
“ 训练数据集的质量是大模型的主要生命线之一,数据集质量直接影响到模型的性能和效果 ”
训练一个高性能且表现较好的模型是由多种因素决定的,比如模型的设计,损失函数与优化函数的实现,训练方式的选择;当然也包括高质量的训练数据。
那么,怎么才能得到一个高质量的训练数据集呢? 这个就是我们今天需要讨论的问题。
训练数据集的准备
机器学习和深度学习模型的性能高度依赖于训练数据的质量和数量;训练数据的准备工作对于构建一个高效可靠的模型至关重要。
然而在实际应用中,很多人都会选择别人准备好的训练数据,或者是忽视训练数据的准备;毕竟作为AI领域的领头羊——openAI公司依然在为训练数据而头疼。
那么,怎么才能准备一个高质量的数据集呢,一般需要经过以下几个步骤:
明确任务
数据采集
数据清洗
数据预处理
数据标注
数据拆分
明确任务
准备数据集的第一步就是要明确需求,你需要训练一个什么样的任务,然后你才能确定数据集需要哪些种类的数据。
比如说,你是做NLP自然语言处理任务,还是做CV计算机视觉类型的图像处理任务等;以及不同种类的不同任务风格。
数据采集
数据采集也包括多个方面:
数据来源
数据来源包括公开数据集,如一些网站提供的数据集;其次是自建数据集,可以通过爬虫,搜索引擎等获取;最后,就是一些领域数据,如医疗,金融,保险等一些非公开数据;可以通过与这些领域的专家或机构合作。当然获取数据的前提都需要合规合法。
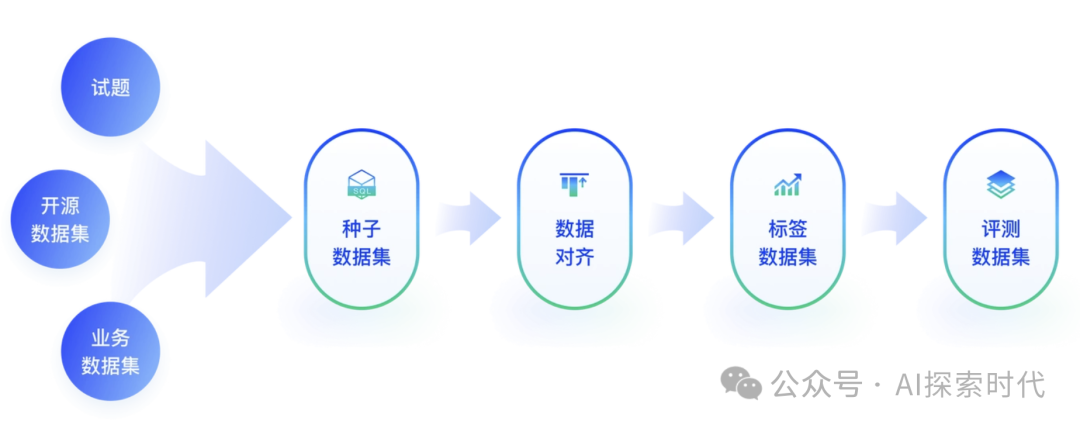
数据多样性
数据多样性的主要目的是保证模型的公平性,防止过拟合或欠拟合现象出现;比如,你想训练一个识别不同种类的狗的模型,如果只使用哈士奇或者金毛,那类似边牧,泰迪等品种就无法识别,导致过拟合现象。
数据质量
数据质量问题是能直接影响到模型训练结果的原因之一,数据集质量越高,训练效果越好;而决定数据集质量的原因也有很多,如数据混乱不一致,数据噪音问题。虽然可以通过数据清洗等手段提升数据质量,但前期准备的数据质量越高,处理起来越方便,效率越高。
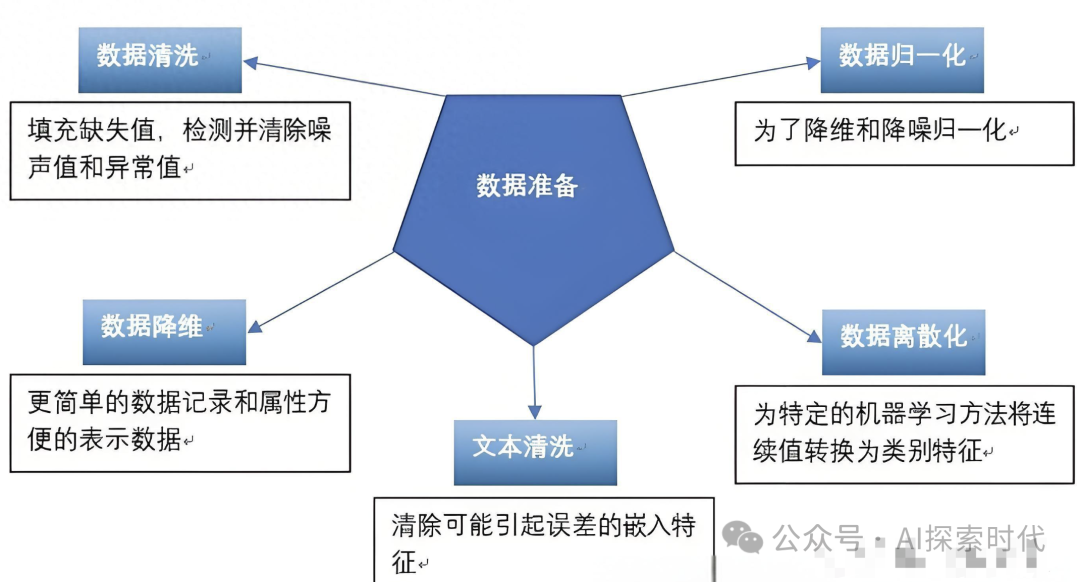
数据清洗
数据清洗可以说是数据准备中比较复杂的一个步骤,因为一般情况下数据来源复杂,数据结构也复杂,而数据清洗需要去除数据中的各种影响因素;包括但不仅限于缺失值处理,异常值检测,噪声过滤等多种情况。
数据清洗的最终目的是去除干扰数据,并把数据整理成统一格式,便于下一步处理。
数据预处理
说到数据预处理可能有些人会有点懵,前面明明已经有数据清洗了为什么还需要预处理?
之所以需要预处理的原因就在于,数据清洗是去除干扰数据,整理成统一格式;而预处理的作用就是把数据处理成模型能够处理的格式,包括特征工程,样本平衡,维度缩减等等多种形式。
举个生活中的例子,数据集准备就类似于做饭前的准备;数据清洗就是要摘菜,洗菜等等;数据预处理就是要把菜切成需要的形状,焯水,加上各种需要的配料等等;最后就等着下锅。
数据标注
数据标注应该说是一个可选的步骤,在监督训练中数据标注必不可少;但在无监督学习中,数据标注就是一个可有可无的步骤;在无监督学习中,你标注了也好,不标注也无所谓。
但数据标注并不是大家所想象的全靠人工标注,目前数据标注的主要方式有自动标注和人工标注;所谓的自动标注就是训练一个标注模型,让它帮我们完成数据标注。
数据拆分
数据拆分就是我们常见的训练数据集,验证数据集和测试数据集;收集到的数据并不是完全都用来进行模型训练,还需要对训练的模型进行验证和测试,这个就是验证集和测试集的作用。
当然,以上只是简单介绍了数据准备的一些主要步骤;其实在具体的数据准备过程中还面临着更多的问题,比如数据增强,版本控制,可视化,隐私保护等等。
总之,目前的预训练模型严重依赖于训练数据的质量问题;因此,模型训练之前的数据准备是一个需要花费大量时间和精力去做的事情,而不是敷衍了事。
(文:AI探索时代)