

极市导读
StepFun多模态团队提出的慢感知(Slow Perception)概念,旨在通过感知分解和感知流动两个阶段,实现对几何图形的精细感知,以提升多模态大模型在视觉推理任务中的表现,目前该团队已在几何parsing任务上进行了初步建模并取得了显著效果。>>加入极市CV技术交流群,走在计算机视觉的最前沿

开源地址:Ucas-HaoranWei/Slow-Perception: Official code implementation of Slow Perception:Let’s Perceive Geometric Figures Step-by-step
论文地址:https://arxiv.org/abs/2412.20631
前言:
慢感知是StepFun多模态团队对视觉system2的初步探索。研究人员认为:1)目前多模领域o1-like的模型,主要关注文本推理,对视觉感知的关注不够。2)精细/深度感知是一个复杂任务,且是未来做视觉推理的重要基础。而思想之一是如何把感知做“慢”,即通过某种任务拆解(step-by-step)实现感知层面的inference time scaling。这里有个简单的例子:
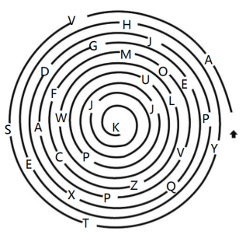
题目是:按照螺旋线的顺序,报出每个字母。 这是一道5岁小孩的测试题,但是目前国内外还没有一个多模模型能够正确解答。该题让人来做的话,会先感知并trace这条螺旋线,在attention到字母的位置将其记录下来,越靠近螺旋线中心,字母挨得会近一些,我们trace的速度也会更慢一点,即申请一部分额外“推理计算量”,以保证不会出错。 很明显,这是典型的视觉o1任务,且该过程似乎不太需要偏文本的做题式“思考”,它更偏向于深度“感知”。
基于以上分析,研究人员提出了慢感知(slow perception)的概念,主要想传达的是,不仅思考需要慢下来,感知同样需要。作者选择几何parsing任务对慢感知进行初步建模,原因主要有三点:1)文本reasoning向的多摸态o1-like模型经常pr做几何题,但如果模型连准确地copy几何都做不到,怎么可能真正理解几何内部复杂的点线关系;2)几何parsing任务其实足够难,一直被大家overlook,目前国内外没有一个多模态大模型能做好这件感知任务;3)几何图形是人对自然场景的抽象,想把system2视觉模型做general,总得先从描一根线开始。
方法&实验:
慢感知(slow perception)分为两个阶段:
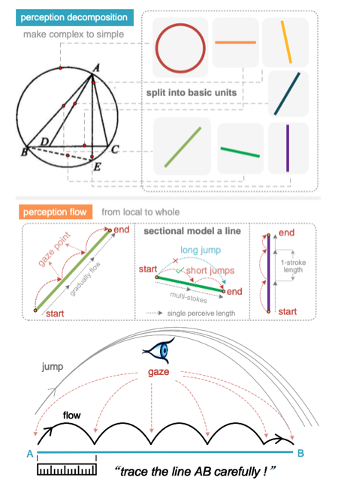
第一阶段称为感知分解(perception decomposition),该过程将几何图形分解为基本的形状单元 ——线:不管是几边形,都是由最基本的线构成。这样做的好处是可以统一复杂的几何表征,一定程度上避免多峰优化问题。如图1中有8个三角形,而且互相嵌套,直接让模型写matplotlib/tikz代码都会遇到多峰问题。这一阶段的目的是“化繁为简”。
第二阶段,作者称为感知流动(perception flow)。人在trace一条线的时候,尤其是长线,很难一笔到位,即对于长程依赖的感知决策,不太会出现1-hop-1-decision,对模型来说也是一样。作者受人使用尺子配合眼动的描线过程启发(如图1下),提出了perception flow。
具体地,模型基于一个虚拟的感知尺(perceptual ruler),从线段的初始点逐步描向终止点。作者把“眼动”过程中停留的位置称为gaze(凝视点),对于一条长于感知尺的线段,整个感知过程被建模为在一个决策点通过多次眼跳到达下一个决策点的过程(multi-hop-1-decision)。感知尺的长度在一次训练中是固定的,这样短线和长线的推理计算量变得不同,这更符合直觉与上文的分析。当然感知尺长度在训练前可以随意设置,作者发现其长度设置的越短,几何解析的性能越好。感知尺短说明模型描一条线用的推理计算量大,即慢感知建模方案存在感知层面的inference time scaling。
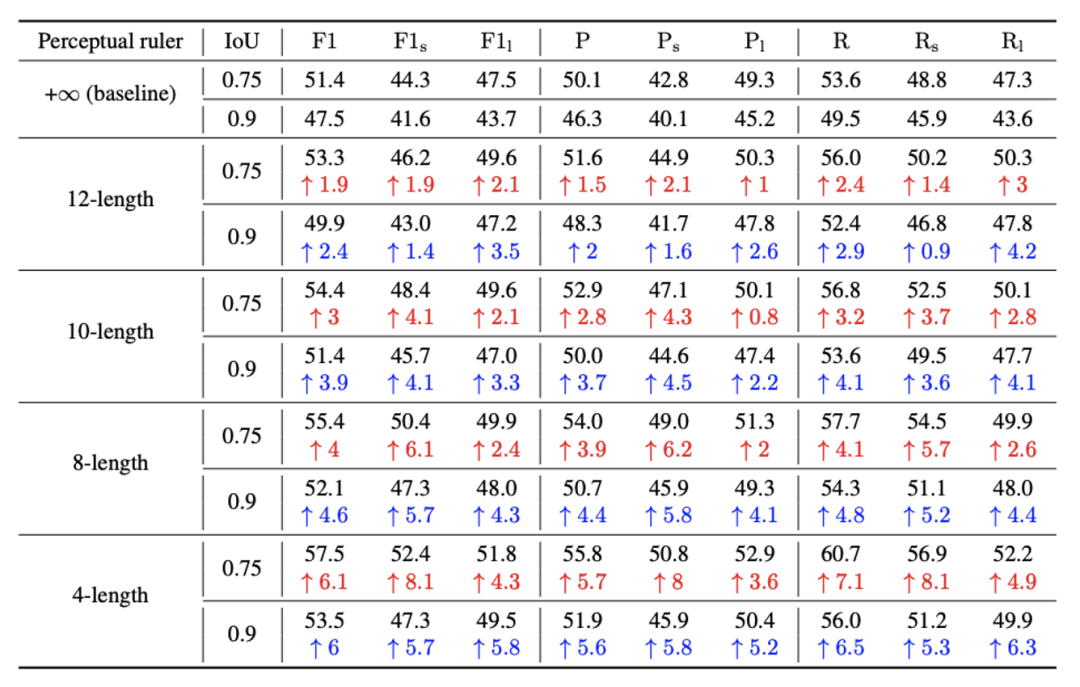
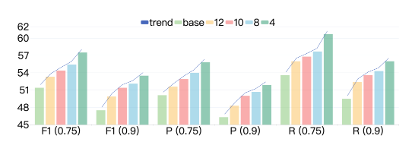
如上表1所示,baseline代表感知尺无限长,即所有线段均从初始点直接预测终止点。n-length代表感知尺长度为n,n是matplotlib绘制距离,所有几何图形绘制在-10到10的坐标系中。可以看到感知尺长度从12到4,所有指标(包括F1,Precision,Recall)都在上涨。感知尺越短,描一根线的停顿(gaze点)越多,计算量越大,inference time也会越久。图2展示了慢感知inference time scaling的趋势。
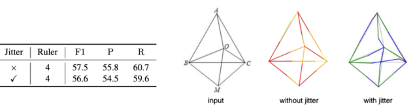
为了验证感知流动是否依赖精准的凝视(gaze)点,作者抖动了gaze点真值进行训练和测试,对比结果如图3所示。可以看到即便是基于抖动过的gaze点,模型性能依旧远高于baseline(56.6% F1 vs. 51.4% F1),也仅比不抖动的情况低了1%:慢感知最关键的是要建模一种从初始决策点到下一个决策点感知的正确流向,而中间的具体过程可能没有那么关键。这一结论会大大降低将该方法用在通用场景上的标注难度。
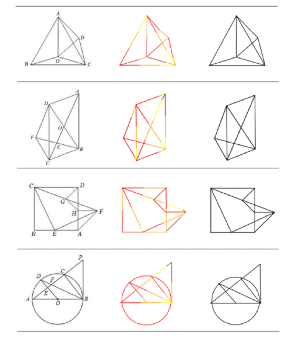
更多可视化结果如图4所示,左边是输入,中间是slow perception每一笔的可视化,笔画顺序用彩虹色(红-橙-黄-绿)表示,最后一栏是最终几何解析的效果。
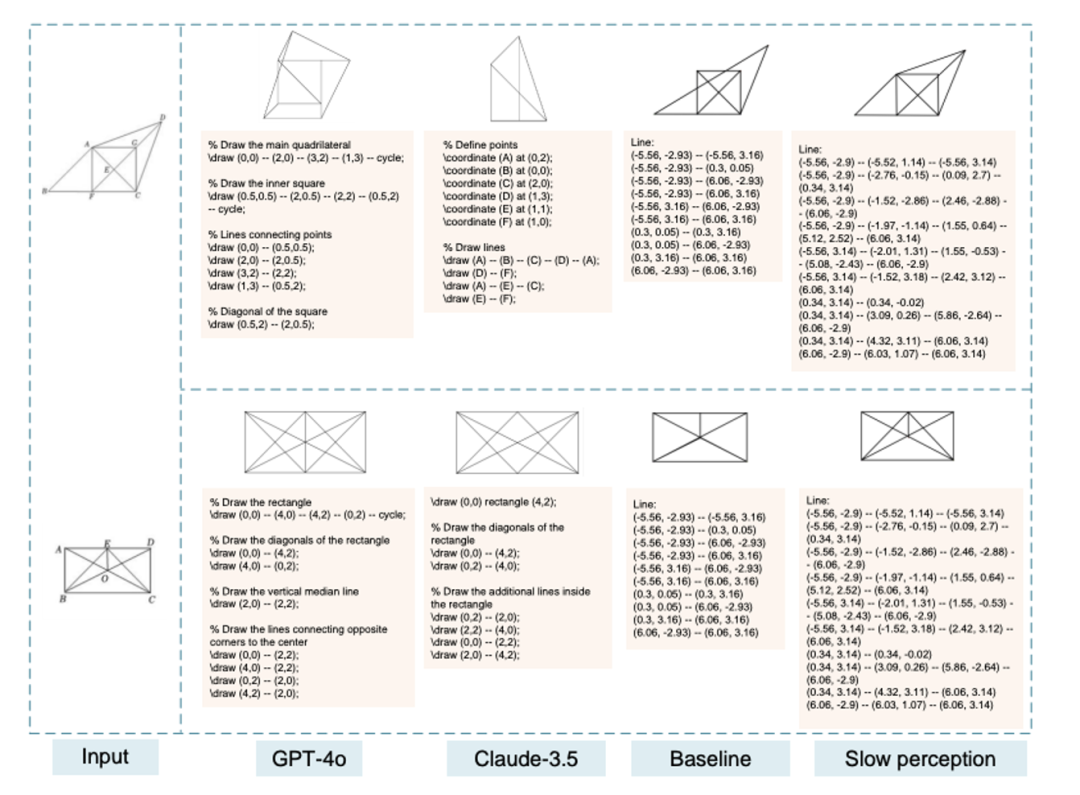
不同多模态大模型几何解析能力对比如图5所示,可以看到慢感知建模方案使得模型对几何线段的感知能力更强。更多有趣的结论和效果请看原文https://arxiv.org/abs/2412.20631。
结论:
当前基于system1感知的多模态大模型,看图过轻,感知不够精细,这限制了其进一步发展:当我们拿着一张片子给医生看,而医生不到1秒钟就看完了,告诉你啥事没有,我们会请他再看看,要求他看的再仔细点。LVLM想要有更多的落地场景,system2感知能力是第一步,感知要慢下来。slow perception是研究人员基于几何parsing任务,在视觉sys2上的初步探索,他们也在积极往更通用的任务上迁移,并取得了初步的效果。大家敬请期待。

(文:极市干货)
哇塞,这个慢感知的概念看起来好强!多模态大模型的视觉解析能力简直上天了!
这种慢感知的概念真是够逗比的!多模态大模型在视觉推理上简直看图过轻,连基础的几何解析都做不好。好家伙,这不就是给系统2当 Makesense 的角色吗?