

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文标题:Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models -
论文链接:https://openreview.net/forum?id=p3NKpom1VL -
开源代码:https://github.com/PKU-ICST-MIPL/Finedefics_ICLR2025 -
模型地址:https://huggingface.co/StevenHH2000/Finedefics -
实验室网址:https://www.wict.pku.edu.cn/mipl


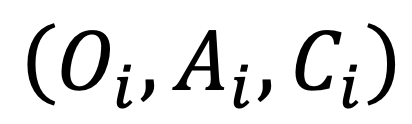 ,利用视觉编码器
,利用视觉编码器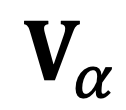 与可学习的模态连接层
与可学习的模态连接层  将
将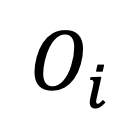 转化为对象表征序列
转化为对象表征序列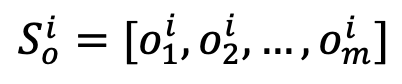 。
。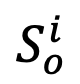 拼接,得到新构建的对象表征序列
拼接,得到新构建的对象表征序列 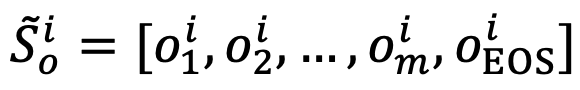 。相似地,得到属性表征序列
。相似地,得到属性表征序列 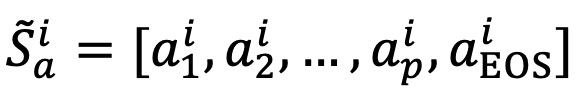 与类别表征序列
与类别表征序列 。
。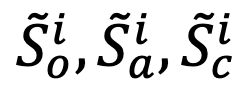 输入到大语言模型中,将序列末尾的预测标志(token)
输入到大语言模型中,将序列末尾的预测标志(token)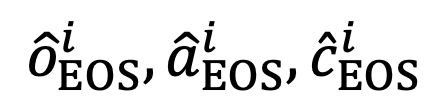 分别作为
分别作为 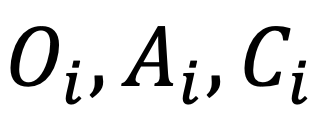 的全局表示。
的全局表示。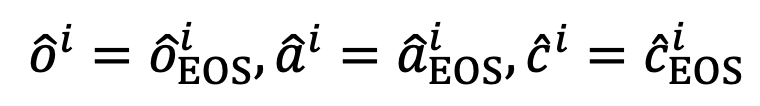 训练采用的对比学习损失包含以下 3 种:
训练采用的对比学习损失包含以下 3 种: 挖掘困难负样本。具体地,针对每张样本图像,从三个最相似但错误的细粒度子类别数据中选择负样本,并将其属性描述与细粒度子类别名称作为困难负样本加入对比学习。
挖掘困难负样本。具体地,针对每张样本图像,从三个最相似但错误的细粒度子类别数据中选择负样本,并将其属性描述与细粒度子类别名称作为困难负样本加入对比学习。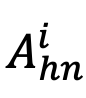 表示对象困难负样本的属性表征集合,Sim (⋅,⋅) 测量特征空间的余弦相似度。
表示对象困难负样本的属性表征集合,Sim (⋅,⋅) 测量特征空间的余弦相似度。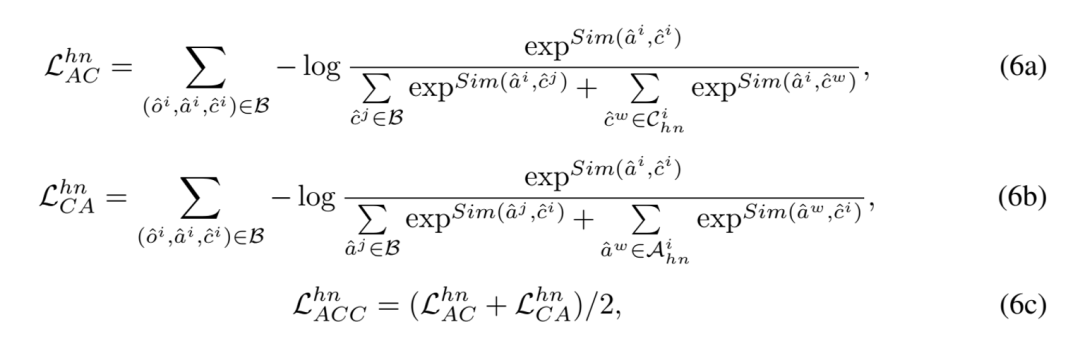
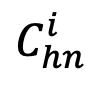 表示对象 困难负样本的细粒度子类别表征集合。
表示对象 困难负样本的细粒度子类别表征集合。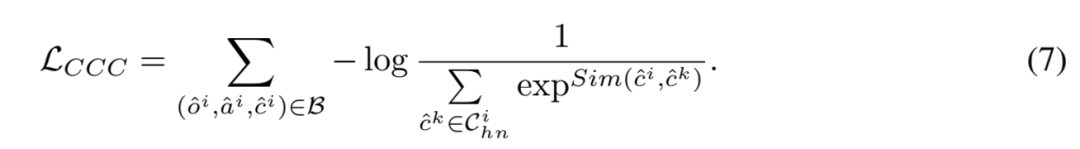
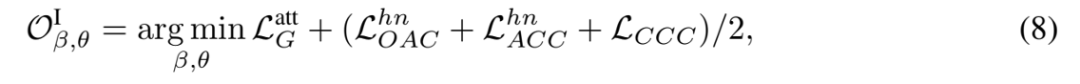
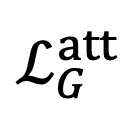 表示属性描述生成损失。
表示属性描述生成损失。
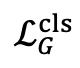 表示以识别为中心的指令微调损失。
表示以识别为中心的指令微调损失。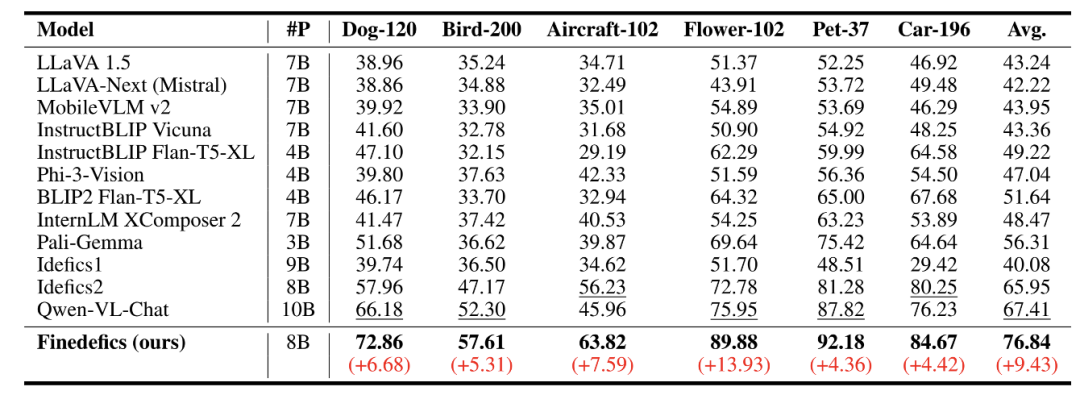 表 1. 细粒度多模态大模型(Finedefics)实验结果
表 1. 细粒度多模态大模型(Finedefics)实验结果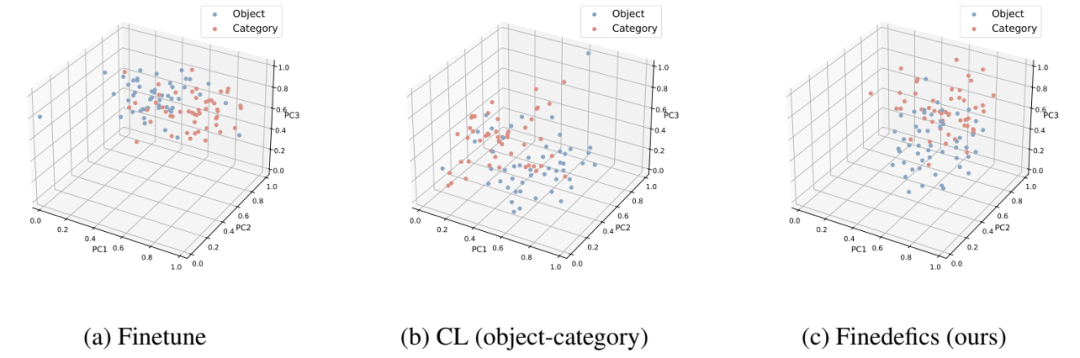

图 4 的案例展示表明,相较于 Idefics2,本方法 Finedefics 能成功捕捉视觉对象特征的细微区别,并将其与相似的细粒度子类别对象显著区分。
(文:机器之心)