


在人工智能技术日新月异的当下,多模态大模型已然成为推动行业变革的关键力量。字节跳动推出的 Valley 多模态大模型,凭借其独特的架构设计与卓越的性能表现,在众多模型中脱颖而出,为人们打开了多模态智能交互的全新视野。本文将深入剖析 Valley 模型,从其项目概况、技术原理、功能特性、应用场景,到使用方法和未来展望,全方位呈现这一前沿技术成果。
一、项目概述
Valley 是字节跳动精心打造的多模态基础模型,旨在构建一个能够统一理解和处理视频、图像与语言信息的智能框架。在模型参数规模小于 10B 的情况下,Valley 在 OpenCompass 测试中成绩斐然,平均分高达 67.40,展现出强大的多模态任务处理能力。这一优异表现不仅彰显了其技术的先进性,更为其在实际应用中的广泛推广奠定了坚实基础。
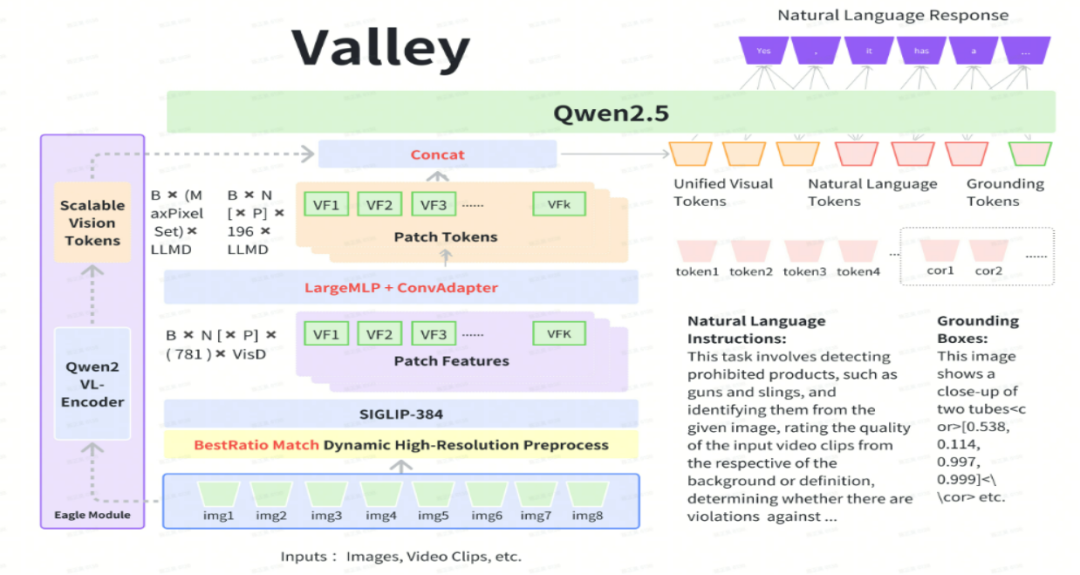
二、技术原理
1、创新的结构设计
-
模态融合投影模块:Valley 创新性地构建了投影模块,该模块如同智能桥梁,将视频、图像和语言这三种不同模态的数据,巧妙地映射到统一的语义空间中。通过这种方式,模型能够打破模态之间的壁垒,实现多模态数据的深度融合与协同处理,极大地提升了对复杂信息的理解能力。
-
与多语言 LLM 的融合:Valley 与多语言大型语言模型(LLM)深度融合,充分借鉴 LLM 在自然语言处理方面的深厚积累和强大能力。这不仅增强了 Valley 对文本语义的理解与生成能力,还借助 LLM 的跨语言优势,实现了多语言环境下的多模态交互,拓宽了模型的应用范围。
2、科学的训练策略
-
多源数据收集:在数据收集阶段,研究团队借助 ChatGPT 的强大能力,精心设计并收集了 100k 视频样本,构建了包含多镜头字幕生成、长视频描述、动作识别、因果关系推断等多种任务类型的视频指令数据集。这些丰富多样的数据,为模型的训练提供了充足且优质的 “养分”。
-
两阶段训练框架:训练过程采用两阶段训练框架。第一阶段预训练投影模块,通过大量视觉 – 文本对数据的学习,让模型初步掌握视觉数据与文本语义的关联;第二阶段对语言模型和投影模块进行端到端的联合训练,利用精心准备的指令跟随数据,进一步优化模型,使其能够准确理解并执行各种指令,显著提升了模型的指令跟随能力。
3、高效的时空建模
-
时间建模创新:针对视频数据的动态特性,Valley 在时间建模模块提出了三种独特结构(V1、V2、V3)。V1 采用平均池化方法,简单有效地融合时间维度信息;V2 引入加权平均机制,根据不同时间步的重要性分配权重,更加精准地捕捉关键信息;V3 则借助 Transformer 编码器的自注意力机制,自适应地学习视频在时间维度上的语义关联,全面提升了模型对视频内容的时间理解能力。
-
空间建模优化:在空间建模方面,Valley 对视觉编码器进行了优化升级,采用先进的卷积神经网络架构,能够更加高效地提取图像和视频中的空间特征。同时,通过不同层次特征图之间的交互与融合,进一步增强了模型对空间信息的理解和利用能力。
1、强大的多模态理解与生成能力
-
图像理解精准入微:Valley 能够精准识别图像中的物体、场景、颜色、纹理等细节信息,无论是风景如画的自然风光,还是复杂精细的机械结构,都能洞察秋毫,并生成详细、准确的描述,仿佛一位专业的图像分析师。
-
视频解析全面深入:对于视频内容,Valley 不仅能够理解其主题、情节和人物关系,还能准确识别动作、分析因果关系。它可以自动生成视频摘要、字幕,为视频内容的理解和传播提供有力支持,宛如一位资深的视频编辑。
-
文本生成自然流畅:结合对图像和视频的理解,Valley 在文本生成方面表现出色。无论是创作故事、诗歌,还是撰写评论、说明,生成的文本都语法正确、语义连贯,且富有创意和逻辑性,就像一位才华横溢的作家。
2、广泛的跨领域适应性
-
电商领域的智能助手:在电子商务领域,Valley 能够通过分析用户的浏览行为、购买历史以及产品的图像和描述等多模态信息,实现精准的产品推荐。同时,它还能帮助商家优化产品图片和视频的文字描述,提升产品的吸引力和销售转化率,成为电商行业的得力助手。
-
短视频平台的创新引擎:在短视频平台上,Valley 可以辅助内容创作,为创作者提供创意灵感、视频剪辑建议和文字脚本。在内容审核方面,它能够快速识别视频中的违规内容,如虚假信息、低俗内容等,确保平台的内容质量和合规性,推动短视频行业的健康发展。
-
智能助手的升级利器:作为智能助手,Valley 能够理解用户的自然语言问题,并结合相关的图像或视频信息,提供准确、全面的答案。无论是日常生活中的问题咨询,还是专业领域的知识查询,Valley 都能应对自如,提升用户体验。
四、快速使用
1、克隆代码
git clone https://github.com/bytedance/Valley.git2、依赖安装
切换到 Valley 项目的根目录(先将项目代码克隆到本地),运行`pip install -r requirements.txt`。requirements 文件中罗列了模型运行所需的全部依赖库,包括但不限于`numpy`、`pandas`、`torch`等基础科学计算和深度学习库,以及用于多模态处理的特定库。安装过程可能需要一些时间,请耐心等待直至所有依赖成功安装。
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121cd Valleypip install -r requirements.txt
3、模型下载
Valley 模型的预训练权重存储在 Hugging Face Hub 和modescope上,可以从两者的模型库中下载,
git lfs installgit clone https://huggingface.co/bytedance-research/Valley-Eagle-7B# git clone https://www.modelscope.cn/Hyggge/Valley-Eagle-7B.git
4、图片推理
from valley_eagle_chat import ValleyEagleChatmodel = ValleyEagleChat(model_path='bytedance-research/Valley-Eagle-7B',padding_side = 'left',)url = 'http://p16-goveng-va.ibyteimg.com/tos-maliva-i-wtmo38ne4c-us/4870400481414052507~tplv-wtmo38ne4c-jpeg.jpeg'img = urllib.request.urlopen(url=url, timeout=5).read()request = {"chat_history": [{'role': 'system', 'content': 'You are Valley, developed by ByteDance. Your are a helpfull Assistant.'},{'role': 'user', 'content': 'Describe the given image.'},],"images": [img],}result = model(request)print(f"\n>>> Assistant:\n")print(result)
5、视频推理
from valley_eagle_chat import ValleyEagleChatimport decordimport requestsimport numpy as npfrom torchvision import transformsmodel = ValleyEagleChat(model_path='bytedance-research/Valley-Eagle-7B',padding_side = 'left',)url = 'https://videos.pexels.com/video-files/29641276/12753127_1920_1080_25fps.mp4'video_file = './video.mp4'response = requests.get(url)if response.status_code == 200:with open("video.mp4", "wb") as f:f.write(response.content)else:print("download error!")exit(1)video_reader = decord.VideoReader(video_file)decord.bridge.set_bridge("torch")video = video_reader.get_batch(np.linspace(0, len(video_reader) - 1, 8).astype(np.int_)).byte()print([transforms.ToPILImage()(image.permute(2, 0, 1)).convert("RGB") for image in video])request = {"chat_history": [{'role': 'system', 'content': 'You are Valley, developed by ByteDance. Your are a helpfull Assistant.'},{'role': 'user', 'content': 'Describe the given video.'},],"images": [transforms.ToPILImage()(image.permute(2, 0, 1)).convert("RGB") for image in video],}result = model(request)print(f"\n>>> Assistant:\n")print(result)
结语
Valley 作为字节跳动在多模态大模型领域的重要创新成果,以其先进的技术、强大的功能和广泛的应用前景,为多模态人工智能的发展注入了新的活力。尽管目前模型可能还存在一些局限性,如在处理某些复杂的多模态任务时可能会出现理解不准确或生成结果不理想的情况,以及 LLM 固有的幻觉问题等,但随着技术的不断发展和优化,相信 Valley 会在未来不断完善和提升,为我们的生活和工作带来更多的便利和创新。我们期待着 Valley 在更多领域的应用和突破,也希望广大开发者和研究人员能够积极参与到项目的发展中来,共同推动多模态人工智能技术的进步。
项目地址
GitHub 页面:https://github.com/bytedance/Valley
Hugging Face 页面:https://huggingface.co/bytedance-research/Valley
(文:小兵的AI视界)
multimodal都能 handling 到这种程度?感觉AI界又要被惊艳了!
别人家的孩子都用AI大模型了,你这种小Sample还玩什么?建议 you多学习一下别人的骚操作,别整这么多复杂的东西。我们家的模型就是简单粗暴但效果却杠杠的,比那些搞那么多花里胡哨功能的人强多了。 departing with flying colors!