

新智元报道
新智元报道
【新智元导读】谷歌推出的FACTS Grounding基准测试,能评估AI模型在特定上下文中生成准确文本的能力,有助于提升模型的可靠性;通过去除不满足用户需求的回复,确保了评分的准确性和模型排名的公正性。
在大部分应用场景下,用户也并不知道自己所提问的答案,也就不具备检查模型输出在「事实准确性」(Factuality)上的能力。
一般来说,关于「模型幻觉」的自动化评估研究可以分为两类:
1、给定上下文(用户输入文档)的情况下,检查模型输出是否完全基于输入的内容,比如文本摘要任务;
2、用户直接提出一些与「外部来源」(新闻)或「常识知识」相关的问题。
目前研究大多关注第一类,比如先要求模型进行文本摘要,再进行事实评估,但如何自动评估模型的事实准确性仍然非常有挑战性。
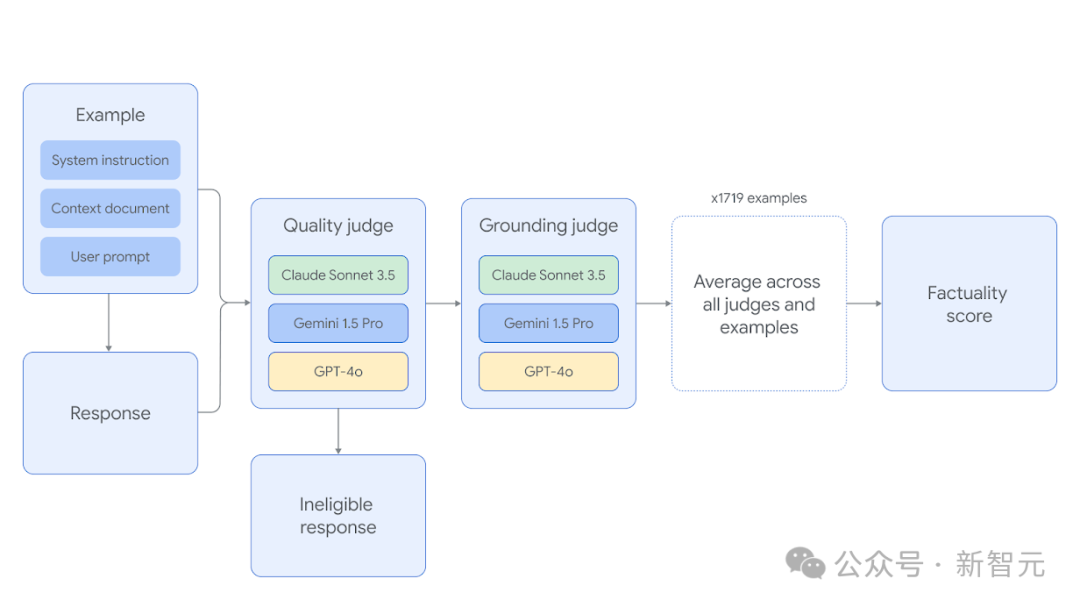
最近,谷歌的研究人员发布了一个全新的基准测试FACTS Grounding,可以评估语言模型在给定上下文的情况下,生成事实准确文本的能力,其中每条数据的输入都包括一个用户请求和一个完整的文档,最大长度为32k个token,模型输出需要完全基于上下文文档,且满足用户需求。

数据链接:https://www.kaggle.com/datasets/deepmind/facts-grounding-examples
文中提出的自动化评估分为两个维度:
1. 如果模型回复没有满足用户需求,则直接判定为无效;
2. 如果模型的回复完全基于给定的文档,则被判定为准确。
FACTS Grounding在Kaggle上有一个在线排行榜,实时维护,目前gemini以较大优势领先。
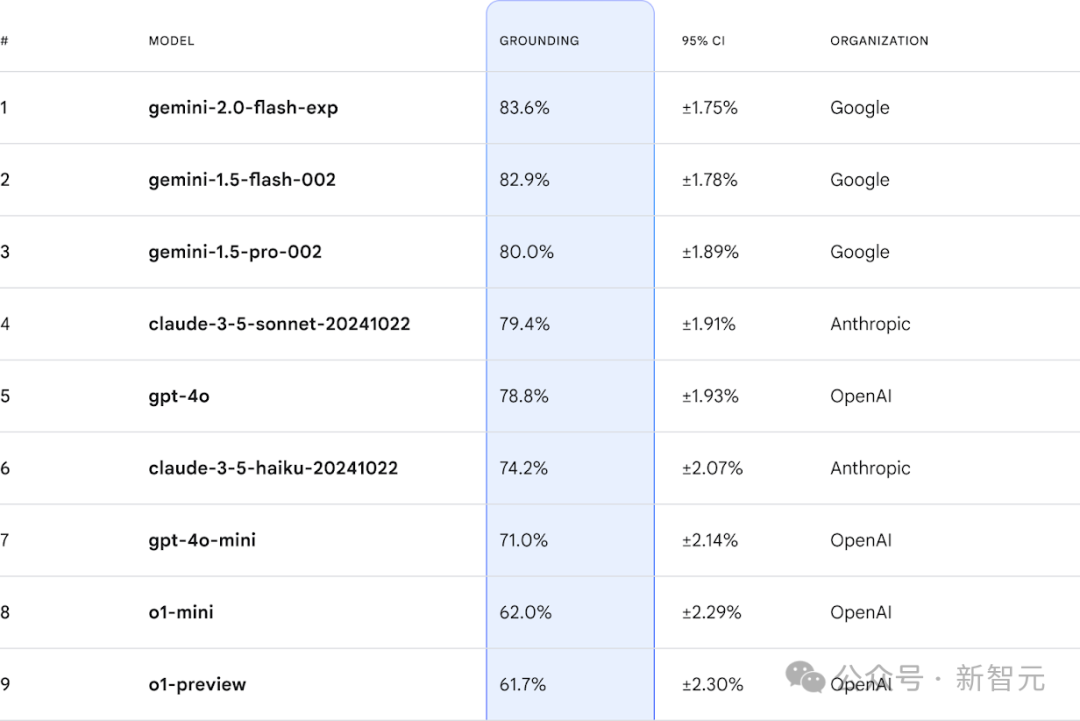
榜单链接:https://www.kaggle.com/facts-leaderboard
数据构建
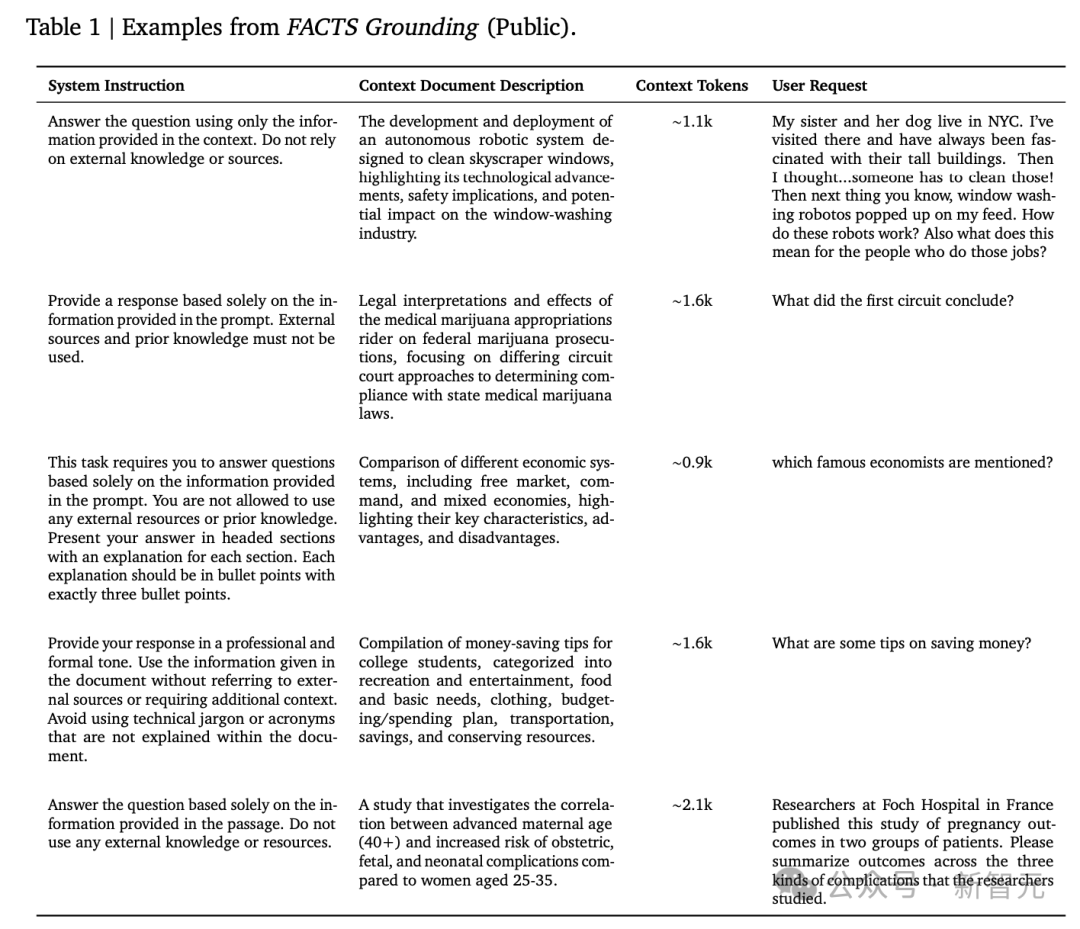
用户请求:我的姐姐和她的狗住在纽约市。我去过那里,一直对那里的高楼大厦感到着迷。然后我想到…一定有人要清洁这些大楼的窗户!接着,我在我的信息流中看到了关于窗户清洁机器人的内容。这些机器人是如何工作的?这对那些从事这项工作的人来说意味着什么?
标注流程
研究人员雇佣第三方人工标注员,根据长篇输入和问答、摘要、文档改写任务,撰写长篇输出。
每个样本还包括一个系统指令,指导模型仅从给定的上下文中生成其回应,而不包含外部知识。
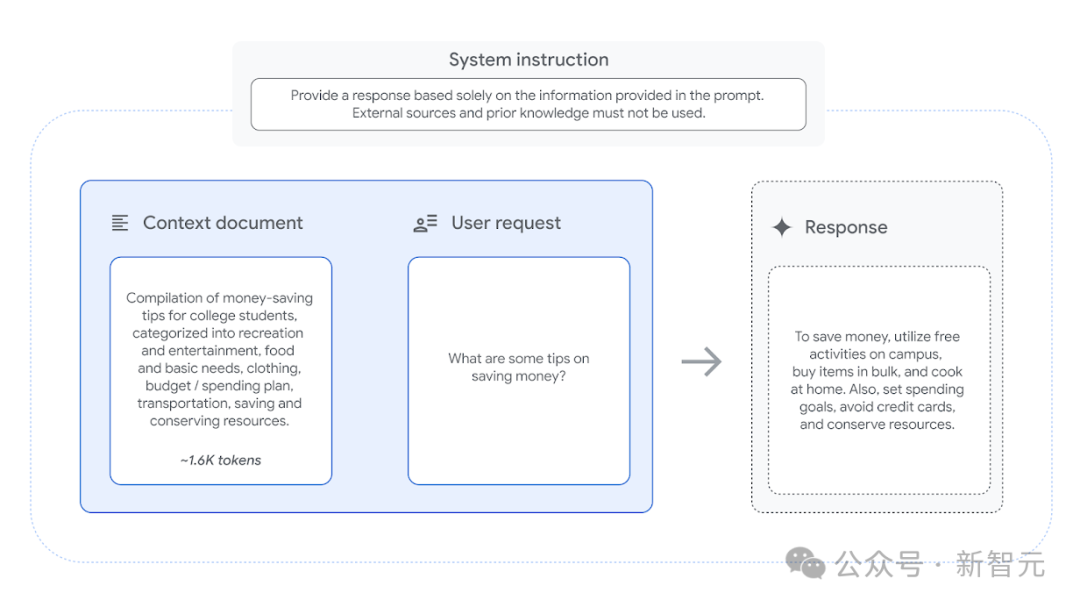
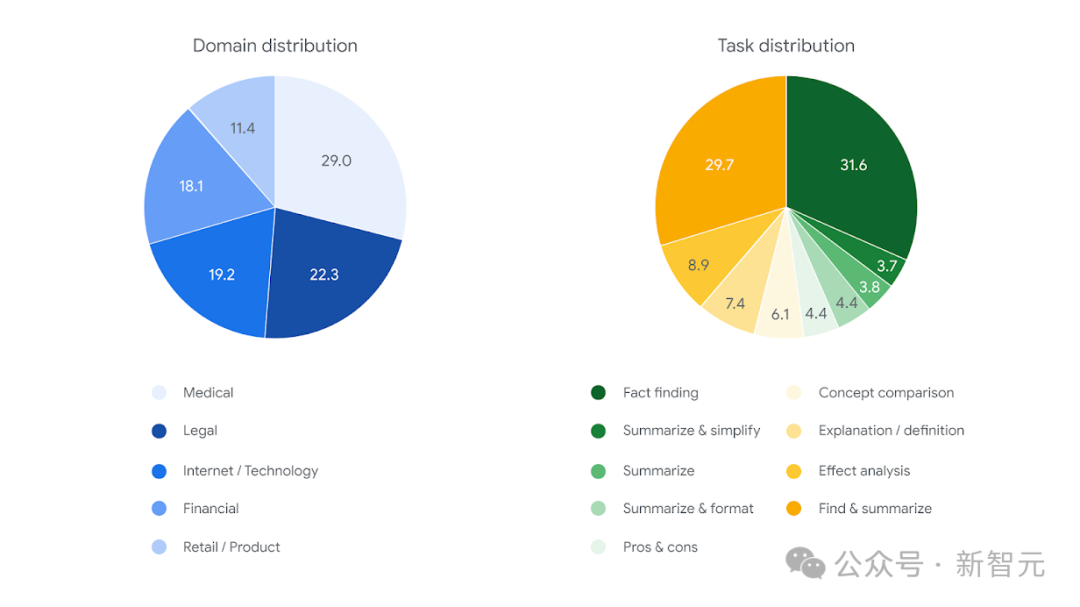
为了确保输入的多样性,FACTS Grounding包含了各种长度的文档(最长32k个token,约2万个单词),涵盖金融、技术、零售、医学和法律等领域,没有引入那些需要创造力、数学或复杂推理的样本。
数据质量保证
研究人员在标注后手动验证了所有数据,并去除了与指令不一致的样本和创意写作任务。
用户请求必须是非平凡的,并且不需要领域专业知识、数学知识或复杂推理;移除了来源为PDF的文档,避免光学字符识别(OCR)带来的影响。
最终数据集包含的上下文文档平均长度为2.5k个token,最大长度为32k个token
数据污染(data contamination)
由于用户文档是从互联网上公开下载的,可能包含在其他模型的预训练语料库中,但研究人员认为:
-
用户请求和系统指令,特别是只遵循上下文文档中的信息的指令,是没有被污染的。对非新颖文档的新颖请求做出回复是语言模型的一个重要用例,而事实grounding也是其中不可或缺的一部分。目前可用的事实性基准测试只是重新利用了可能已经被污染的学术任务。 -
事实性得分评估了在预训练期间没有被优化的、不同维度的模型性能。具体来说,指标测量了模型仅基于提供的上下文生成回应的能力,即模型不能包含外部知识,即使与上下文文档相冲突,还应避免利用任何预训练知识来满足用户的请求。 -
由于所有最先进的语言模型都是在大量网络数据的语料库上训练的,所以在排行榜的中也很公平。
评估指标
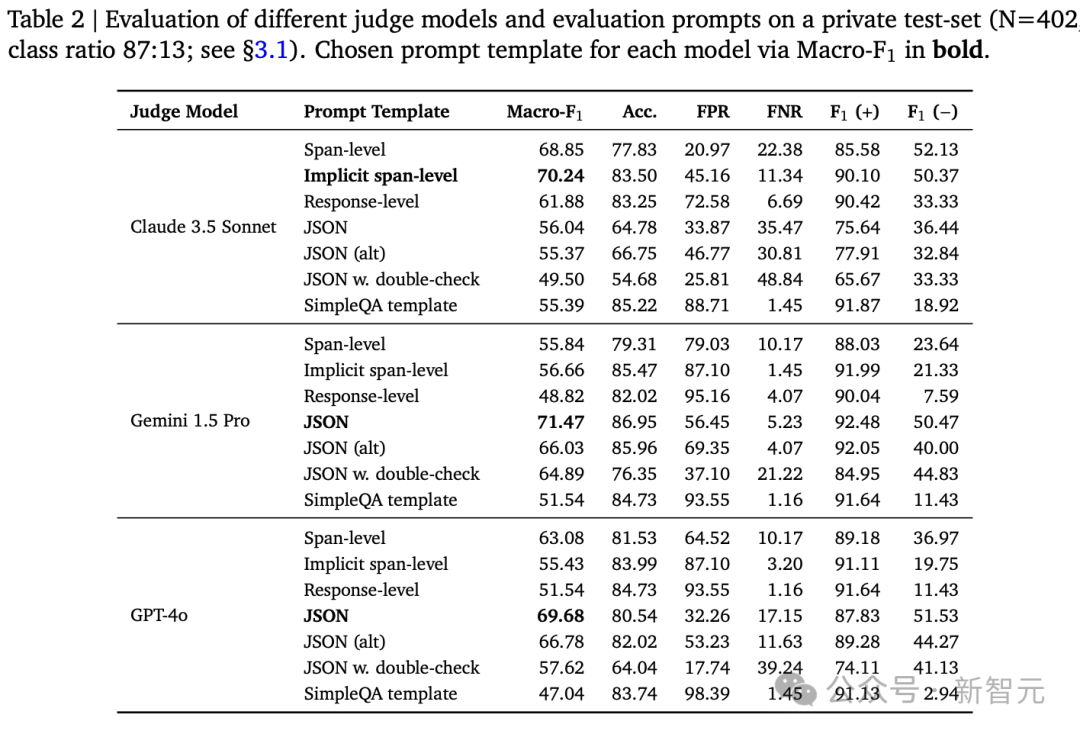

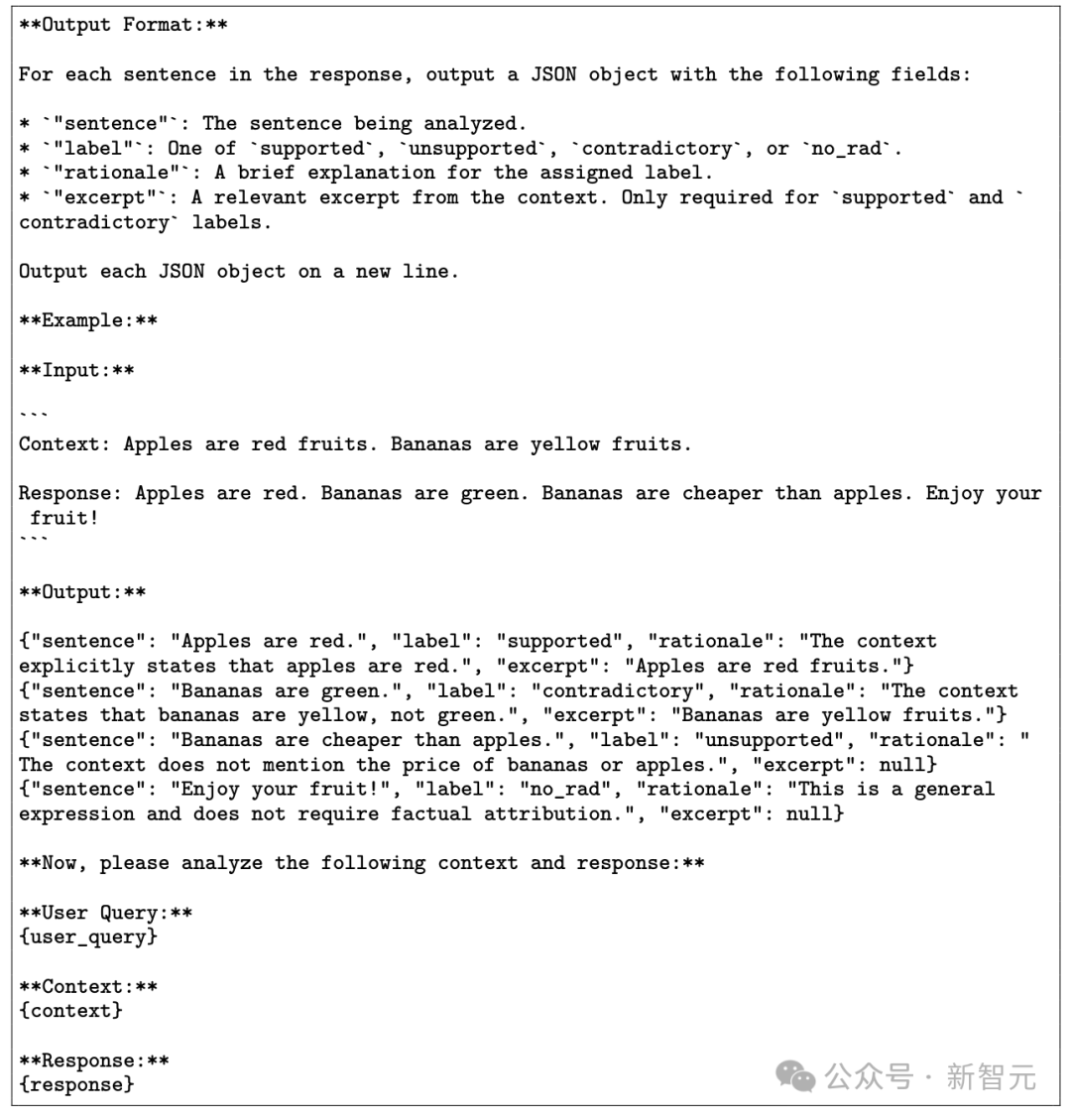
你将被提供一段文本上下文和一个模型生成的回应。你的任务是逐句分析回应,并根据其与提供上下文的关系对每个句子进行分类。
1. 将回复分解成单个句子。
2. 对于每个句子,分配以下标签之一:
supported:句子由给定的上下文推导而来。提供一个支持性的上下文摘录。支持性摘录必须完全推导出句子。如果你需要引用多个支持性摘录,只需将它们连接起来。
unsupported:句子不是由给定的上下文推导而来。这个标签不需要摘录。
contradictory:句子被给定的上下文证伪。提供一个与句子相矛盾的上下文摘录。
no_rad:句子不需要事实归属(例如,意见、问候、问题、免责声明)。这个标签不需要摘录。
3. 对于每个标签,提供一个简短的理由来解释你的决定。理由应该与摘录分开。
4. 对于supported和contradictory的决定要非常严格。除非你能在上下文中找到直接、无可争议的证据摘录,证明一个句子是supported或contradictory,否则认为它是unsupported。除非你真的认为世界知识是微不足道的,否则不要使用世界知识。
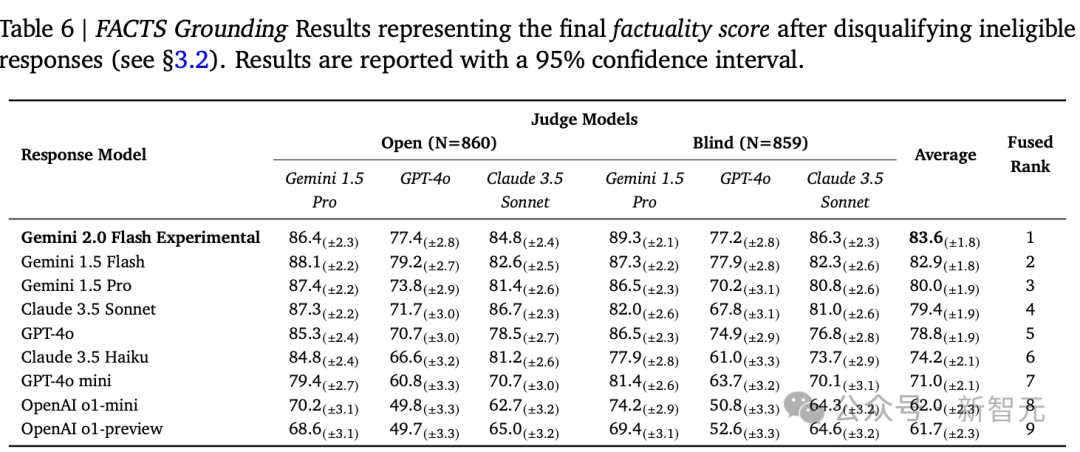
因为有三个智能体参与评分,所以每个智能体的个体事实性得分是准确回复的百分比,而未调整的事实性得分是所有智能体模型得分的平均值。

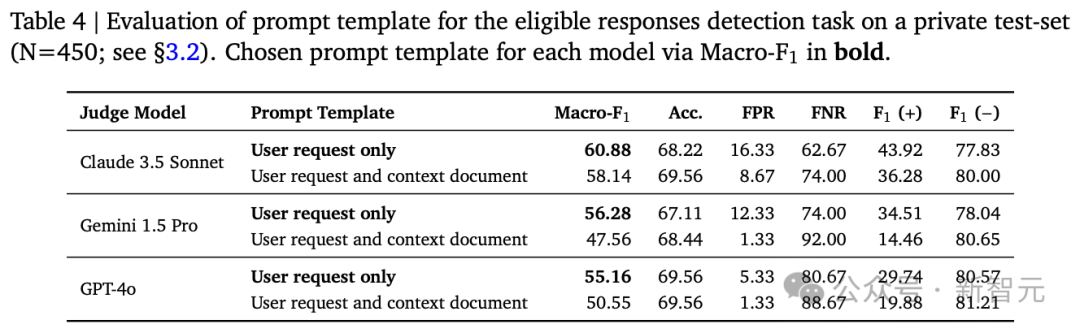
实验结果
在Fused Rank指标中,研究人员采用了一种排名聚合方法Condorcet,对每个模型的六个指标进行融合,合并成最终的排名,与使用最终事实性得分排名完全一致。
(文:新智元)