

语音生成迎来大突破!

一个叫SpeechSSM的新模型横空出世,它能一口气说上16分钟的故事,而且不需要任何文字辅助。这听起来可能不算什么,但在AI世界里,这简直就是个奇迹!
你可能会问:这有什么了不起的?
想象一下,之前的AI语音模型就像是个「业余选手」,说个几十秒就开始结巴、跑题,甚至直接「断片」。原因说来也简单:它们的「脑容量」不够用了。
就像你看视频的时候开太多浏览器标签页,电脑就会开始卡顿一样。AI生成语音的时候也面临同样的问题:内容越长,需要记住的东西就越多,最后就「转不动」了。
那SpeechSSM是怎么做到的呢?
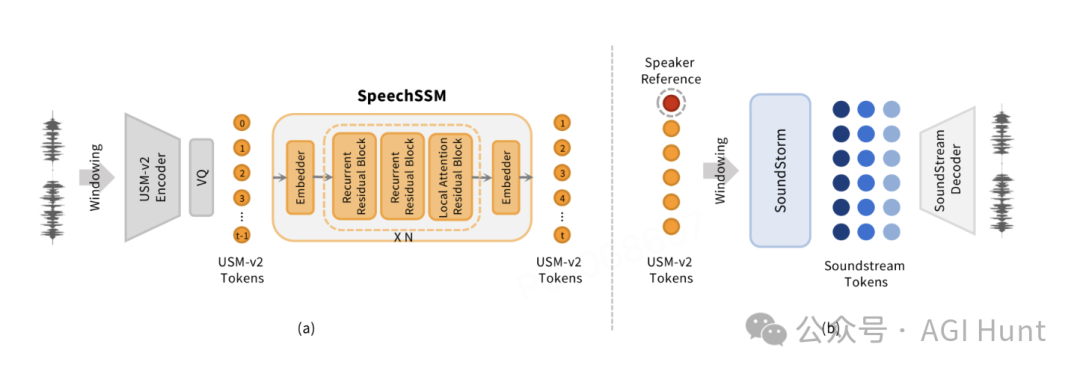
它采用了一个特别聪明的方法:用「记笔记」代替「背全文」。

具体来说,它会把长内容分成一个个小片段,每个片段30秒,但相邻片段之间会有4秒的重叠。
这就像接力跑一样,「交接棒」的时候两个人要同时抓住接力棒一样。
这样做有个绝妙的好处:模型在任何时候都只需要处理固定长度的内容,不会因为说太久就「累趴下」。
更厉害的是,它还能完美保持说话者的声音特征。这就像是一个优秀的配音演员,不管剧情多长,声音特点都不会变。
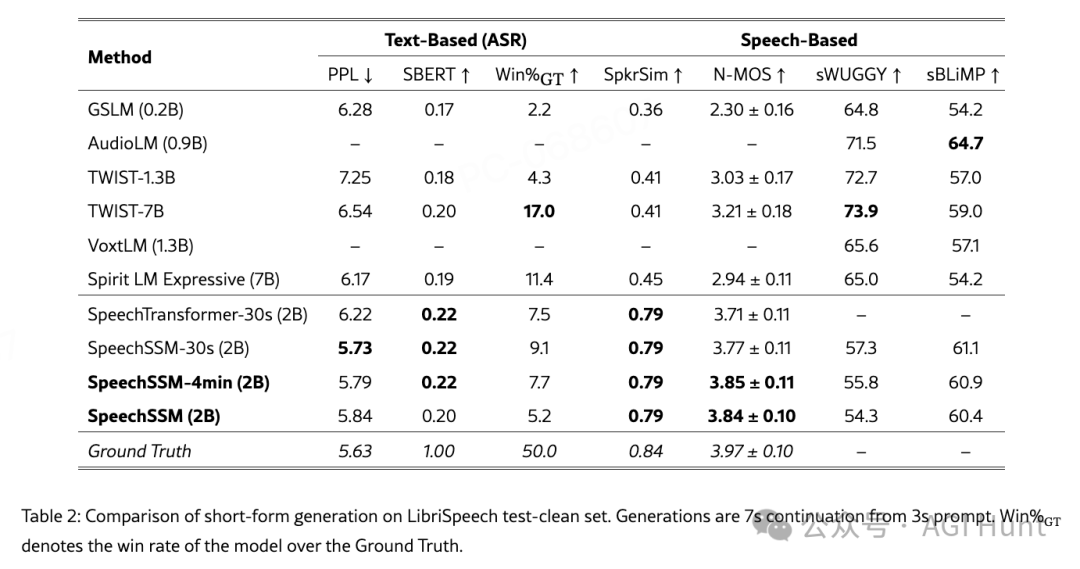
实际效果如何?
简直惊艳!
-
处理速度比传统模型快120倍
-
100秒就能生成11分钟的语音
-
前后文完全连贯,就像真人在说话
-
能保持稳定的输出质量

研究团队还专门开发了一个 「即兴演讲」版本,叫SpeechSSM-X。它不仅能说,还能像真人一样即兴发挥,语气自然,想到哪说到哪。

这让人不禁感叹:AI也太会说话了吧!
有趣的是,这个模型连「断句」都很有讲究。它会在说话的时候自然停顿,就像人类演讲一样,让听众能更好地理解内容。这种细节的处理,让它生成的语音听起来特别自然。
这项突破性的研究不仅让语音助手能说长篇大论,更为有声书、播客等领域带来了无限可能。想象一下,以后你最喜欢的小说,可能就是由AI来给你朗读了!
终于,AI不再是个「短跑健将」,而是变成了一个能说会道的「马拉松选手」。
未来的AI,还会给我们带来什么惊喜呢?
百闻不如一听,快去试试这个能说会道的AI吧!
论文地址:https://arxiv.org/abs/2412.18603v1
(文:AGI Hunt)
神还原!比真人大etruer!16分钟都不怕,分段处理还带交接棒,重叠4秒保持声音连贯。这技术圈内顶流了!✨