

作者|子川
来源|AI先锋官
这意味着Hibiki不仅能够在服务器端高效处理大量翻译请求,还能够轻松部署到移动设备上,为用户提供随时随地的实时翻译服务。
除了表现优异外,其纸面成绩也相当抗打,
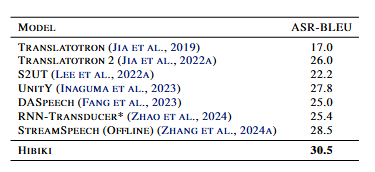
据介绍,在ASR-BLEU指标上,Hibiki取得了30.5分的优异成绩,超越了多个离线基准模型。
同时在人类评分员的评估中,Hibiki生成的语音质量得分高达4.12(满分5分),接近真实人类译员的水平。
在长篇内容的翻译任务中,Hibiki的平均延迟仅比Seamless高出1.4秒,但是翻译的质量要更好。
Hibiki之所以能够取得如此优异的成绩,离不开背后一系列创新技术的支持。
多流语言模型架构
Hibiki采用了独特的多流语言模型架构,可以同时处理两种语言的语音。它通过Transformer把源语言和目标语言的语音流一起处理,并且还能同时生成文字和语音。
这样,Hibiki就能实时接收源语音并立刻生成翻译后的语音,从而实现翻译效果更好。
弱监督学习与上下文对齐
为了应对实时翻译中对齐数据稀缺的挑战,Hibiki引入了一种弱监督学习方法。通过利用现成的文本翻译系统的困惑度,Hibiki能够识别出每个单词的最佳延迟,并创建对齐的合成数据。
这种方法不仅解决了数据对齐问题,还使得Hibiki能够在没有复杂推理策略的情况下,适应性地进行实时翻译。
语音合成与说话者相似性
Hibiki在语音合成方面也很厉害。它用了一种改进的TTS(语音合成)技术,生成的语音不仅自然流畅,还能保留说话者的声音特点。
此外,Hibiki还采用了条件训练和分类器自由引导技术,让翻译后的语音更接近源语言说话者的声音。
随着全球化的加速和跨文化交流的日益频繁,翻译愈发成为生活中的必需品,当有这么一款同声传译的语音模型,语言或许将不再阻扰我们看世界。
(文:AI先锋官)