
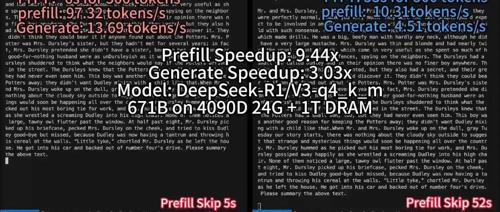
清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:支持24G显存在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。

参考文献:
[1] GitHub 地址:https://github.com/kvcache-ai/ktransformers
[2] 具体技术细节指路:https://zhuanlan.zhihu.com/p/714877271
[3] https://github.com/kvcache-ai/ktransformers/discussions
(文:NLP工程化)