

你永远可以相信通义千问,就在今天(春节前最后一天),正式开源Qwen2.5-VL系列模型,让LLM更清晰的看世界!!!
2025年的第一个月,国内大模型厂商太争气了,前有minimax、kimi、deepseek,后有qwen,春节放假期间真是不给我们一点休息时间呀。
不过,我个人真的是乐在其中,难道这就是所谓的幸福的烦恼?
HF: https://huggingface.co/collections/Qwen/qwen25-vl-6795ffac22b334a837c0f9a5
Qwen2.5-VL模型
下面说回模型本身。
开源的Qwen2.5-VL模型共包含3个尺寸,3B(更易端侧部署)、7B(速度与效果的平衡)以及72B(效果最强)。
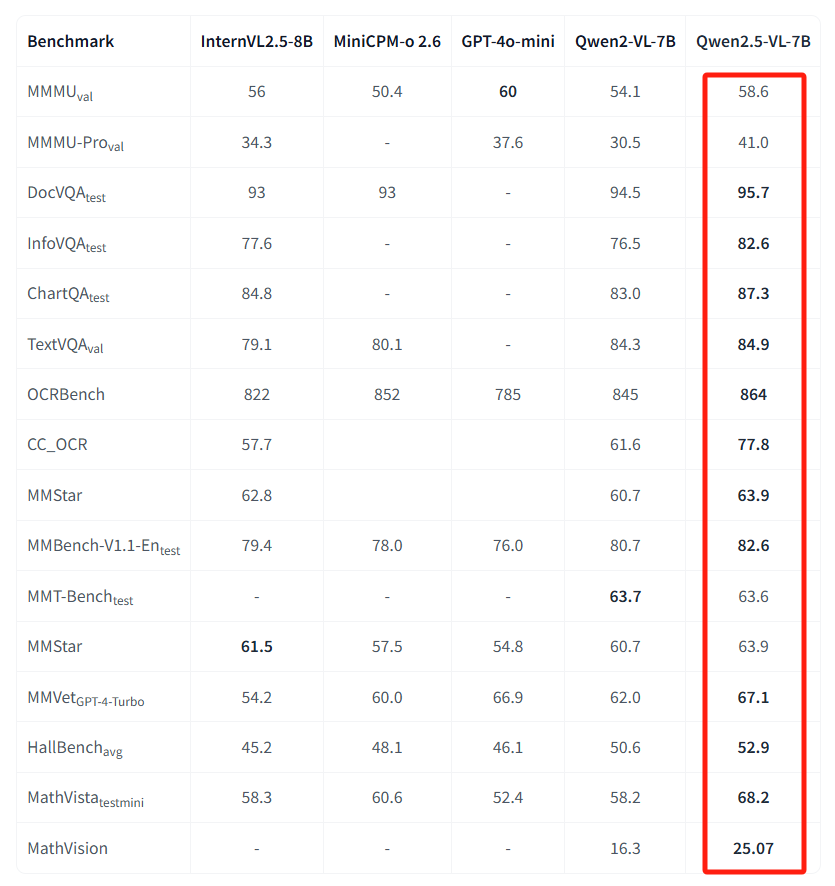
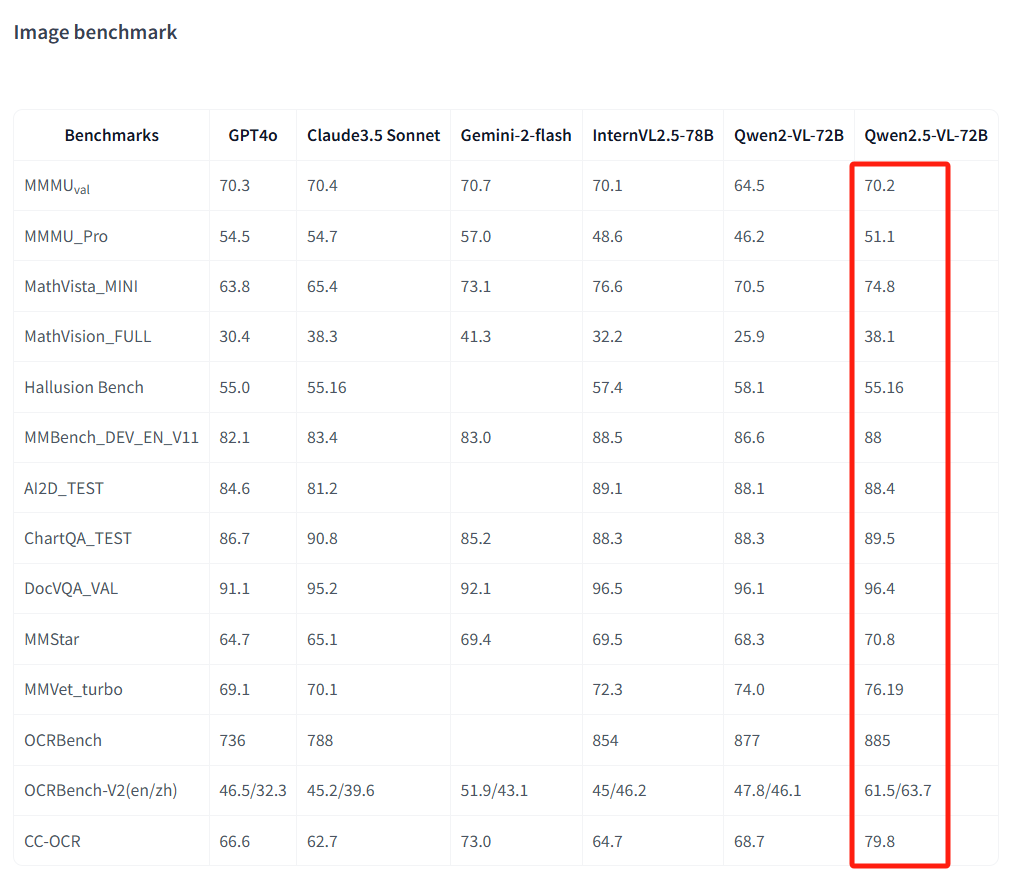
在7B基本的模型在多个榜单上都达到了开源Top1,并且72B跟GPT4-o、Claude3.5都有一拼。
Qwen2.5-VL-7B
Qwen2.5-VL-72B
Qwen2.5-VL模型不仅在对话、指令跟随、数学、代码等能力上有所提高,还支持坐标、json等返回格式、支持更长(1小时)的视频理解、更细粒度的时间感知、更全面的知识解析能力、具备更强的agent能力来操作手机和电脑。
来自官方-QQ发祝福
Agent和实时视频交互能力,看了官方几个视频,感觉处理相关任务效果还不错,具体等模型下完之后,体验再评价。
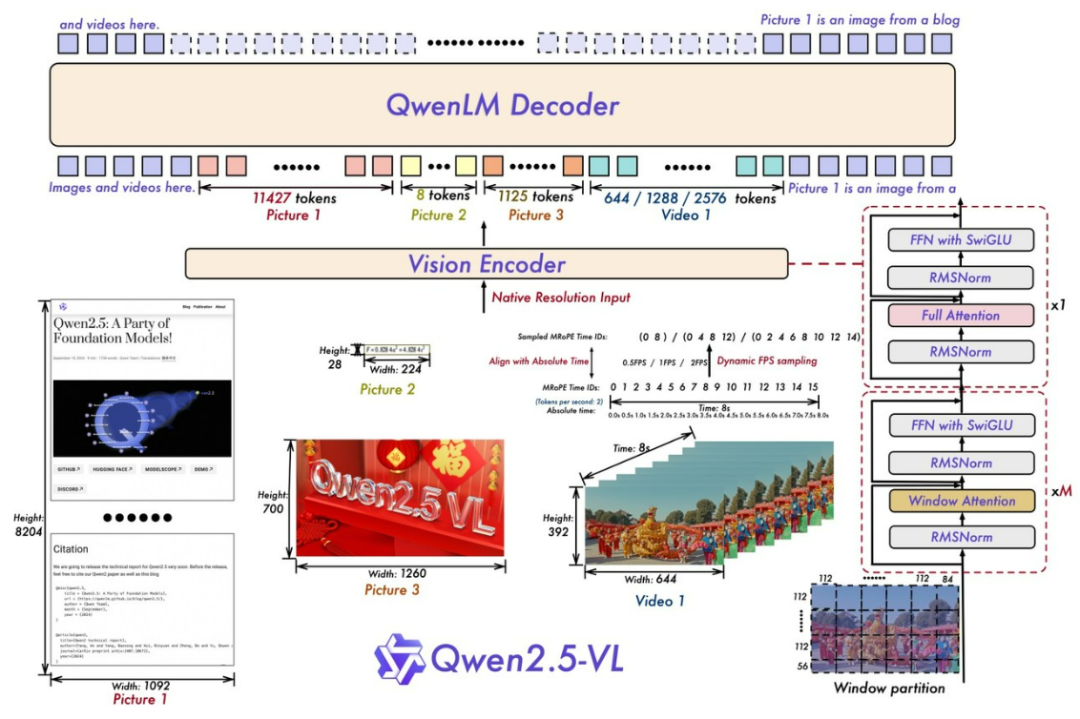
Qwen2.5-VL模型,在视觉编码器部分是原生训练的支持动态分辨率的ViT。同时在空间维度引入大量检测框和点等坐标,让模型理解空间的尺寸;
在时间维度引入动态FPS和绝对时间编码,使mRoPE的ids与时间快慢进行对齐,让模型理解时间的流速。
实测
由于模型还在下载,实测源自官方链接:https://chat.qwenlm.ai/
之前大家都应该知道我写了一篇大模型无法做表格识别的东西,因为Qwen2.5-VL特意提到加强结构化内容输出,先来测测表格解析效果。
测试样例来自多模态大模型在表格解析任务上效果如何?亲身经历全是泪!
-
简单表格:
解析结果完全正确,比较简单表格。
-
中等表格:
这个比上一个有一些难度,主要是字多了一点,然后合并单元的不错有交错(6、7行的2、4列),之前的多模态大模型们全军覆没,Qwen2.5-VL-72B模型依然完全正确。

-
复杂表格:
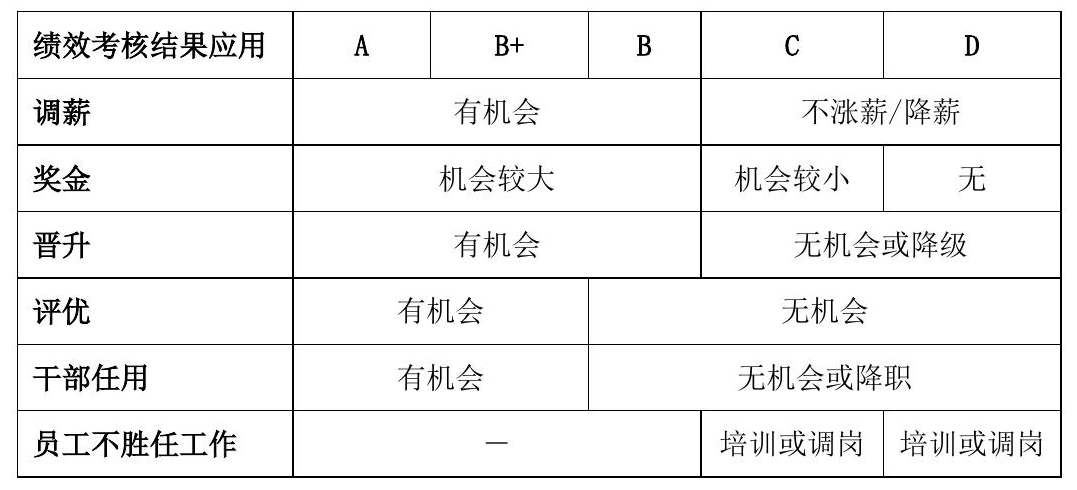
这个更难了,之前依旧全军覆没,但Qwen2.5-VL-72B模型依然完全正确。
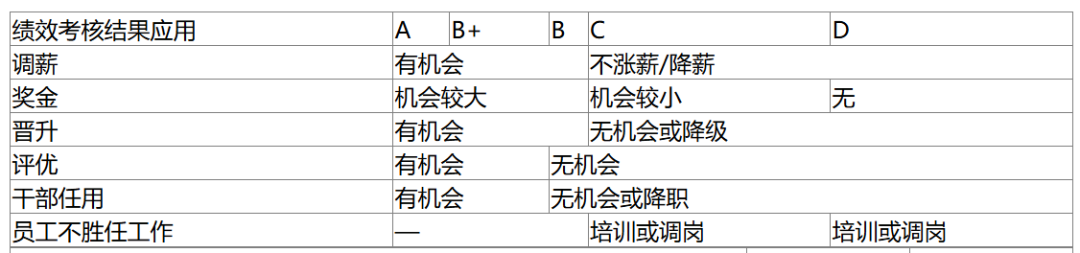
Qwen2.5-VL的表格解析太牛了,之前GPT4-o和Claude、Gemini都没对的,他竟然全对!!!
下面看看Qwen2.5-VL的数学能力,
-
2024年年高考全国甲卷数学(文)试题
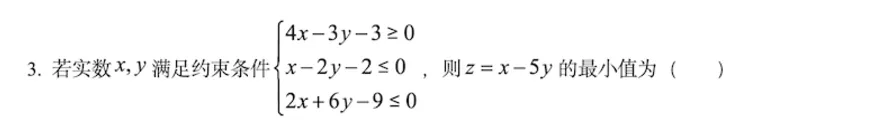

-
2024年高考全国甲卷数学(理)试题


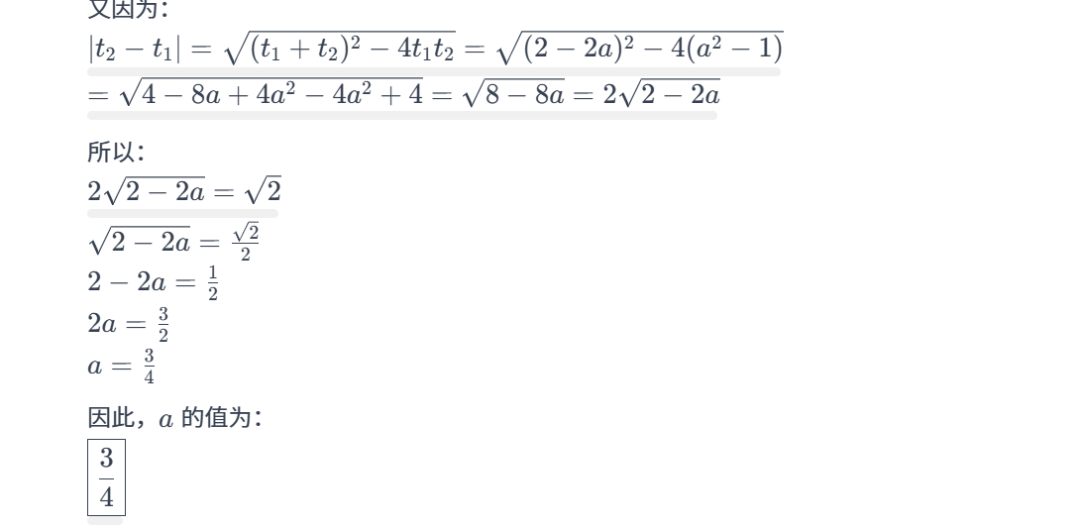
-
测试一下单图片信息抽取+计算功能

-
测试一下单图片理解功能

-
测试一下单图片手写ORC功能
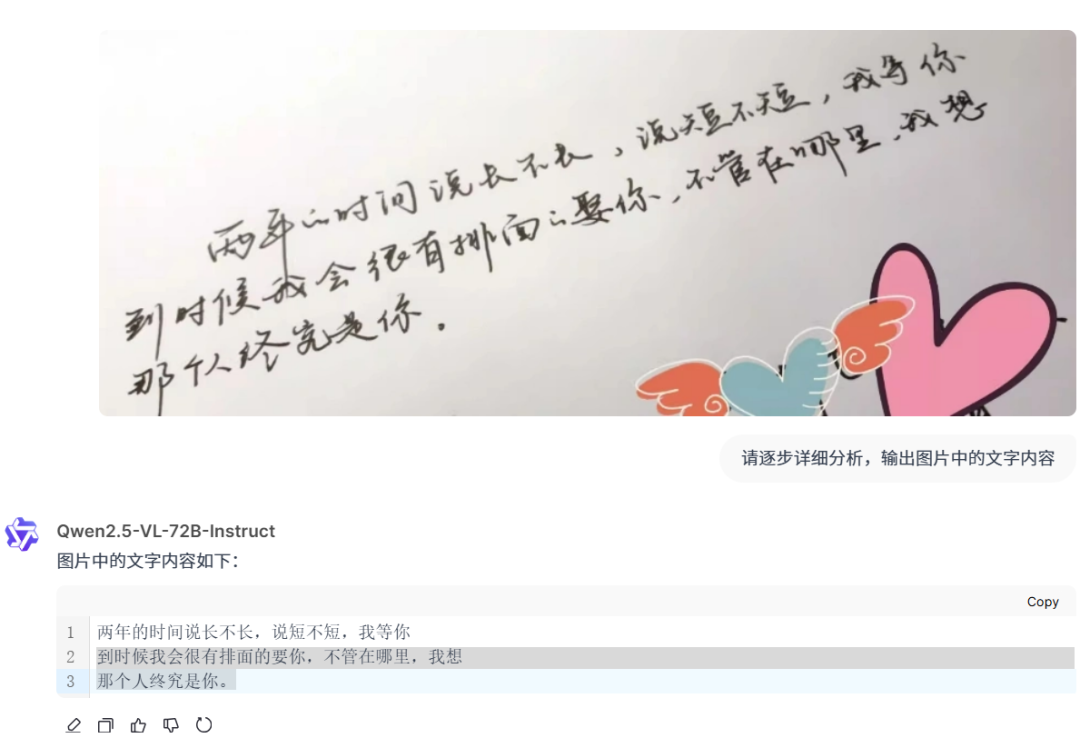
-
再测试一下多图片信息抽取+计算功能





HF快速使用
pip install git+https://github.com/huggingface/transformer acceleratefrom transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
写在最后
(文:机器学习算法与自然语言处理)