

点击上方“蓝色字体”关注我,每天推送“实用有趣的项目”!
随着人工智能的不断进步,文本转语音(TTS)技术已经成为我们日常生活中不可或缺的一部分。
从语音助手到有声读物,再到角色配音,TTS 的应用场景日益广泛。
然而,尽管市面上已有众多 TTS 模型,但它们往往需要庞大的计算资源,这对许多开发者和中小型企业来说是一个不小的挑战。
最近,一款名为 Kokoro TTS 的开源 TTS 模型凭借其高效能和轻量化设计迅速窜红。它不仅在TTS排行榜上名列前茅,还以其独特的性能吸引了众多开发者和用户的关注。
这个仅拥有 82M 参数的高效 TTS 模型,只需轻轻一点,就能在几秒钟内生成几分钟的高质量语音。不需要昂贵的设备,也不需要复杂的配置。

项目简介
Kokoro TTS,又名 Kokoro-82M,是一个新晋的开源文本转语音模型。
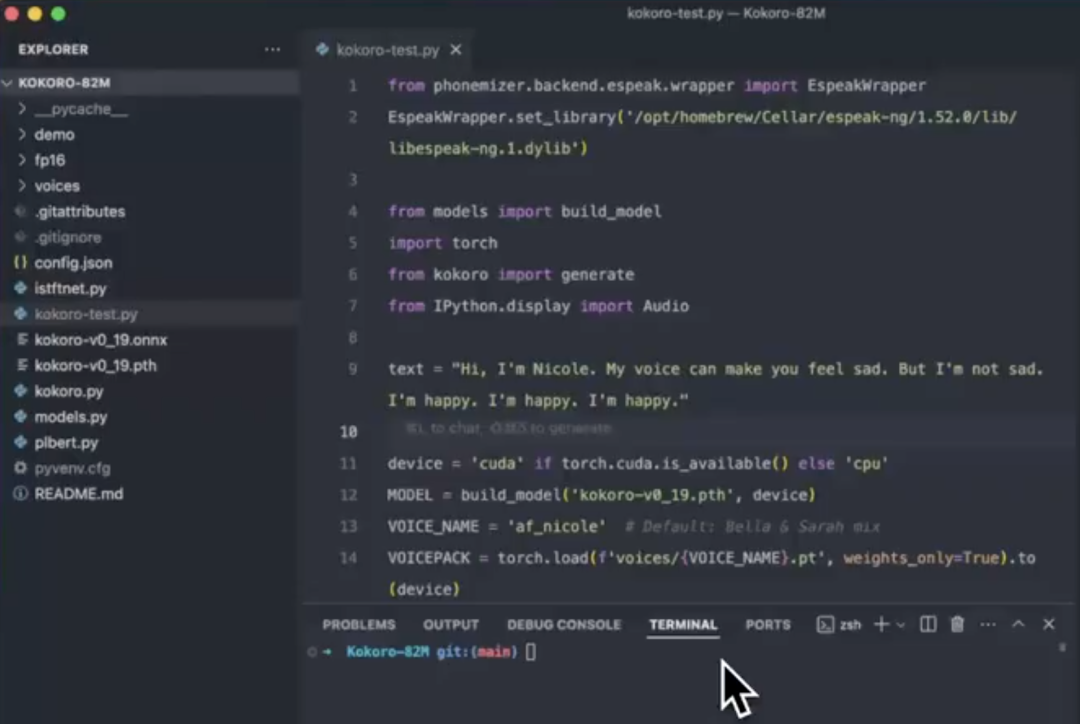
与那些动辄数亿参数的大型模型相比,它显得异常轻量。然而,轻量化并未牺牲性能,Kokoro TTS在CPU上即可实现近乎实时的语音生成,而在GPU端则能达到惊人的50倍实时速度。
这意味着,你可以在几秒钟内生成几分钟的高质量语音,而无需高端硬件的支持。
这一性能表现,使得 Kokoro TTS 在 TTS 排行榜中冲至第一,成为业界的新宠。
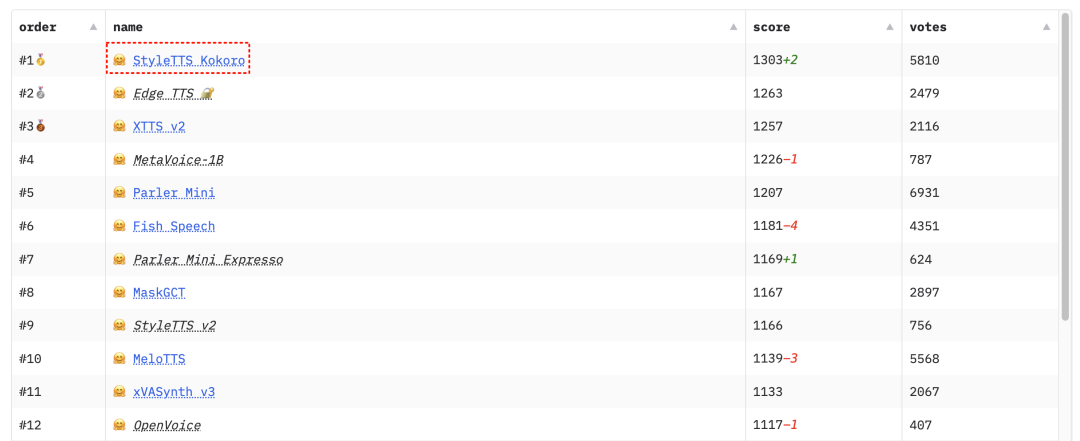
该模型不仅支持中文,还兼容多达五种语言,充分展示了其语言处理的多样性和灵活性。
核心亮点
-
• 参数小,性能强:Kokoro TTS 拥有仅 82M 参数,与其他需要庞大资源的模型相比,它显得格外高效。
-
• 多语言支持:支持中文、韩语、日语、法语、英语等五种语言。
-
• 多人物音色支持:提供了多达18种男女人物音色。
-
• 实时语音生成:在普通CPU上,Kokoro TTS可以近乎实时生成语音,而在GPU上,生成速度更是快到了令人难以置信的50倍实时速度。
-
• 自然的语音合成:Kokoro TTS 生成的语音自然流畅,接近人类语音。无论是用于语音助手、有声读物,还是角色配音,均能提供高质量的语音体验。
快速使用
你可以通过 HuggingFace 在线体验,直接试用 Kokoro TTS,感受其快速的语音生成能力和高质量的输出。
只需选择好语言、输入文本、选择音色,即可生成语音了。
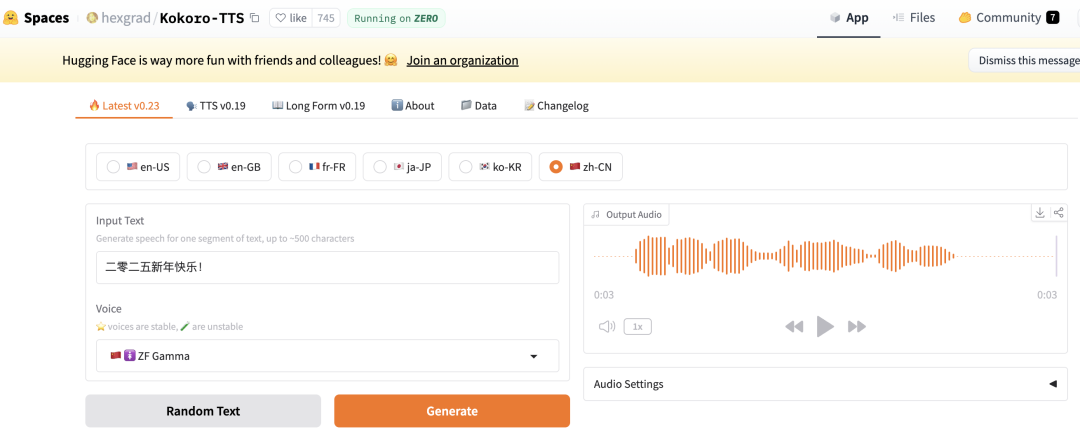
语音结果:
如果你是开发者,想将其集成到你的项目程序中,也可下载模型进行调用。
具体代码如下:
# 1️⃣ Install dependencies silently
!git lfs install
!git clone https://huggingface.co/hexgrad/Kokoro-82M
%cd Kokoro-82M
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
!pip install -q phonemizer torch transformers scipy munch
# 2️⃣ Build the model and load the default voicepack
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('kokoro-v0_19.pth', device)
VOICE_NAME = [
'af', # Default voice is a 50-50 mix of Bella & Sarah
'af_bella', 'af_sarah', 'am_adam', 'am_michael',
'bf_emma', 'bf_isabella', 'bm_george', 'bm_lewis',
'af_nicole', 'af_sky',
][0]
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
# 3️⃣ Call generate, which returns 24khz audio and the phonemes used
from kokoro import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
# Language is determined by the first letter of the VOICE_NAME:
# 🇺🇸 'a' => American English => en-us
# 🇬🇧 'b' => British English => en-gb
# 4️⃣ Display the 24khz audio and print the output phonemes
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
print(out_ps)写在最后
Kokoro TTS 的出现,打破了人们对 TTS 技术的固有印象。它以小巧的身材和强大的功能,重新定义了 TTS 模型的可能性。
在这个技术快速更迭的时代,Kokoro TTS为我们展示了轻量级模型也能拥有强大性能的无限潜力。对于语音克隆爱好者及配音人员,也提供了一个新的创作渠道。
或许下一个语音革命的主角,正是它。
在线体验地址:https://huggingface.co/spaces/hexgrad/Kokoro-TTS
模型地址:https://huggingface.co/hexgrad/Kokoro-82M

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)