航,并在鲁棒性、机动性上大幅领先现有的方案。
该成果已于《Nature Machine Intelligence》在线发表。其中张宇昂硕士、胡瑜、宋运龙博士为共同第一作者,邹丹平与林巍峣教授为通信作者。

-
论文地址:https://www.nature.com/articles/s42256-025-01048-0
-
视频地址:https://www.bilibili.com/video/BV1sgMqzSExJ
-
项目地址:https://henryhuyu.github.io/DiffPhysDrone_Web/
核心理念:大道至简
过去的无人机自主导航往往依赖:
-
高复杂度定位与建图、轨迹规划与生成、轨迹跟踪等串联模块算法设计
-
昂贵笨重传感器 + 高性能 CPU/GPU 计算平台
-
多机间通信或集中规划
经过不懈努力,研究团队设法探索出一条崭新的途径:
-
使用 12×16 超低分辨率深度图作为输入。
-
使用仅 3 层 CNN 的超小神经网络实现端到端自主飞行,可部署于 150 元廉价嵌入式计算平台。
-
抛弃复杂无人机动力学,用极简质点动力学模型,通过可微物理引擎训练端到端网络。
最终实现训练一次,多机共享权重,零通信协同飞行!
惊艳表现:现实世界中疾驰穿越

在单机场景中,将网络模型部署在无人机上后在不同的真实环境中进行测试,包括树林、城市公园,以及含有静态和动态障碍的室内场景。该网络模型在未知复杂环境中的导航成功率高达 90%,相比现有最优方法展现出更强的鲁棒性。
在真实树林环境中,无人机飞行速度高达 20 米 / 秒,是基于模仿学习的现有方案速度的两倍。所有测试环境均实现 zero-shot 零样本迁移。该系统无需 GPS 或者 VIO 提供定位信息即可运行,并能适应动态障碍物。


图 1 多机飞行
多机协同场景中,将网络模型部署到 6 架无人机上执行同向穿越复杂障碍和互换位置任务。该策略在同向穿越门洞、动态障碍物和复杂静态障碍物的场景中展示了极高的鲁棒性。在多机穿越门洞互换位置的实验中,展现出了无需通信或集中规划的自组织行为。


图 2 多机自组织协作

图 3 动态避障
思路关键:将物理原理嵌入网络训练
让无人机 「自己学会飞」
-
端到端可微仿真训练:策略网络直接控制无人机运动,通过物理模拟器实现反向传播。
-
轻量设计:整套端到端网络参数仅 2MB,可部署在 150 元的计算平台(不到 GPU 方案的 5% 成本)。
-
高效训练:在 RTX 4090 显卡上仅需 2 小时即可收敛。

图 4 低成本算力平台
训练总体框架如下图所示,通过与环境交互来训练策略网络,在每一个时间步,策略网络接收深度图像作为输入,并通过策略网络输出控制指令(推力加速度和偏航角)。可微物理模拟器根据控制指令模拟无人机的质点运动,进行状态更新:
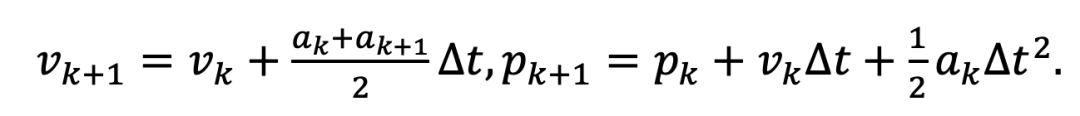
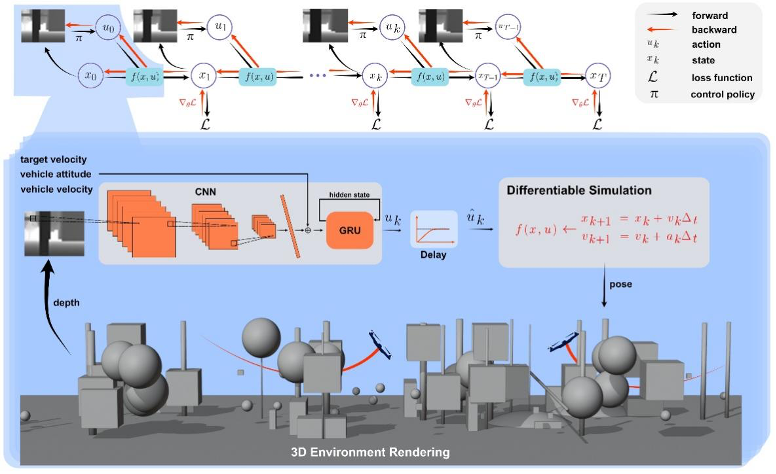
在新的状态下可以渲染新的深度图像并计算代价函数。代价函数由多个子项组成,包括速度跟踪项、避障项、平滑项等。在轨迹采集完毕后,代价函数可通过链式法则(图 1 中红色箭头)计算梯度实现反向传播,从而直接优化策略参数。
「简约即美」 的训练诀窍
简单模型:使用质点动力学替代复杂飞行器建模。
简单图像:低分辨率渲染 + 显式几何建模,提升仿真效率。
简单网络:三层卷积 + GRU 时序模块,小巧高效。
此外,训练过程中通过引入局部梯度衰减机制,有效解决训练中梯度爆炸问题,让无人机 「专注于眼前」 的机动策略自然涌现。
方法对比:强化学习、模仿学习
还是物理驱动?
当前具身智能的主流训练范式主要分为两类:强化学习(Reinforcement Learning, RL)与模仿学习(Imitation Learning, IL)。然而,这两类方法在效率与可扩展性方面均存在明显瓶颈:
-
强化学习(如 PPO) 多采用 model-free 策略,完全不考虑环境或控制对象的物理结构,其策略优化主要依赖基于采样的策略梯度估计,这不仅导致数据利用率极低,还严重影响训练的收敛速度与稳定性。
-
模仿学习 (如 Agile [Antonio et al.(2021)]) 则依赖大量高质量的专家演示作为监督信号。获取这类数据通常代价昂贵,且难以覆盖所有可能场景,从而影响模型的泛化能力及扩展性。
相比之下,本研究提出的基于可微分物理模型的训练框架,有效融合了物理先验与端到端学习的优势。通过将飞行器建模为简单的质点系统,并嵌入可微分仿真过程,能够直接对策略网络的参数进行梯度反向传播,从而实现高效、稳定且物理一致的训练过程。
研究在实验中系统对比了三种方法(PPO、Agile、本研究方法),主要结论如下:
-
训练效率:在相同硬件平台上,本方法在约 2 小时内即可实现收敛,训练时间远低于 PPO 与 Agile 所需的训练周期。
-
数据利用率:仅使用约 10% 的训练数据量,本方法在策略性能上就超越了使用全量数据的 PPO + GRU 方案。
-
收敛性能:在训练过程中,本方法展现出更低的方差与更快的性能提升,收敛曲线显著优于两类主流方法。
-
部署效果:在真实或近似真实的避障任务中,本方法的最终避障成功率显著高于 PPO 与 Agile,表现出更强的鲁棒性与泛化能力。
这一对比结果不仅验证了 「物理驱动」的有效性,也表明:当我们为智能体提供正确训练方法时,强智能不一定需要海量数据与昂贵试错。

图 5 本研究方法以 10% 的训练数据量即超过现有方法 (PPO+GRU),收敛性能远高于现有方法。
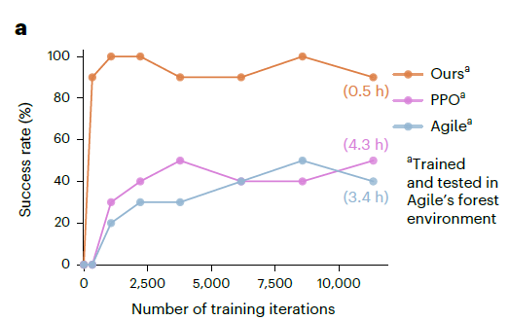
图 6 模型部署避障成功率对比
雾里看花:可解释性探究
尽管端到端神经网络在自主飞行避障任务中表现出强大性能,其决策过程的不透明性仍是实际部署中的一大障碍。为此,我们引入 Grad-CAM 激活图工具,对策略网络在飞行过程中的感知注意力进行了可视化分析。
图 7 展示了不同飞行状态下输入的深度图(上排)及其对应的激活图(下排)。可以观察到,网络的高响应区域高度集中在飞行路径中最可能发生碰撞的障碍物附近,例如树干、柱体边缘。这表明,尽管训练过程中没有显式监督这些 「危险区域」,网络已自发学会将注意力集中在潜在风险最大的区域上。这一结果传递出两个重要信息:网络不仅在行为层面实现了成功避障,其感知策略本身也具有一定的结构合理性与物理解释性;而可解释性工具也有助于我们进一步理解端到端策略背后的 「隐性规则」。

图 7 通过观察激活图,激活区域与最危险障碍强相关
思考与启发:大模型时代中的 「小模型」
在这个几乎一切技术路径都奔向 「大」的时代,基础模型、通用智能、Scaling Law 正逐渐成为信仰。人们谈论的是参数规模、数据体量、计算资源 —— 仿佛智能的本质就在于 「越大越好」,而 「小」则成了被遗忘的方向,甚至被误解为 「不足为道」。
然而,自然界从不遵循单一尺度的美学。
它既孕育了人类这样拥有亿级神经元的智慧生物,也赋予了果蝇、蚂蚁、蜜蜂等微小生灵以惊人的生存智慧。它们不靠算力、不依赖高精度传感器,却能在复杂世界中做出迅速而精妙的反应。这种 「生存意义上的智能」,或许恰是我们今日在追求 「强智能」 时最容易忽略的维度。
从本项研究中我们得到了三个深刻的启发:
1. 小模型有其存在的合理性,甚至是理解 「大模型」的入口
人类认知系统复杂而庞大,但理解人类大脑的第一步,并不是直接对人脑建模,而是回到果蝇这样神经回路清晰、结构机制简单的生物个体。从某种意义上说,果蝇不仅不是神经科学的例外,它是神经科学的起点。
同样道理,小模型不是大模型的对立面,而是其结构理解与机制抽象的镜像反射。它们提供了一个更透明的窗口,让我们看清决策、感知与控制之间最本质的耦合关系。在这项工作中,我们用一个参数量不到 2MB 的小网络,实现了多机间无需通信的自组织协同。这不仅是工程简约的胜利,更是系统智慧本源的回归。
2. 不是所有智能都必须建立在大规模数据之上
我们在一个完全仿真的世界中采集数据 —— 没有庞大的数据集,没有互联网语料,也没有数百万小时的飞行日志。相反,我们只依靠可控、可微的物理引擎,用少量任务场景与目标函数,在一个仅由简单几何体构成的仿真环境中就训练出了能在现实世界中零样本迁移、应对复杂障碍的小型基于视觉的飞行控制策略。
这是一种反常识的成果。它提醒我们,智能的来源不必拘泥于数据体量的绝对值,而更应关注 「结构匹配」 与 「机制嵌入」:
「一个真正懂物理的网络,也许比一个背诵万卷飞行日志的网络更可靠。」
3. 粗糙的感知,也能支撑精准的智能行为
果蝇的视觉系统由约 800 个简单的复眼构成,其成像能力甚至不及低配监控摄像头。然而就是这样一个 「低分辨率生物」,可以在高速飞行中完成复杂的空间规避、空中悬停与捕食等任务。精度低,并不等于智能低。
我们也使用了类似 「果蝇之眼」的设置:12×16 分辨率的深度图像输入,结合简单的物理模型和策略网络,就能驱动无人机以高达 20 米 / 秒的速度自主飞行。这一实验结果无声地提出了一个颠覆性假设:
「真正决定导航能力的,并非传感器的精度,而是智能体对物理世界的内在理解程度。」
或许未来的智能,不再是一味 「堆大」,而是对 「小」 的重新理解与深度挖掘。
后续研究:端到端单目自主 FPV 无人机
研究团队后续改进与拓展了可微物理引擎框架与训练方法,进一步实现了国际首个基于单目 FPV 摄像头的端到端视觉避障系统,在真实室外环境中实现最高 6m/s 飞行速度,无需建图即可自主导航,该研究已在《IEEE Robotics and Automation Letters》发表。

图 8 端到端 FPV(第一人称视角摄像头)自主飞行
相关论文与视频
Hu, Yu, Yuang Zhang, Yunlong Song, Yang Deng, Feng Yu, Linzuo Zhang, Weiyao Lin, Danping Zou, and Wenxian Yu. “Seeing Through Pixel Motion: Learning Obstacle Avoidance From Optical Flow With One Camera,” in IEEE Robotics and Automation Letters, vol. 10, no. 6, pp. 5871-5878, June 2025, doi: 10.1109/LRA.2025.3560842.
单目避障视频地址:https://www.bilibili.com/video/BV1o7fMYzEA7/

©
(文:机器之心)