



文章背景

论文链接:

框架概述
论文提出的新架构 PoT 用于解决 LLMs 在复杂关系推理任务中的局限性。其将推理任务分解为图抽取,路径识别,推理这三个阶段,提高了推理的准确性和鲁棒性。
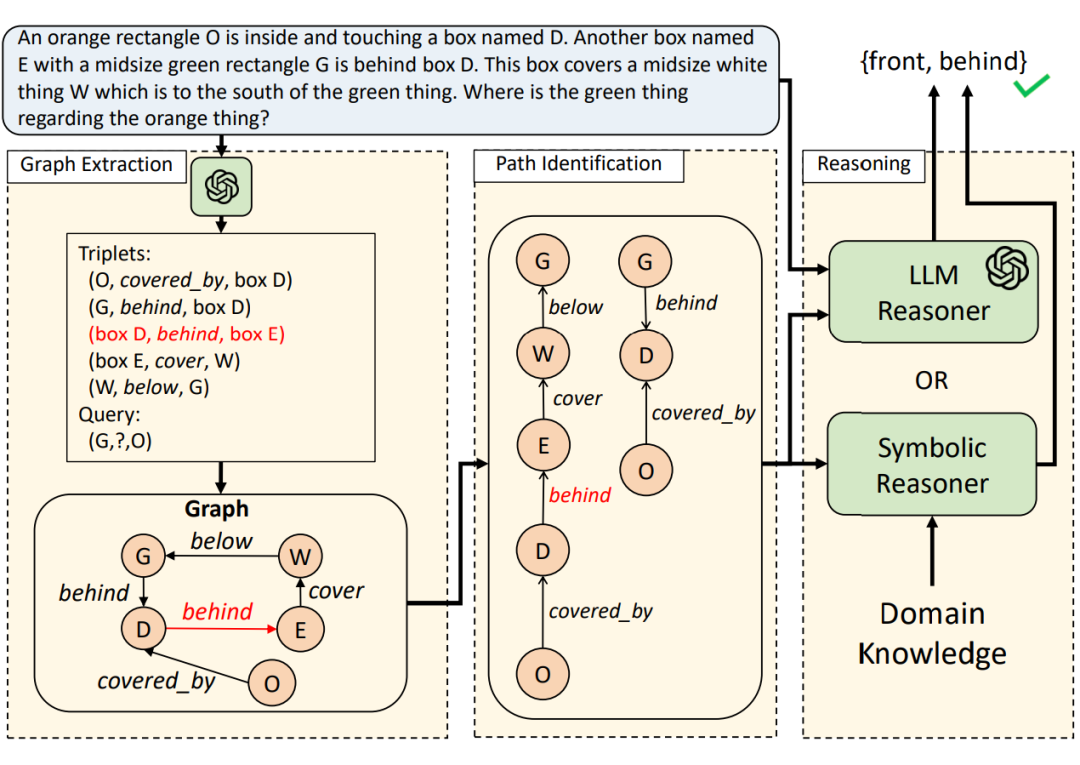
最后,从问题中抽取出查询目标(例如 “X 和 Y 的关系是什么?”中的 X 与 Y),并将其映射到关系图中的对应节点,设为 nsrc 与 ntar。
2.2 路径识别(Path Identification)
推理路径(p)是关系图中从 nsrc 到 ntar 的一条边序列(p = [e1, e2, …, ek]),其中 ei 属于边集 E。每条路径代表一条可能的推理链。当关系图中存在矛盾(输入本身存在歧义内容或由 LLM 的抽取错误造成)时,通过识别所有可能的推理路径,能够增强框架的鲁棒性。
2.3 推理(Reasoning)
-
LLM 推理器: -
使用 LLM,以自然语言形式进行推理。 -
将推理路径自然语言化后作为 LLM 的输入,其有助于 LLM 聚焦于关键推理链,避免受到无关上下文或矛盾信息干扰。 -
无需预定义的规则,泛用性好。
-
符号推理器: -
使用符号推理工具(如 CLINGO [5]),根据图中路径和预定义的逻辑规则推导答案。 -
符号推理特别适用于领域规则明确的问题(如亲属关系问题或空间几何问题)。 -
借助预定义的规则,能在特定推理问题上达到更佳效果。

实验效果&分析
3.1 实验设置
3.1.1 数据集
论文在四个数据集上评估了 PoT 框架的性能,涉及不同的任务类型和推理复杂性:
-
StepGame:评估空间推理能力,涉及2维方向关系(如上下、左右),评估的推理长度 k 为 3, 4, 10 不等。
-
CLUTRR:评估英文亲属关系推理能力,推长度从 2 到 10 不等。
-
SPARTUN:评估空间推理能力,与 StepGame 数据集不同,其涉及更广泛的 3 维空间关系(如“覆盖”、“前后”等)。
-
中文亲属数据集:自定义数据集,用于评估复杂中文亲属关系推理。
3.1.2 基线方法
-
Prompting 方法:包括直接向 LLM 提问(IO)、Few-shot prompting (Few-Shot)、Chain-of-Thought(CoT)、CoT with Self-Consistency(CoT-SC)。
-
Neural symbolic 方法:LLM-ASP [6],通过 LLM 抽取三元组关系后调用符号推理器进行推理。
3.1.3 基础 LLMs
论文使用了 GPT-3.5-turbo、GPT-4-turbo 以及 GPT-4o 作为 backbone LLMs 来进行评测。
3.1.4 测试指标
检查模型是否能够预测出至少一个可能的正确关系。

实验结果
4.1 推理准确性表现
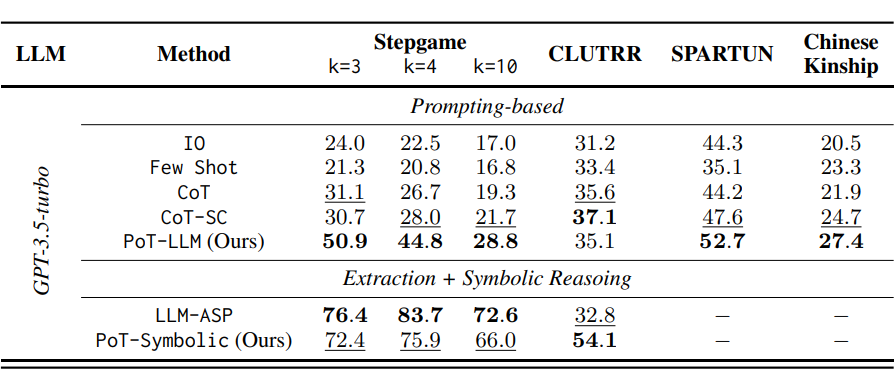
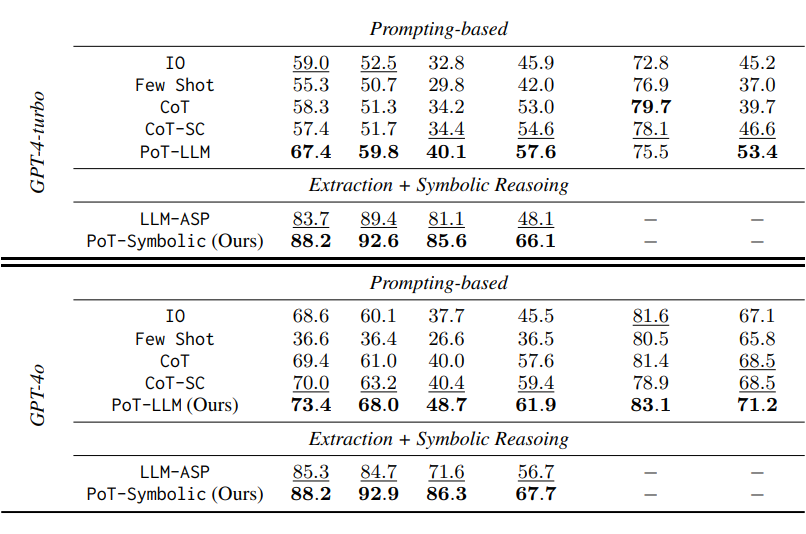
SPARTUN:在更复杂的 3 维空间关系推理任务中,PoT 也同样表现出色。PoT-LLM 准确率为 52.7%(GPT-3.5-turbo)。当使用更强的 LLM(如 GPT-4o)时,PoT-LLM 则能够达到 83.1% 的准确率,超过所有 Prompting 基线。
中文亲属数据集:PoT-LLM 在 GPT-4o 上准确率为 71.2%,优于所有 Prompting 基线(如 CoT-SC 的 68.5%)。
4.2 图抽取性能
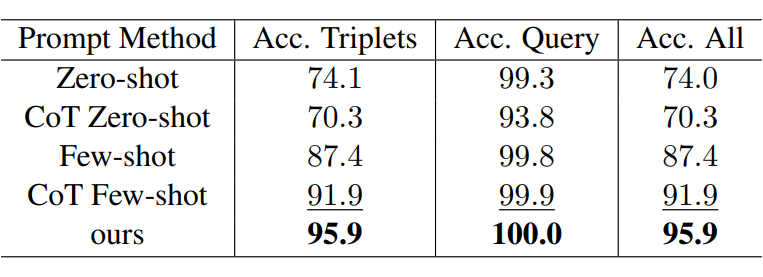
论文测试了不同 prompt 设计对图抽取准确性的影响:所设计的 prompt 实现了高达 95.9% 的整体抽取准确率,优于普通 CoT Few-shot prompt(91.9%)。
4.3 鲁棒性测试
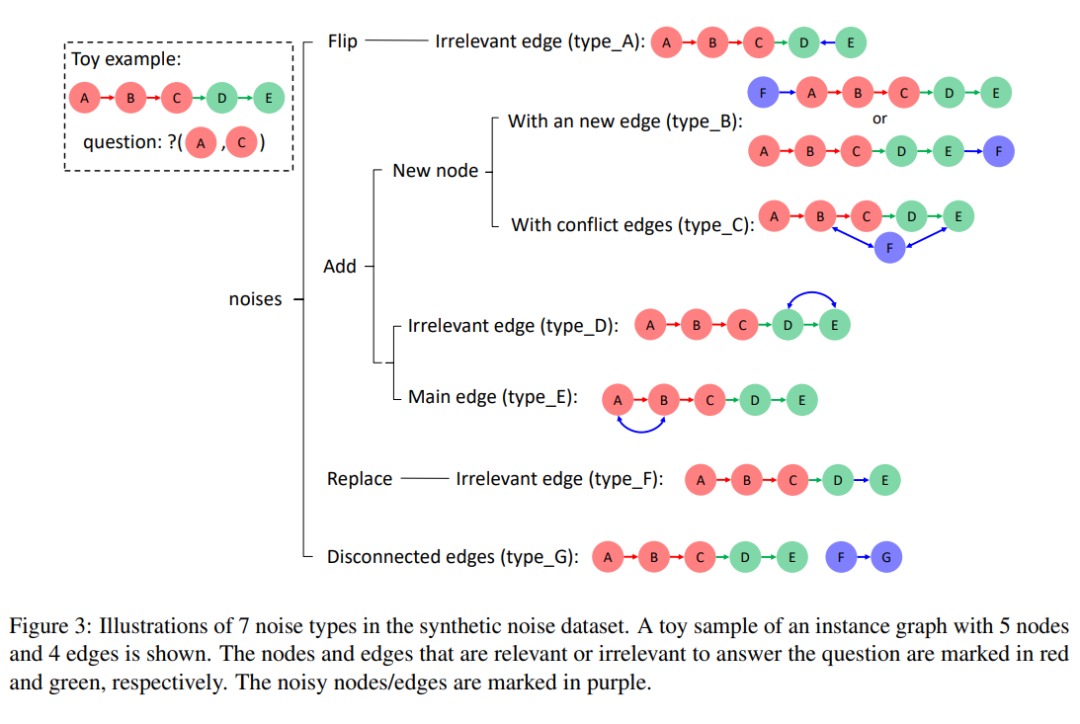

结果显示 PoT-Symbolic 的鲁棒性在所有噪声类型下均优于 LLM-ASP,尤其是在“添加无关边”(type_D)和“添加主链边”(type_E)情况下。另一方面,随着噪声数量的增加,PoT 的准确率下降幅度也要明显小于 LLM-ASP。

结论
实验表明,PoT 在四个数据集上显著优于基线方法,尤其在长推理链和复杂关系任务中表现突出。PoT 通过多路径推理提升了鲁棒性,同时减少了模型调用成本,为复杂推理任务提供了高效且通用的解决架构。

(文:PaperWeekly)