

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文标题:PolaFormer: Polarity-aware Linear Attention for Vision Transformers -
论文链接:https://arxiv.org/pdf/2501.15061 -
GitHub 链接:https://github.com/ZacharyMeng/PolaFormer -
Huggingface 权重链接:https://huggingface.co/ZachMeng/PolaFormer/tree/main
-
负值丢失。依赖非负特征映射(如 ReLU)的线性注意力模型无法保持与原始 q,k 点积的一致性。这些特征映射仅保留了正 – 正交互作用,而关键的正 – 负和负 – 负交互作用则完全丢失。这种选择性表示限制了模型捕获全面关系范围的能力,导致注意力图的表达能力减弱和判别力降低。 -
注意力分布高信息熵。没有 softmax 的指数缩放,线性注意力会导致权重分布更加均匀且熵更低。这种均匀性削弱了模型区分强弱 q,k 对的能力,损害了其对重要特征的关注,并在需要精细细节的任务中降低了性能。
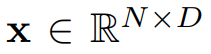 。该序列被分成 h 个头,每个头的维度是 d。在每个头中,不同位置的标记(token)共同被关注以捕获长距离依赖关系。输出可表示为
。该序列被分成 h 个头,每个头的维度是 d。在每个头中,不同位置的标记(token)共同被关注以捕获长距离依赖关系。输出可表示为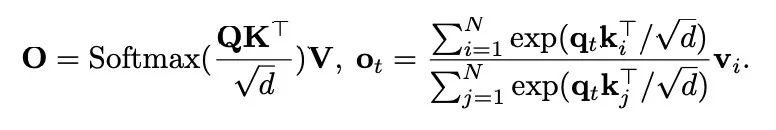
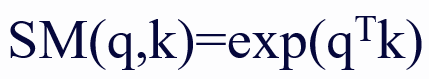 作为 softmax 核函数。从数学上讲,线性注意力的目标是使用 ϕ(q_i)ϕ(k_j)^T 来近似 SM (⋅,⋅),则注意力输出的第 t 行可以重写为:
作为 softmax 核函数。从数学上讲,线性注意力的目标是使用 ϕ(q_i)ϕ(k_j)^T 来近似 SM (⋅,⋅),则注意力输出的第 t 行可以重写为: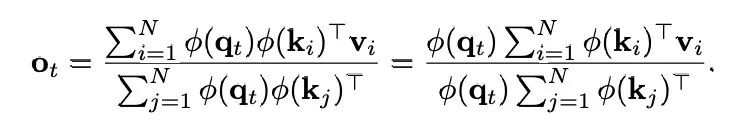
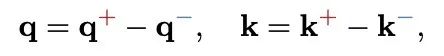
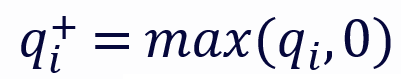 和
和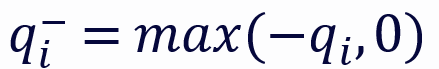 分别代表 q 的正部和负部,同理对于 k。
分别代表 q 的正部和负部,同理对于 k。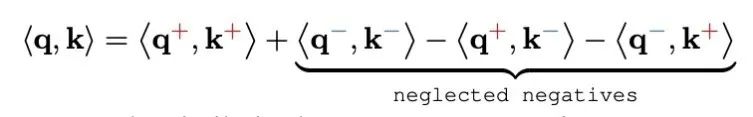
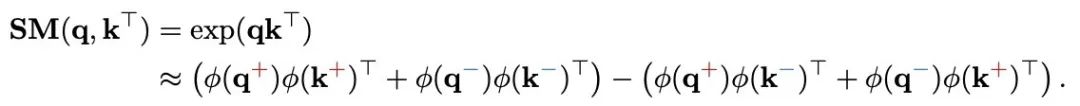

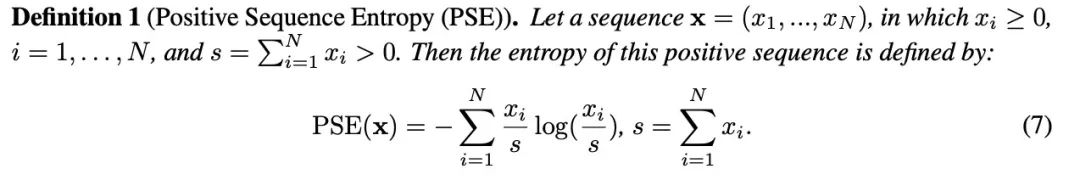

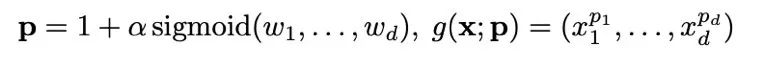
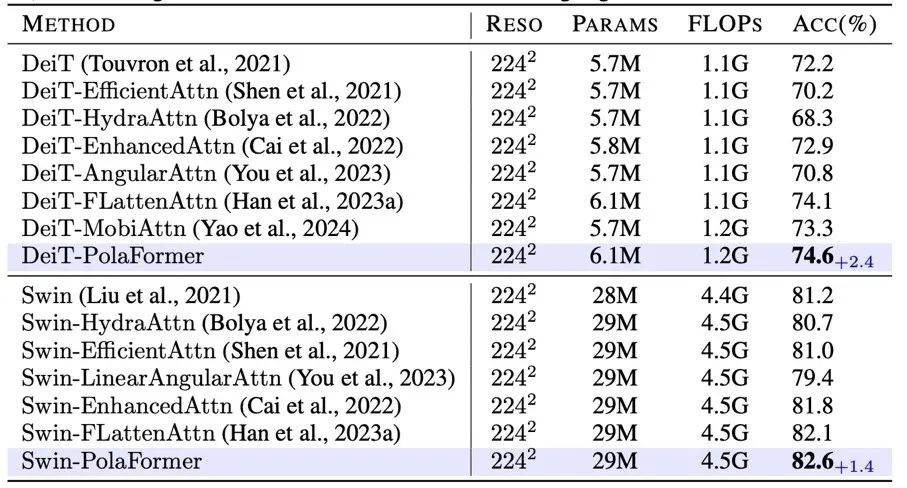
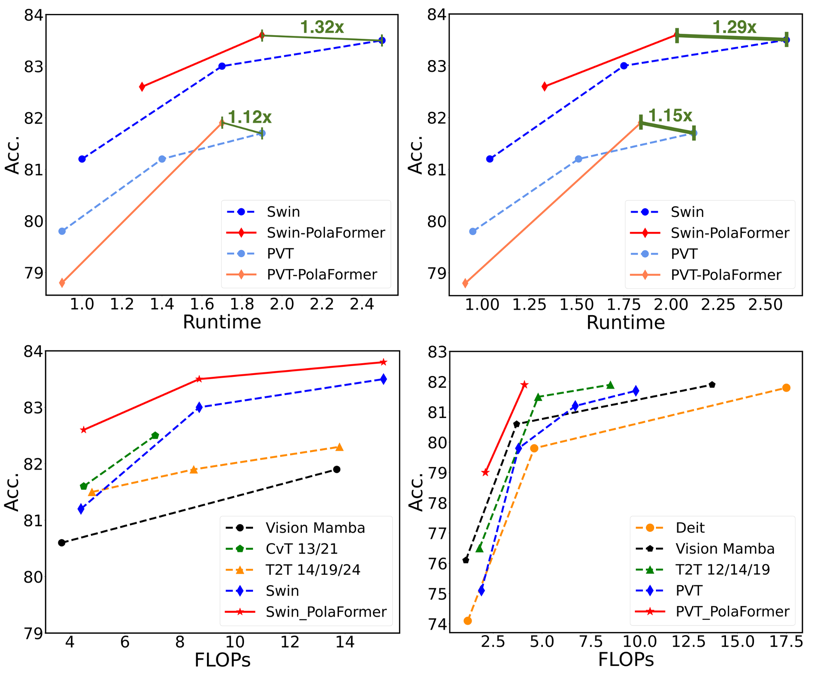
-
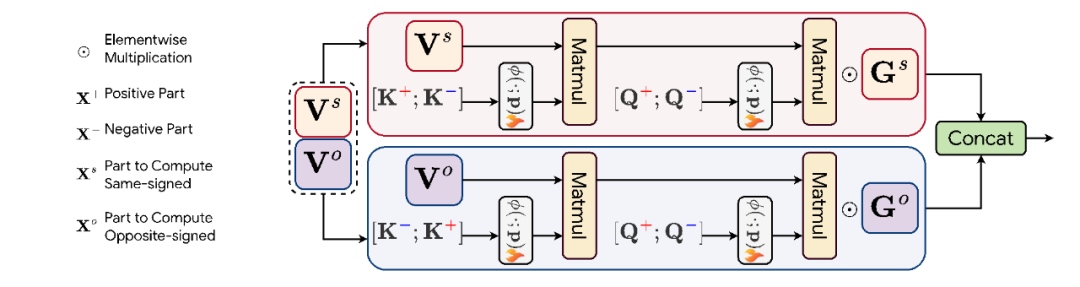
本文指出现有方法负值忽略的问题,提出了极性感值的映射函数,让每个元素都参与到注意力的计算;
-
在理论上,作者提出并证明了存在一族逐元素函数能够降低熵,并采用了可学习的幂函数以实现简洁性和重新缩放。
-
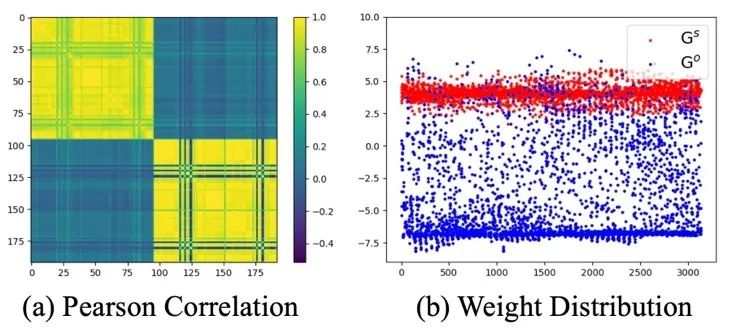
此外,作者还使用了卷积来缓解由自注意力矩阵的低秩特性引起的退化解问题,并引入了极性感知系数矩阵来学习同号值和异号值之间的互补关系。
©
(文:机器之心)