

我们已经看到,大模型应用已经从简单的问答向复杂的智能体系统转变。与之匹配的,技术焦点也正从早期的提示工程(Prompt Engineering),即如何巧妙地向模型提问,迅速转向一个更进阶的领域——上下文工程(Context Engineering)。
在模型能力日益强大的今天,决定应用成败的关键,已不再是“如何问”,而是“为模型提供什么样的信息”。这正是上下文工程的核心。

大多数情况下,当一个智能体表现不可靠时,其根本原因并非模型本身的能力不足,而在于我们未能向其传递完成任务所需的上下文、指令和工具。因此,上下文工程正迅速成为 AI 工程师所能掌握的最关键技能。
在前面文章里也多次提过上下文工程的内容,但缺少系统化理论化的定义。
Karpathy最新提出的“系统提示学习”是什么? 未来context为王?
Google新研究:降低大模型幻觉的全新视角——充分上下文!
近日,Langchain创始人也撰文《The rise of “context engineering”》探讨了这一问题,借此机会让我们更深入了解“上下文工程”。
什么是上下文工程?
上下文工程,其核心是构建一个动态系统,旨在以正确的格式,为大模型提供恰当的信息与工具,从而使其能够可靠地完成指定任务。
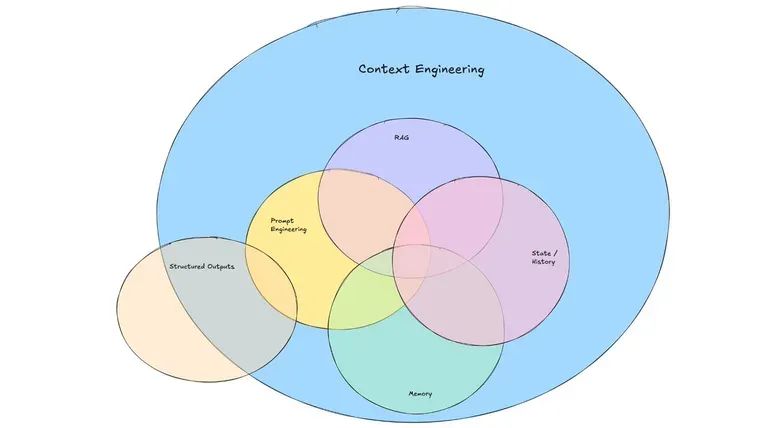
这一定义综合了 Tobi Lutke、Ankur Goyal 及 Walden Yan 等行业先行者的洞见。我们可以从以下几个维度来深入理解:
-
它是一个系统工程:复杂的智能体需要从多个来源获取上下文,包括开发者预设、用户输入、历史交互、工具调用结果以及外部数据。将这些信息源有机地整合起来,本身就是一个复杂的系统工程。 -
它是动态变化的:上下文的许多组成部分是实时生成的。因此,最终输入给模型的提示(Prompt)也必须是动态构建的,而非静态的模板。 -
它要求信息精准:智能体系统失败的常见原因之一是上下文信息的缺失。LLM 无法“读心”,我们必须为其提供完成任务所需的全部信息。所谓“垃圾进,垃圾出”,信息质量直接决定输出质量。 -
它要求工具适用:很多任务无法仅靠初始信息完成。此时,为 LLM 配备合适的工具就变得至关重要。这些工具可以用于信息检索、执行动作或与其他系统交互。提供正确的工具与提供正确的信息同等重要。 -
它强调格式规范:正如人际沟通,我们与 LLM 的“沟通方式”同样关键。一个简洁明了的错误信息远胜于一个庞杂的 JSON 数据块。工具的参数设计、数据的呈现格式,都会显著影响 LLM 的理解和使用效率。 -
它关注任务的可行性:在设计系统时,我们应反复自问:“在当前提供的上下文和工具下,LLM 是否真的有可能完成任务?” 这个问题帮助我们将失败归因于上下文不足,还是模型本身的执行失误,从而采取不同的优化策略。
为何上下文工程如此重要?
智能体系统的失误,本质上是 LLM 的失误。从第一性原理分析,LLM 的失败主要源于两个方面:
-
底层模型能力不足,无法正确推理或执行。 -
模型未能获得做出正确判断所需的上下文。
随着模型能力的飞速发展,第二点正成为更普遍的瓶颈。上下文供给不足主要体现在:
-
信息缺失:模型完成任务所依赖的关键信息未被提供。 -
格式混乱:信息虽然存在,但其组织和呈现方式不佳,阻碍了模型的有效理解。
上下文工程与提示词工程的区别
为何行业焦点正从“提示词工程”转向“上下文工程”?早期,开发者更专注于通过巧妙的措辞来“诱导”模型给出更好的答案。但随着应用复杂度的提升,一个共识逐渐形成:向 AI 提供完整、结构化的上下文,其重要性远超任何“魔法般”的措辞。
我们可以认为,提示词工程是上下文工程的一个子集。即便拥有了全部所需信息,如何将这些动态数据高效地组织、格式化并呈现在最终的提示中,依然至关重要。两者的区别在于,上下文工程关注的是整个动态数据流的构建与管理,而不仅仅是最终提示的静态文本优化。
小结
大模型应用技术不断深入,我们正从“提示词的艺术”迈向“上下文的科学”。
最近一些爆品如Cursor,Manus等产品都表明,一个卓越的大模型产品,其背后必然是一个精心设计的上下文工程系统。
未来的核心竞争力,将不再仅仅是精妙的提示词,更是高质量、高效率的上下文。
通过精心组织,为模型提供事实依据、注入持久记忆、并扩展其行动能力,我们就有可能释放大模型的潜力,构建出新的有价值AI产品。
参考:https://blog.langchain.com/the-rise-of-context-engineering/
公众号回复“进群”入群讨论。

(文:AI工程化)