

今早八点,OpenAI 发布了他们的新产品 Deep Research
在第一时间用上后,做出了此篇评测,先说结论:极强,但非常不稳定
Deep Research 是一个比较高级的 Agent,在 ChatGPT 里的。
当你给到 Deep Research 一个任务后,比如「DeepSeek 是如何崛起的」,会自动检索&分析大量的网络信息,并给你带来一份相当不错的报告。
需要注意的是:完成任务可能会花费 10 分钟,甚至更久。
值得玩味的是,这个功能的背后是 o3 模型,不过这个模型不是原版,针对联网和数据分析相关的需求进行了微调,这使得它能更好的搜索、分析文本、图片和pdf,并能不断的反思和重试。
接下来我会展示一些我的测试案例。在那之前,让我们先看一下官方的演示视频:
我个人猜测,这个功能可能是升级于最开始的 WebGPT 那套。同时这次发布,的确很有价值:
-
o1 带来了深度思考
-
R1 则是先简单搜索,再在深度思考
-
Deep Research 可以配合 o3-mini 使用,让 AI 先深度搜索,再深度思考
如此深度,如此求索…
让我们把这个功能,叫做深度求索吧!英文就是 DeepSeek。
正如 OpenAI 一贯的「高级功能有限制」,DeepSeek DeepResearch 功能也是限量使用:
-
Pro 用户:今日可用,每个月限 100 次
-
Plus/ Team/Enterprise:即将可用,每个月限制 10 次
-
免费用户:再等等吧…
当然,这些限制或许以后都会改。
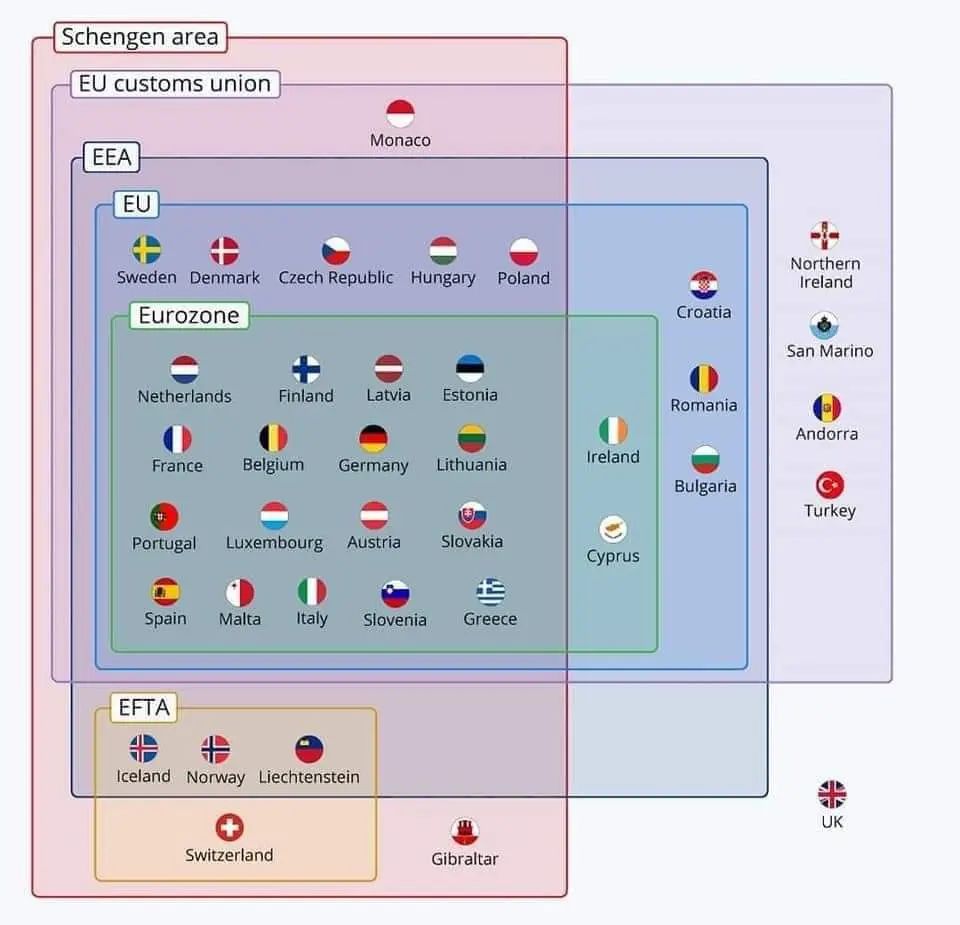
当然,这一功能也是分地区开放的,按官方说法,以下地区暂不可用:英国、瑞士和欧洲经济区(欧盟+冰岛、挪威和列支敦士登)
顺道着… 网上找了个分类图:EU 是欧盟,EEA 是欧洲经济区
回过头来,让我们看看 Deep Research 的实测,这应该是全网第一份的。
例子1,给出任务目标让他执行,典型的 Good Case:
生成一份翔实的商业传记,来讲述 DeepSeek 是如何崛起的:从创立之初到如今爆火,都发生了那些事儿。
这里我做了份录屏(10倍速)
然后得到了这么一份报告:

可上下滑动
仔细了看了这篇报告…质量堪称极高。
当然,里面也有一些小的错误,比如:他认为“幻方量化”是 2010 年成立的,而实际上是在 2015年。但总体瑕不掩瑜。
之前我自己也花两天时间,写了这个:《DeepSeek 成长史:追光者的技术远征 | 江湖录》,看官们也可以比较下,是哪个版本的更好。
例子2,给定目标并限定方法,这是一个典型的 Bad Case:
我告诉 Deep Research:「我是公众号「赛博禅心」的主理人,下方是1月份公众号「赛博禅心」的内容数据,请在逐篇阅读后,给我一些内容优化上的建议」
然后附带上了下面这个信息:
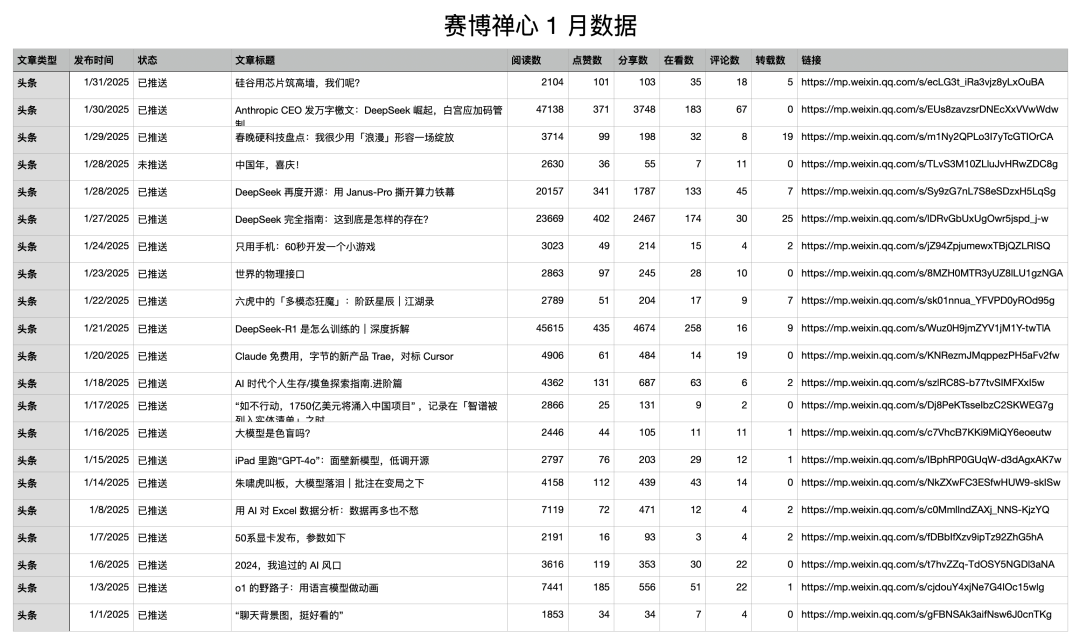
迎接我的,是一篇胡说八道:

我啥时候有百万阅读了…于是我回顾了一下他的流程,发现它并没有跟随我的指令去直接访问链接,而是去搜索。

之后我又反覆试了几次,即便要求「一定访问我的链接,一定不要搜索」,他也并不理会。这里并不清楚为什么他一定会去搜索,但从实际经验的角度,大概率是从安全角度出发,从系统层面禁止了「用户指定页面的行为」

例子3:…容我先卖个关子,这个很有趣,我放到了最后
官方对 Deep Research,也发布了相关的参数报告:
https://openai.com/index/introducing-deep-research/
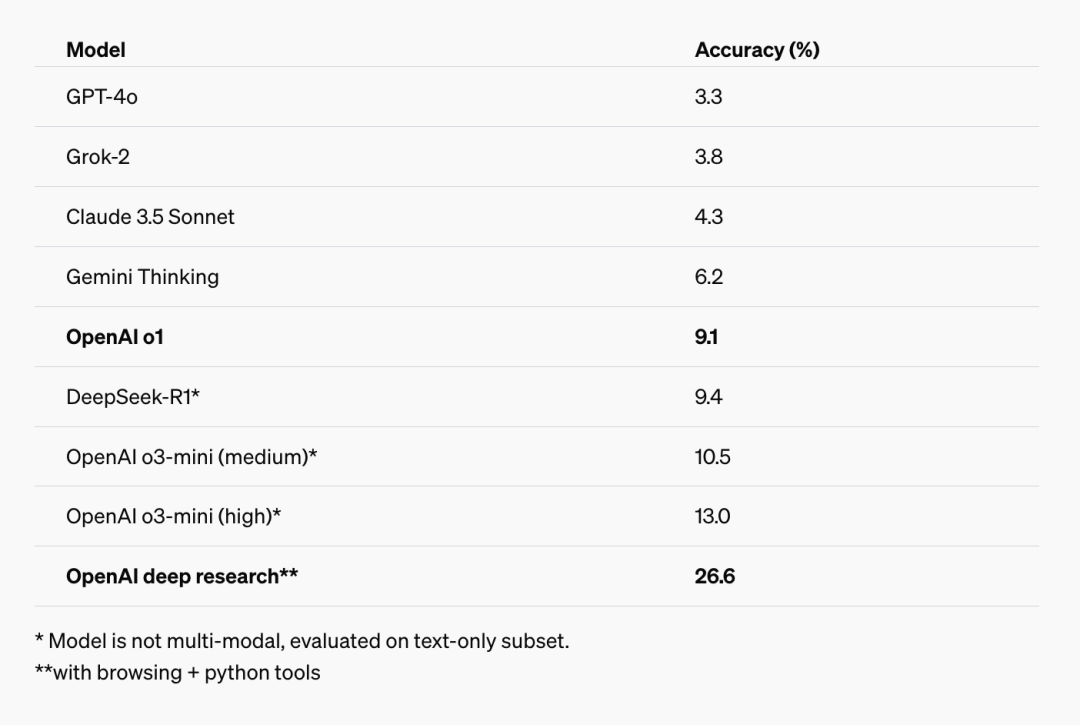
在这个报告中,除了 OpenAI 自己的“遥遥领先”,我认为其中提到的两个测试,更为有趣:
-
Humanity’s Last Exam, HLE
-
General AI Assistants, GAIA
接下来,我会结合这两个测试,以及 OpenAI 的报告内容,整体的分析下 Deep Research 这个东西。
首先是 Humanity’s Last Exam:这个测试包含 3000 道问题,由全球各学科专家共同开发,包含适合自动评分的多项选择题和简答题。每个问题都有明确且容易验证的已知解,但无法通过互联网检索快速找到答案。
这里,我放两个测试的样题,看看你能不能回答出来(PS:我是废物,完全不行):


而就在这个 HLE 测试中,Deep Research 取得了 26.6% 的准确率,一骑绝尘。
如果你对这个测试感兴趣,可以在这里查阅到更多信息:
https://lastexam.ai/
对应的 paper 在这里:
https://arxiv.org/abs/2501.14249
另一个基准测试是 GAIA,用来评估 Agent 的性能,由 450 个具有明确答案的题目组成。问题被分为 3 个等级,即 Level 1~3,其中 Level 1 是较为基础的问题,Level 3 则颇具挑战。
这是一个 Level 1 级别的问题,看看你搞定需要多久:
![]()
而这是 Level 3 级别的问题:

但无论如何,解开这些题目,都需要 AI 去使用多种工具,包括联网搜索来完成。如果你对这个测试感兴趣,可以在这里查看方法:
https://openreview.net/forum?id=fibxvahvs3
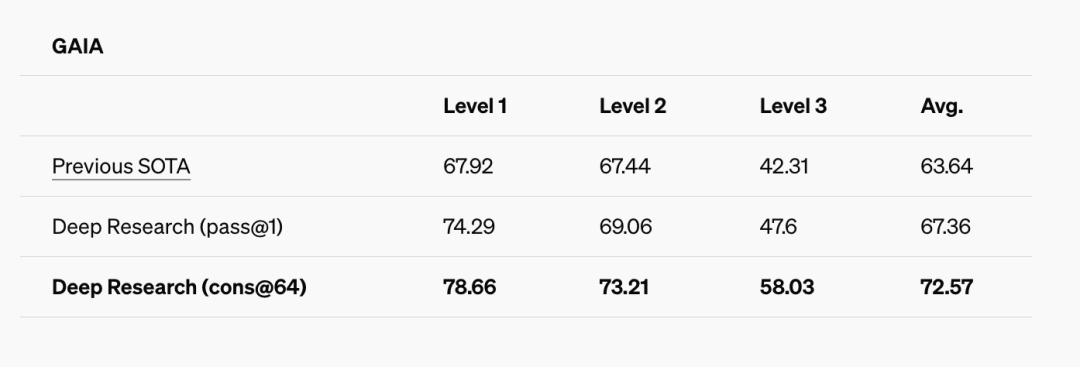
在这个测试中,会发现 Open Research 取得了较为不错的成绩,在 pass@1 和 cons@64 的标准下,均取得了比以往更好的成绩。这里做一个信息的补充,有关 pass@1 以及 cons@64:
-
pass@1:AI 在首次尝试时直接给出正确答案的概率,可以用来衡量一个 AI 是否直接可用
-
cons@64:这是 AI 在 生成 64 个答案后,正确答案出现在这 64 个答案中的概率,可以用来评估 AI 的覆盖率和潜力
不过嘛…我还是发现了一个华点。这个 GAIA Leaderboard 访问地址在 Hugging Face 上。这里:
https://huggingface.co/spaces/gaia-benchmark/leaderboard
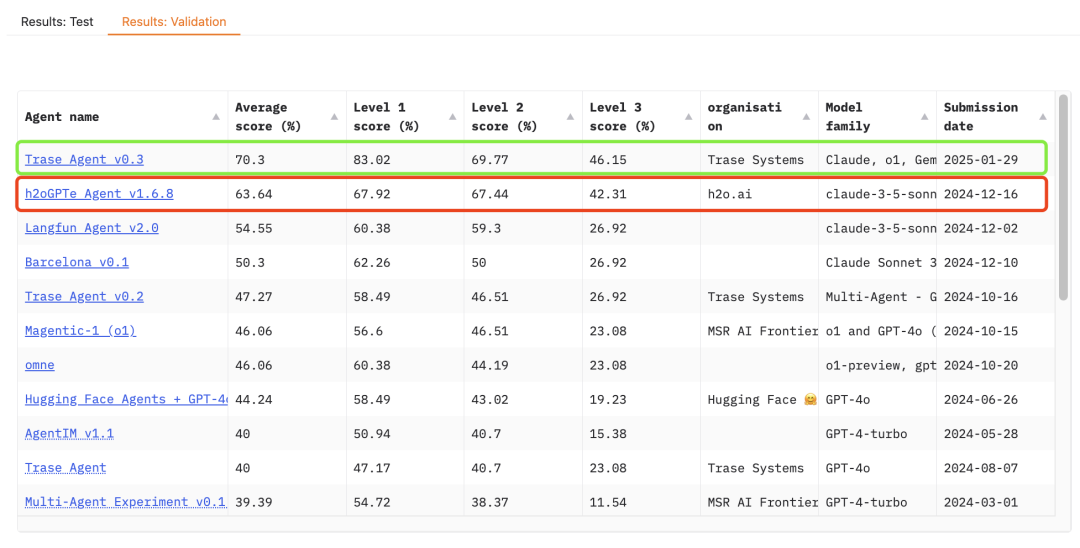
可以发现,OpenAI 发布的“以往最佳”的成绩,是 h2o 做到的,记录时间为 24年12月16日。而更新的记录则是由 Trase Systems 于 1月29日(大年初一) 发布的。也就是说,OpenAI 应该在 1月29号之前就 Ready 了这个项目。哈哈~刚好和奥特曼的 Twitter 对应上了:
对于「例子3」,ahhhhhh,我希望 用 Deep Research 来「写一篇有关 OpenAI Deep Research 的报告,你的目标受众是 AI 从业者、投资人和相关研究人员」
5分钟后,获得了这么一份报告:

可上下滑动
大家可以来评一评这篇报告:
-
觉得写得好,请在评论区,夸我是个大聪明;
-
觉得写得烂,请在评论区,骂 OpenAI 是个大聪明
实际上,这是 Deep Research 的第 4 次输出:在前三次中,它的输出堪称「胡说八道,离题万里」:

而在第四次中,我重新修改了提示词,加上了一些背景介绍,并且重复测试了2次,才获得较为满意的结果。这是我在第四次中,用到的提示词:「就在刚刚,OpenAI 新出了一个功能,叫做「Deep Research」,那么请你就「OpenAI Deep Research」写一篇分析报告,你的目标受众是 AI 从业者、投资人和相关研究人员」
通过上面的几个例子,发现这次 OpenAI 的发布确实可圈可点,上限很高。但在实际的体验中,也蕴藏着一些问题,包括不仅限于:
-
非常不稳定
-
如果任务没有被描述的非常清楚,它的理解&执行可能会有比较大的偏差,就比如 OpenAI Deep Research 报告(你并无机会在中途修正)
-
任务一旦开始,就无法人工干预(包括提前结束)
-
无法读取用户提供的链接(至少不读取公众号链接)
-
限额过于低:即便是 Pro 用户,每个月也只有 100 次的额度
-
…
对于限额问题,官方也说到:“All paid users will soon get significantly higher rate limits when we release a faster, more cost-effective version of deep research powered by a smaller model that still provides high quality results.”
翻译成中文,便是:“很快,我们会推出一款更省算力的小模型,给 Deep Research 来用,那时,所有的付费用户都可以有更多的使用额度了。”
一时不知是喜是忧。
既然:
OpenAI 已经发布了 Deep Research
那么:
DeepSeek 何时发布 Open Research
如果您喜欢本内容,可点击下方推荐,让更多朋友看到
一键三连,这次一定!
(文:赛博禅心)