
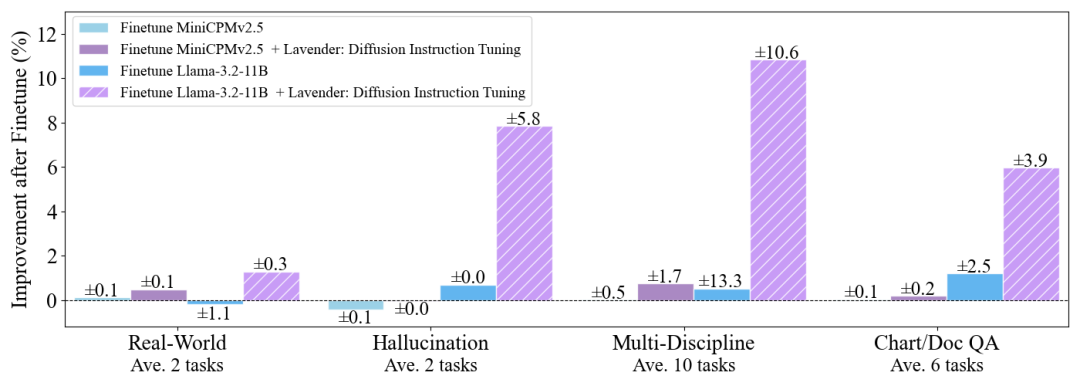
中国研究员联合DeepMind团队的最新研究《Lavender: Diffusion Instruction Tuning》,通过简单的”注意力对齐”,仅需1天训练、2.5%常规数据量,即可让Llama-3.2等模型在多模态问答任务中性能飙升30%,甚至能防”偏科”(分布外医学任务提升68%)。且代码、模型、训练数据将全部开源。
-
训练数据:由Stable Diffusion标注的高质量对齐样本;
-
预训练模型:基于Llama-3.2、MiniCPMv2.5等架构的Lavender适配版;
-
调参指南:从小白到进阶的”注意力对齐”实操手册;

参考文献:
[1] 论文:https://arxiv.org/abs/2502.06814
[2] 项目主页:https://astrazeneca.github.io/vlm/
(文:NLP工程化)