

一项有望引爆万亿级具身智能市场的重大技术突破诞生了!
来自清华大学与千诀科技的研究团队基于在全球顶级AI会议ICLR2024上发布突破性成果,首次实现了多模态大模型的类脑化,率先实现了业界首个可规模部署的类脑计算框架!这一技术创新不仅大幅降低了AI大模型75%的部署成本和能耗,更令人瞩目的是其广泛的硬件兼容性 – 可同时支持NVIDIA GPU、华为昇腾、灵汐等各类主流计算平台,为企业快速低成本落地具身智能应用开辟了全新途径!
该技术作为“中国脑计划”(科技创新2030)的核心成果之一,一经发表便受到资本市场高度关注。基于该成果的创新技术已形成多项核心专利,为公司在快速增长的具身智能市场奠定了坚实的技术壁垒。
当前,多模态大模型已成为开发通用智能机器人的关键技术路线。然而,随着模型规模的不断扩大,高昂的部署成本和能耗已成为制约产业发展的最大瓶颈。特别是在机器人等终端设备上,大模型的庞大计算需求与有限的算力资源之间的矛盾日益突出。千诀科技创新性地将类脑计算原理引入大模型部署场景,不仅解决了这一技术难题,更开创了一个全新的商业机会。

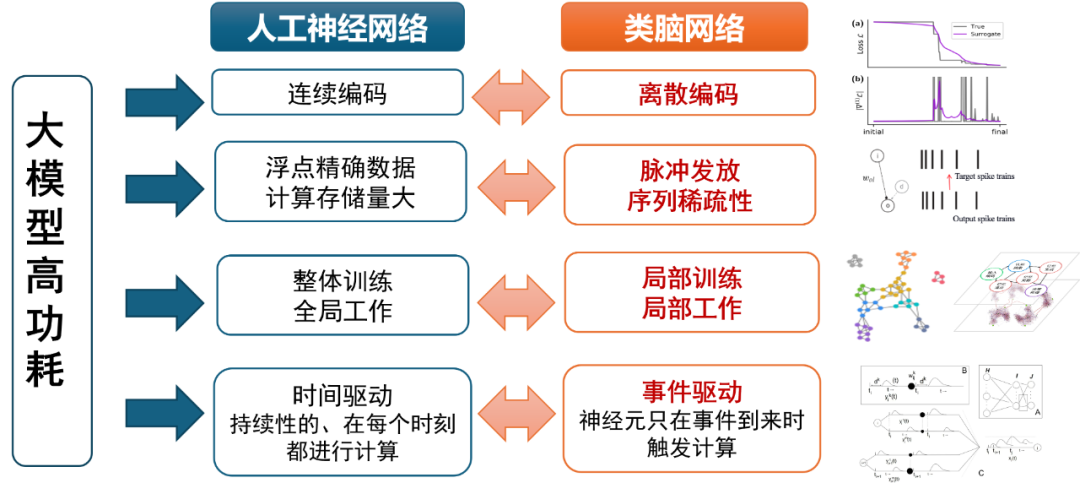
▍下一代人工神经网络:类脑大模型的优势与挑战
不同于传统神经网络使用连续的浮点数进行计算,类脑网络采用脉冲神经元,通过离散的0/1信号传递信息。这种计算模式直接受到生物神经系统的启发,具备了更稳定、更低功耗的相对优势。
在人脑中,神经元细胞体内具有复杂的非线性信息处理能力,而细胞之间着是通过“放电”与“不放电”的二值信号来传递信息。类脑计算模拟了这一机制,使得整个网络的工作方式更贴近生物神经系统,具有更好的生物可解释性。

这种离散编码方式带来了显著优势:首先,类似于数字电路相比模拟电路的优势,二值信号比连续值更稳定,抗噪声能力更强。其次,这种编码方式特别适合构建大规模模型,其可在多个层级上模拟不同尺度的仿脑架构,并采用脉冲信号在模块间动态地构建信号通路,从而灵活调动下游子模,块,实现局部学习与推理。
类脑计算最大的亮点在于分布式训练和推理,展现出卓越的边缘端部署优势。传统深度学习需要进行大量的浮点运算,而类脑网络采用事件驱动的计算方式 – 只有在神经元发放脉冲时才会产生计算。因此,若能将大模型类脑化,则可以在不影响推理性能的基础上,实现对大模型的解耦和模块化的训练以及推理,实现样本规模指数级降低和模型尺寸缩减的同时并将其部署到多块边缘端小型芯片中。进一步地,展现出低功耗的优势。
论文展示的实验数据表明,在执行相同的非线性运算(如GELU)时,类脑实现可以比传统方法节省41%的计算开销。在注意力机制的矩阵运算中,节省幅度更是可达75%。这种特性使得类脑网络在边缘计算等资源受限场景下具有独特优势。
▍技术解析:基于时空近似的无训练类脑转换方案
类脑计算在此前的发展中也面临着不小的挑战: 由于脉冲神经元的非连续性,难以直接使用反向传播等传统训练方法直接训练大规模类脑神经网络,同时训练数据和标准化问题也制约其发展。
这些困难导致类脑网络研究停留在局部小尺度、固定计算规则下的简单、精确建模,缺乏对大规模、深层网络的准确学习与推理能力,也难以像人脑一般具备通用任务上的大规模知识理解与泛化能力。这导致直接训练与现有主流大模型对标的大规模类脑网络仍然是一个悬而未决的问题。不过值得欣喜的是,研究团队提出了一种巧妙的转换方案,充分结合现有预训练大模型的知识和规模优势,为绕过直接训练开辟了新的可能。
由清华大学博士、千诀机器人脑坞产品技术总监蒋屹舟带领的团队提出的时空近似(STA)方法,首次实现了将预训练Transformer直接转换为类脑网络,而无需重新训练。这一突破性工作打开了类脑计算落地应用的新思路。此前类脑网络要么需要从头训练,性能有限且成本高昂;要么仅能转换CNN这类简单网络。而基于STA的方案不仅继承了预训练模型的强大性能,还保持了类脑计算的能效优势。
在传统Transformer中,复杂的非线性函数和注意力机制的矩阵乘法是两大难以直接用类脑网络实现的运算。团队创新性地提出了空间和时间两个维度的近似方案来解决这一问题。
在空间维度,团队设计了通用群算子(UGO)来处理非线性计算。它用一组相互协作的脉冲神经元来模拟GELU、LayerNorm等复杂函数。这些神经元群组通过合成数据预先训练,因此可以广泛应用于不同场景。理论分析表明,这种近似方式的误差是有界的,可以通过调整神经元数量来平衡精度和效率。值得一提的是,该方案为复杂运算的分段线性化实现提供了通用策略,目前已在类脑计算、光学计算等多个相关领域得到推广应用。
在时间维度,团队提出了时序修正自注意力层(TCSA)来实现矩阵乘法。它采用估计-修正的方式,先基于已有的输入序列预测可能的输出,再根据实际输入进行修正。这种方式不仅确保了计算的准确性,还显著改善了脉冲神经元的发放稳定性,在类脑Transformer领域存在多项延续性工作。
这种新颖的转换方案在多个方面展现出独特优势。首先是计算效率的大幅提升。在执行GELU等非线性运算时,通用群算子可以节省41%的计算量。在注意力层的矩阵运算中,采用时序修正机制最高可节省大量的计算开销。这种节省得益于类脑网络事件驱动的特性,只有在必要时才进行计算。
其次是出色的稳定性表现。理论分析证明,时序修正机制的估计误差会随时间呈二次下降,最终趋于稳定。这不仅保证了计算结果的可靠性,还使得神经元的脉冲发放更加均匀,避免了传统方法中不均匀的脉冲输出和性能下降的问题。
更重要的是,这种方案极大地降低了部署门槛。它无需对网络进行重新训练,完全采用事件驱动方式运行,特别适合在神经形态计算硬件上部署,从而支持现有机器人解决方案向边缘端的高效迁移。
▍实验验证:类脑ViT性能评测全面领先
清华团队在论文中,以CLIP中的ViT-B/32所对应的视觉感知任务为基准进行了大规模实验验证。结果显示,转换后的类脑网络不仅保持了原模型的零样本分类能力,在多个标准数据集上的表现更是令人瞩目。
实验首先验证了转换后模型的零样本分类性能。在CIFAR-10数据集上,转换后的类脑ViT达到了87.71%的准确率,仅比原模型的89.74%略有下降。这个结果远超基于ResNet-50的传统转换方法,后者的准确率仅为64.08%。更令人惊喜的是,即便在更具挑战性的CIFAR-100和ImageNet-200数据集上,类脑ViT依然保持了强劲表现。

为了测试模型的泛化能力,研究团队特别在CIFAR-10.1和CIFAR-10.2这样的分布偏移数据集上进行了验证。这些数据集的图像条件(如光照、角度等)与校准所用的小规模CIFAR-10子集有明显差异。结果显示,类脑ViT在这些具有挑战性的场景中依然表现出色,准确率保持在80%以上,展现出强大的鲁棒性。这为类脑感知模型在通用任务上的泛化性能提供了保障。
传统类脑网络通常需要较长的仿真步数(>128步)才能达到理想性能。得益于时空近似方案的创新,本文提出的方法只需32或64步就能达到接近峰值的准确率。这一突破意味着在实际应用中可以显著减少计算延迟,提高响应速度。通过结合异构融合类脑计算芯片,并针对其计算特性提出稀疏优化策略,这一数值可被进一步降低到8步以下,从而进一步降低其在真实场景下的实用功耗。
在能耗评估方面,研究表明类脑转换后的模型展现出显著优势。通过实验证实,在注意力层的矩阵运算中,采用脉冲神经元实现可以节省33%-75%的核心突触计算和Cache能耗。这种节省主要得益于事件驱动的计算模式和布尔逻辑运算的采用。
▍从大模型到类脑计算:机器人应用的实践探索
这项技术的重要意义在于为类脑计算打开了对接大模型生态的通道。由于保持了零样本学习等高级能力,转换后的模型可以直接应用于复杂场景。研究团队指出,这种转换方法的应用范围远不限于视觉Transformer,相同的原理已扩展到CLIP的简单文本编码器,GLIP开放物体检测模型所使用的类BERT文本编码器,甚至7B或更大规模的生成式语言模型。
在机器人行业,众多企业和客户已建立起完整的传统服务体系,包括各类检测方案等任务模块。这些任务模块或来自开源训练模型,或通过传统大模型微调获得。针对这些现有模型系统,研究团队提出的类脑转换方案开创了一条新的优化路径,能够将传统模型直接转换为类脑形式。这种转换无需额外训练数据,可快速完成,并保持原有模型的功能等效性。通过在机器人上部署类脑芯片,不仅实现了低功耗运行,还提升了系统稳定性。
更进一步,千诀科技所提出的类脑模型在设计阶段就充分结合了类脑模型的大规模、分层多模块多尺度特性,并对类脑硬件突触算子具备良好的兼容性,从而获取了比传统大模型类脑转化所更优的性能。
此外,现代智能机器人系统对高性能、高鲁棒性和低功耗的板载及边缘计算能力有着严格要求。基于类脑计算方法的创新设计,可在各类边缘计算设备上实现轻量化和隐私化部署,通过稀疏的脉冲计算机制确保低功耗实时推理,并依托变结构脉冲网络设计提供卓越的多任务处理能力和环境适应性。
依托类脑大模型的小样本学习、低功耗、分布式边缘端部署的优势,研究团队联合千诀科技,打造了边缘端部署的类脑大模型具身产品——脑坞,并已在实践中取得突破性进展,成功将具身大脑在多款不同形态的机器人上实现“完全边缘端部署”,摆脱了对云端算力的依赖,成功实现了超长时程的复杂任务,更首次完成了基于双臂机器人的塑料袋打结任务,充分展示了类脑计算在复杂动作控制方面的优势。

总体来说,这项研究的成功标志着类脑计算在工程实践上取得重要突破。它不仅解决了类脑网络难以实现复杂模型的技术瓶颈,还提供了一条低成本、高效率的落地路径。随着神经形态计算硬件的进一步发展,这种转换方案有望推动类脑计算在更多实际场景中发挥作用。
更重要的是,这项工作为未来研究指明了方向。通过深入优化群算子训练和乘法估计策略,还可以进一步提升能效比。结合最新的神经形态硬件与原始类脑模型设计,有望实现浮点运算和事件驱动计算的协同,带来更优的综合性能。
▍具身智能的新篇章:类脑计算引领机器人大脑革命
对具身智能领域而言,这一技术突破具有革命性意义。具身智能强调智能体通过与环境的物理交互来获取和处理信息,这与类脑计算的特性高度契合:
首先,类脑计算的事件驱动特性能够支持具身大脑的实时决策-行动闭环。传统大模型往往难以处理连续动态交互过程,而类脑计算的脉冲机制天然适合处理时序信息,如前文展示的双臂机器人打结任务就充分体现了这一优势。
其次,分布式的计算架构不仅提升了边缘计算效率,更重要的是支持了类似生物神经系统的分层感知与决策。这种架构使得机器人能够同时处理不同时间尺度的任务,从快速反射动作到长期规划都能得到有效支持。
更关键的是,类脑模型的层次化结构为多模态信息的融合提供了理想框架。在具身场景中,机器人需要综合处理视觉、触觉、力反馈等多种感知信息,并与运动控制紧密耦合。实验证明,类脑化后的模型在这类复杂交互任务中展现出独特优势。
这项技术为具身智能带来了三个关键突破:
1.实现了将真正的机器人“大脑”端侧部署,使机器人能够独立完成复杂的感知-决策任务,而不仅仅实现小脑操作。
2.显著降低了能耗,支持机器人在真实环境中持续运行与学习。
3.提供了灵活的模块化架构,能够根据不同交互场景灵活组合与优化感知-决策-控制多个具身模型。
当前,具身智能市场正迎来爆发性增长。据权威机构数据显示,该市场规模从2018年的2,923亿元快速增长至2023年的7,487亿元,年复合增长率高达20.7%。更值得关注的是,预计到2026年市场规模将突破万亿,产业正迎来黄金发展期。
然而,在这片蓝海市场中,技术发展却并不均衡。具身智能分为负责决策的大脑部分和负责运动执行的小脑两个部分,目前国内虽然具身智能热度高涨,但多数企业仅聚焦于小脑的研究。在大脑层面,技术发展较为滞后,大多停留在对多模态基座模型的直接调用阶段,市场亟需一个面向机器人行业的产品级“具身大脑”解决方案。
而清华千诀科技团队在七年前就选择对标美国具身大脑初创公司Physical Intelligence的核心成员Sergey Levine的技术研究路线,并坚持至今。Physical Intelligence近期估值已飙升至20亿美元。机器人大讲堂认为,千诀科技作为中国首家专注于具身智能大脑研发的企业,其技术路线已获得市场验证,在这一领域具备显著的发展潜力和投资价值。
更多细节欢迎查阅原论文。
论文:
Yizhou Jiang, Feng Chen, et al. “Spatio-Temporal Approximation: A Training-Free SNN Conversion for Transformers”,ICLR 2024
(文:机器人大讲堂)