

今天是2025年02月15日,星期 六,北京,天气晴。
我们继续来看昨日大模型地一些有趣进展,围绕GraphRAG、openai推理模型使用实践建议、大模型训练注意力机制以及Deepseek推理建议等,供各位参考。
第二个事,我们来看下深度思考与RAG结合进展,做嵌入Embedding,让llm生成嵌入的同时,也输出thought,很想Hyde的做法。
专题化,体系化,会有更多深度思考。大家一起加油。
一、昨日大模型地一些有趣进展
继续给大家看下昨日的进展,有许多有趣的事情。来自老刘说NLP技术社区,欢迎关注。

【老刘说NLP20250214大模型进展早报】
1、GraphRAG进展PIKE-RAG
PIKE-RAG:sPecIalized KnowledgE and Rationale Augmented Generation
,https://arxiv.org/pdf/2501.11551,https://github.com/microsoft/PIKE-RAG,
通过提取、理解和应用领域特定知识,同时构建连贯的推理逻辑,以逐步引导LLM获得响应。几个基本模块组成,包括文档解析、知识抽取、知识存储、知识检索、知识组织、以知识为中心的推理以及任务分解与协调。
2、关于推理模型使用实践建议
OpenAI官方博客刚发了篇推理类模型的最佳实践,指导如何更好的使用o1、o3这类推理模型,当然也可以应用在deepseekr1上,https://platform.openai.com/docs/guides/reasoning-best-practices。
例如,现在如何将GPT模型跟O1推理模型进行结合,最大化收益。

又如,怎么有效地使用推理模型。

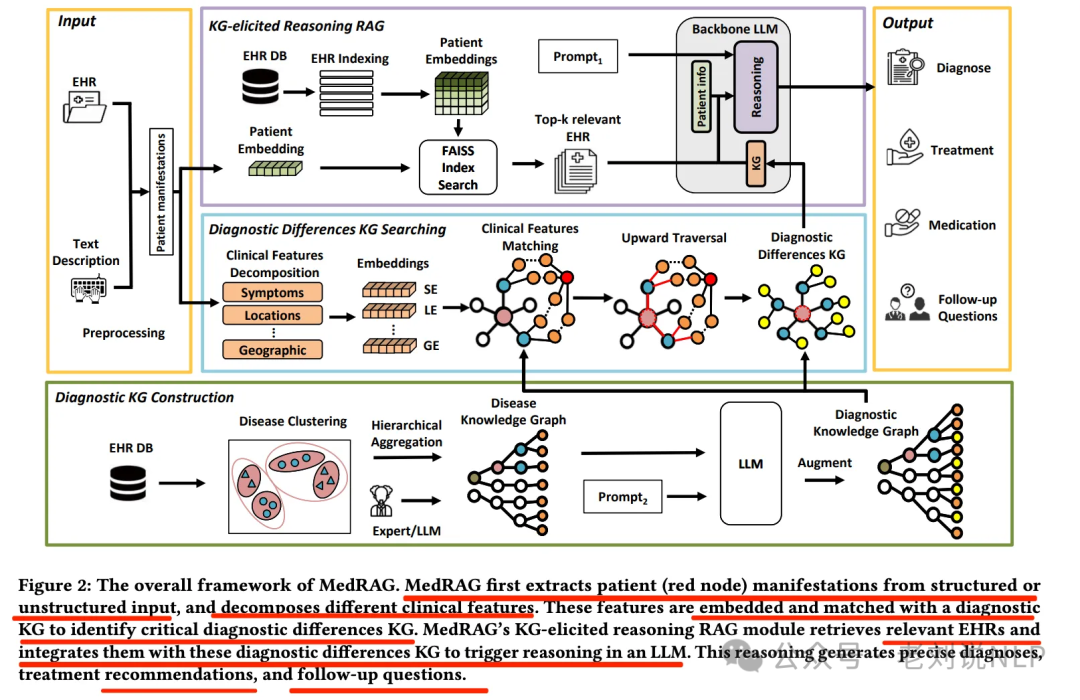
3、GraphRAG进展MedRAG
GraphRAG前沿之MedRAG医疗问答路线:兼看基于KG进行上下文扩展方案。https://mp.weixin.qq.com/s/wNzv1Va221tj8zMBqHqGeA
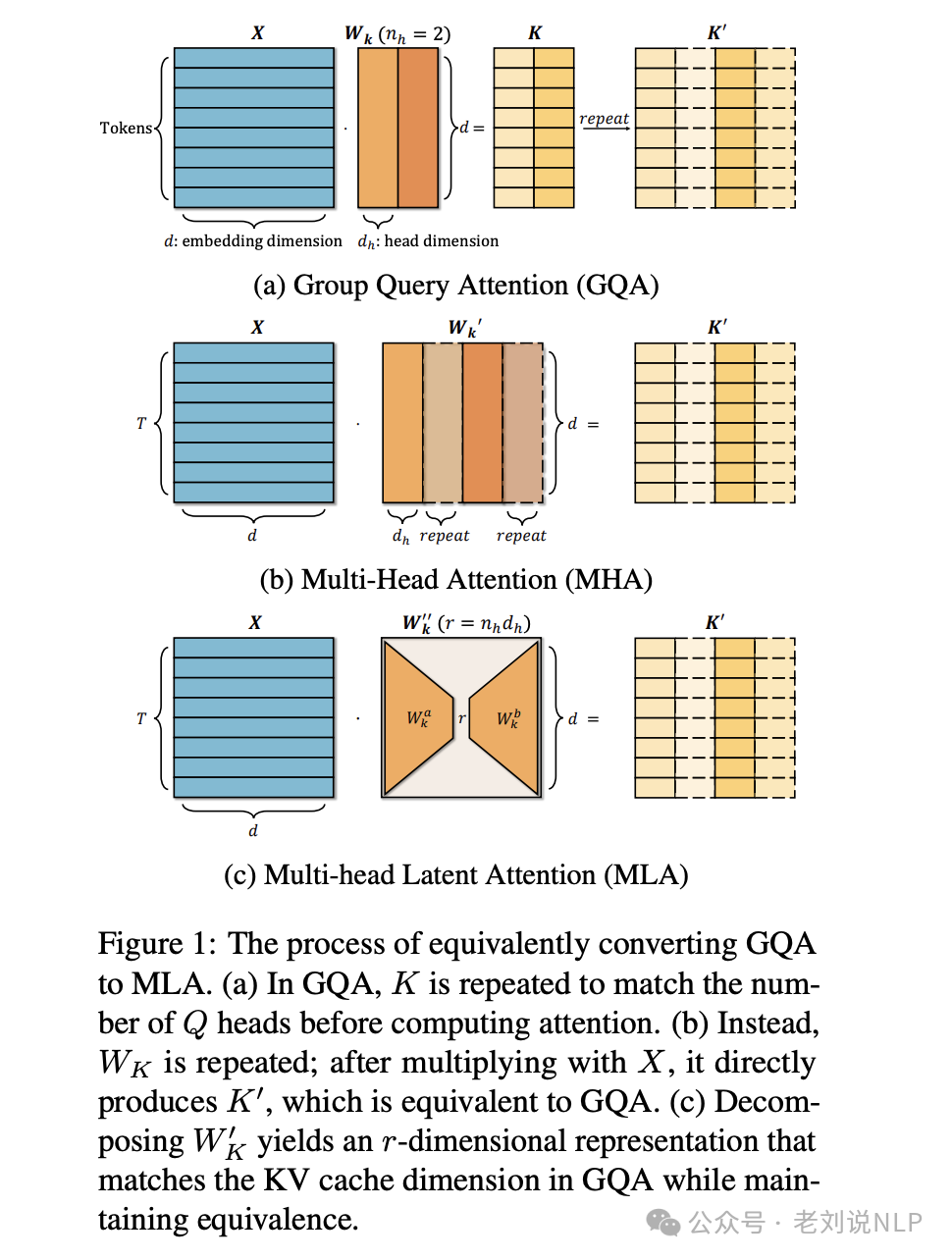
4、关于大模型训练注意力机制进展
《TransMLA:Multi-head Latent Attention Is All You Need》,提出了多头潜注意力(MLA)机制,理论证明并实验验证了MLA在相同KV缓存开销下比GQA具有更强的表达能力,并提出了TransMLA方法将GQA模型转换为高性能的MLA模型,为解决LLM的KV缓存瓶颈问题提供了新思路。https://arxiv.org/pdf/2502.07864,https://github.com/fxmeng/TransMLA
5、Deepresearch开源复现进展,SciraAI发布完全开源的Deepresearch搜索
叫Extreme模式,会自行制定研究计划、搜索内容、深度,最后提供实时进度更新和详细响应。有人测试,让其搜索Deepseek的信息并分析R1模型对行业影响的结果,其研究了16步,结果只能说跟GeminiThinking调用搜索的结果差不多,没办法达到Deepresearch的质量:https://github.com/zaidmukaddam/scira

6、关于推理时扩展提升大模型推理能力的工作
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling,
,https://arxiv.org/pdf/2502.06703,https://ryanliu112.github.io/compute-optimal-tts,通过实证分析展示了计算最优的TTS策略,也就是推理时测试扩展,内部TTS通过训练模型“慢速思考”来提高推理能力,而外部TTS则通过采样或搜索方法来改进推理性能。
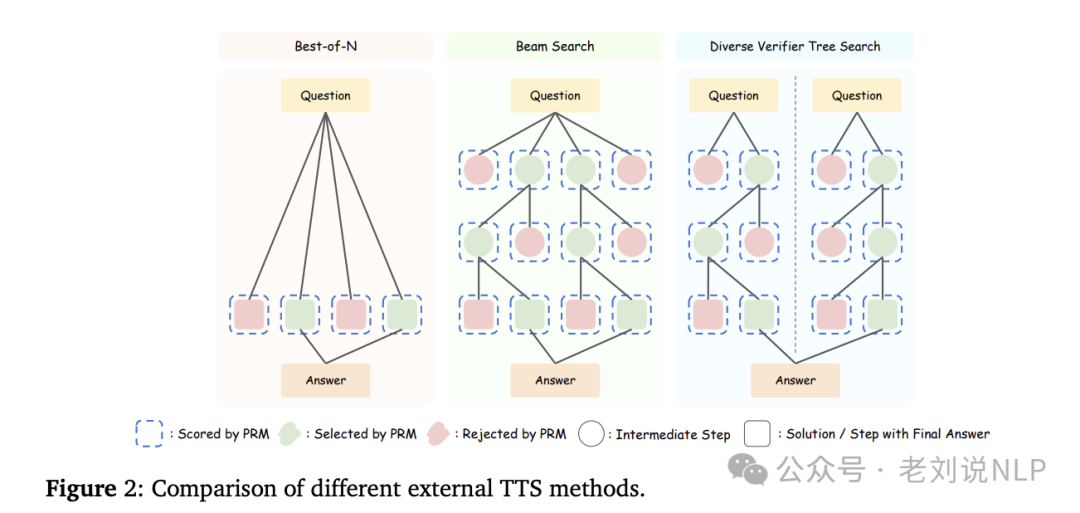
使用PRM-Min、PRM-Last、PRM-Avg等评分方法和MajorityVote、PRM-Max、PRM-Vote等投票方法。在不同策略模型、PRMs和复杂任务中的有效性。实验方面,采用Best-of-N(BoN)、束搜索和多样化验证树搜索(DVTS)3种方法通过不同的方式在推理过程中分配计算资源。
而为了最大化TTS的性能,采用计算最优的TTS策略,利用奖励机制,选择与特定测试时策略相对应的超参数,以最大化特定提示上的性能收益。这个的核心就是奖励策略的设定。
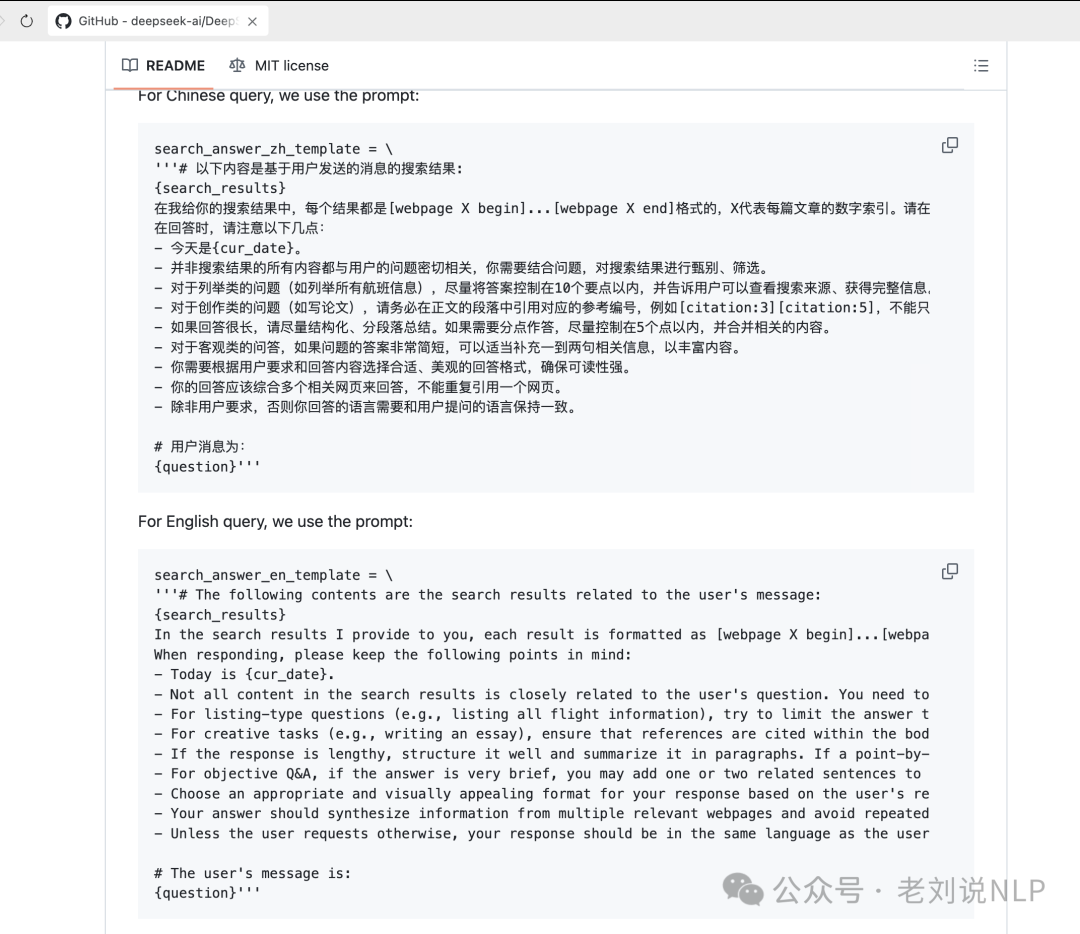
7、Deepseek推理建议、参数设定以及联网搜索prompt开源。详细见DeepSeek的官方github:https://github.com/deepseek-ai/DeepSeek-R1
如使用建议如下:

又如联网搜索的prompt:
二、深度思考与RAG结合进展,做嵌入Embedding
继续来看深度思考与RAG结合进展,做嵌入Embedding。
可以看一个工作《O1 Embedder: Let Retrievers Think Before Action》,https://arxiv.org/pdf/2502.07555,也是很蹭。这个O1 Embedder生成关于输入查询的thought,然后和question一起拼接,然后分别独自生成嵌入,然后池化聚合。也就是说,这个Embedding模型比之前的模型多了个thought的输出。
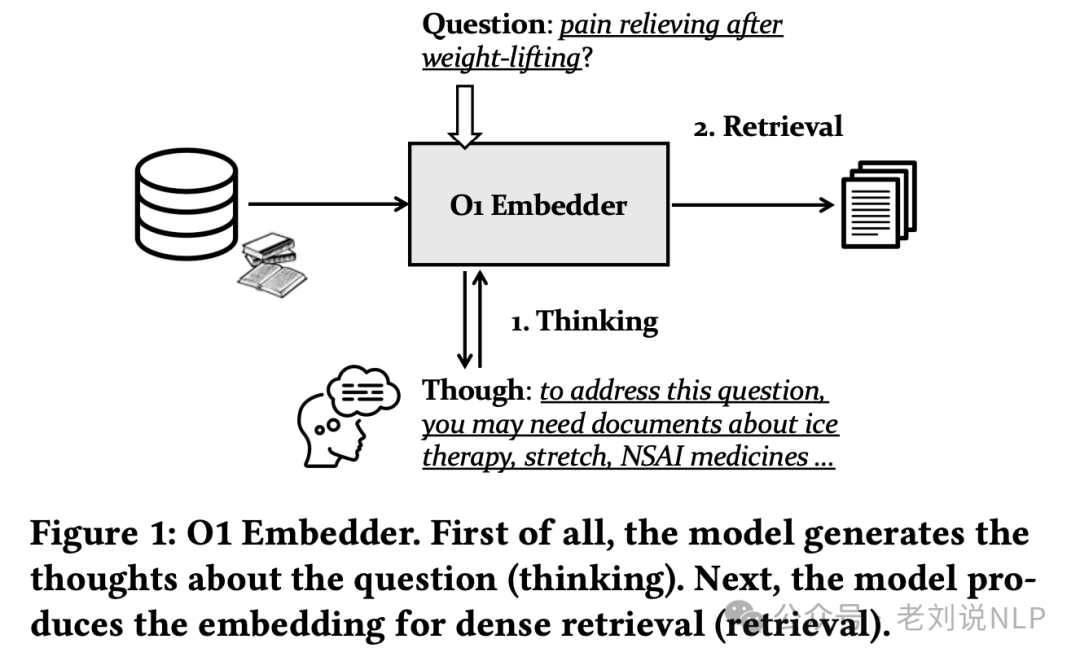
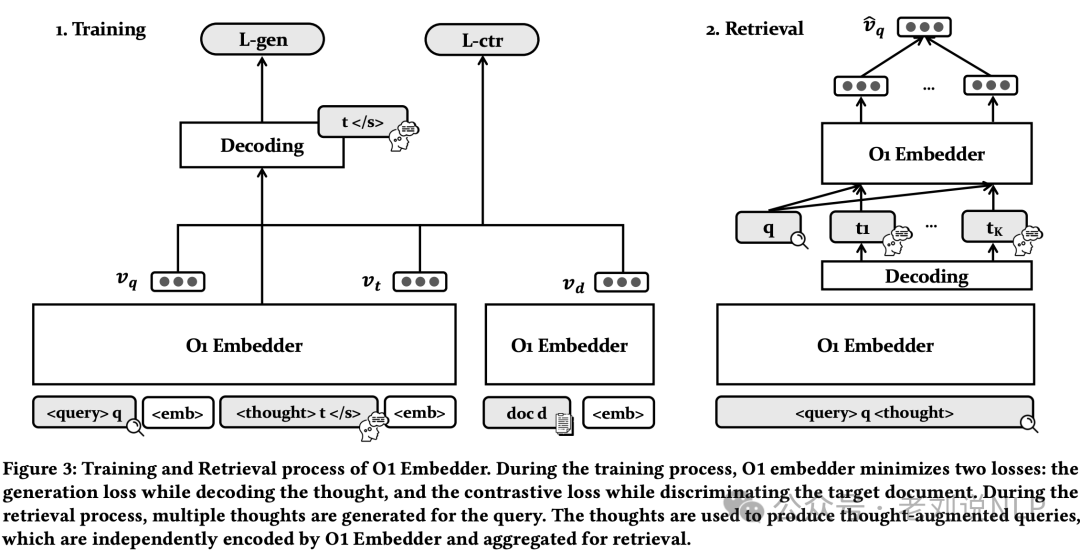
怎么具备这种能力那就去微调,两个并行任务,一个是thought生成,一个是对比学习。
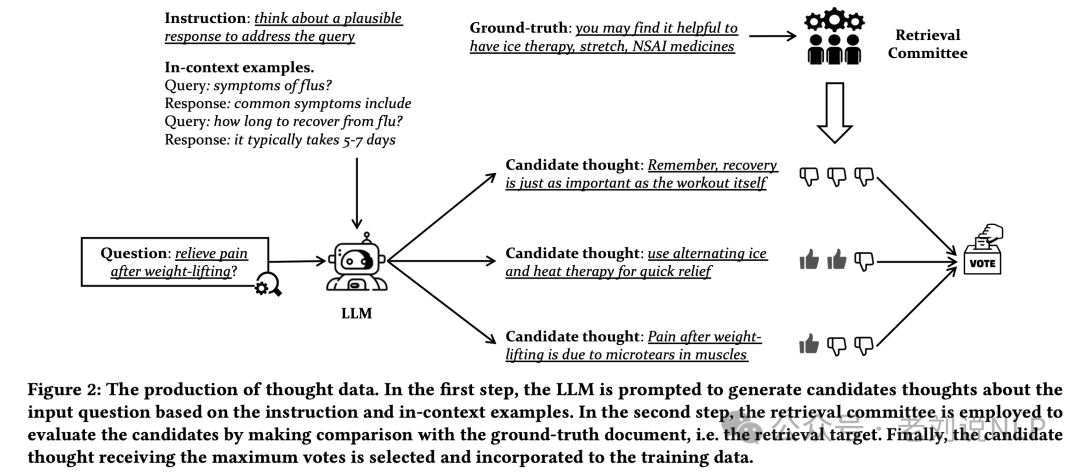
微调数据怎么来,那就是生成后进行打分评价。首先,使用LLM生成初始思想,然后使用检索评分器来根据初始思想和目标文档之间的相关性评分,最终通过多数投票选择最佳thought。
在多个数据集上,在MS MARCO、DL’19和DL’20数据集上,O1 Embedder在所有评价指标上均优于其他模型包括BM25、ANCE、TAS-B、coCondenser、SimLM、RepLLaMA和Promptiever。在MS MARCO(dev)、TREC DL19、TREC DL20以及BEIR等外部数据集上,O1 Embedder平均提高了2.3%,显示出泛化能力。
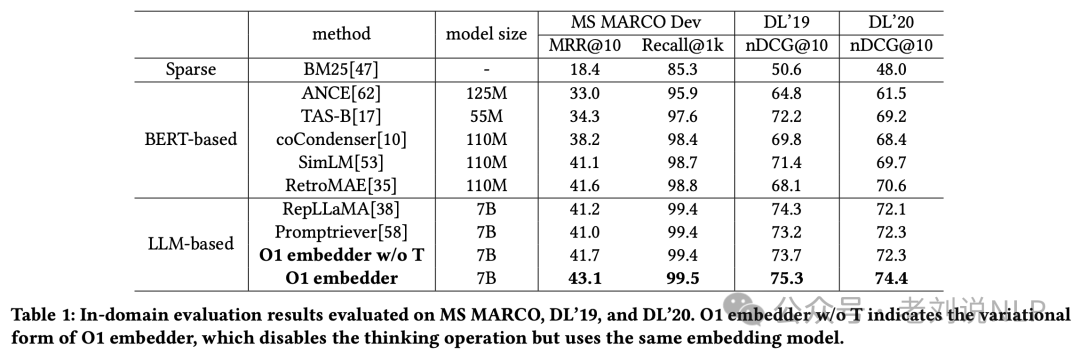
特别是在涉及复杂推理的任务中,如HotPotQA和CosQA,O1 Embedder表现出色。思考机制在某些开放QA数据集上带来了显著的改进,例如NQ数据集提高了3.9%,HotPotQA提高了3.0%。
总结
本文主要回顾了昨日的进展,大家的关注度还是在推理模型上,在探究其所适合做的场景,而与之而来的,其实还是推理的一些架构也出来了,如KTransformer。
在论文侧,也在往think+llm的路线上靠。
大家可以多关注,多思考。
参考文献
1、https://arxiv.org/pdf/2502.07223
(文:老刘说NLP)