AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Ola 是腾讯混元 Research、清华大学智能视觉实验室(i-Vision Group)和南洋理工大学 S-Lab 的合作项目。本文的共同第一作者为清华大学自动化系博士生刘祖炎和南洋理工大学博士生董宇昊,本文的通讯作者为腾讯高级研究员饶永铭和清华大学自动化系鲁继文教授。
GPT-4o 的问世引发了研究者们对实现全模态模型的浓厚兴趣。尽管目前已经出现了一些开源替代方案,但在性能方面,它们与专门的单模态模型相比仍存在明显差距。在本文中,我们提出了 Ola 模型,这是一款全模态语言模型,与同类的专门模型相比,它在图像、视频和音频理解等多个方面都展现出了颇具竞争力的性能。
Ola 的核心设计在于其渐进式模态对齐策略,该策略逐步扩展语言模型所支持的模态。我们的训练流程从差异最为显著的模态开始:图像和文本,随后借助连接语言与音频知识的语音数据,以及连接所有模态的视频数据,逐步拓展模型的技能集。这种渐进式学习流程还使我们能够将跨模态对齐数据维持在相对较小的规模,从而让基于现有视觉 – 语言模型开发全模态模型变得更为轻松且成本更低。
-
项目地址:https://ola-omni.github.io/
-
论文:https://arxiv.org/abs/2502.04328
-
代码:https://github.com/Ola-Omni/Ola
-
模型:https://huggingface.co/THUdyh/Ola-7b
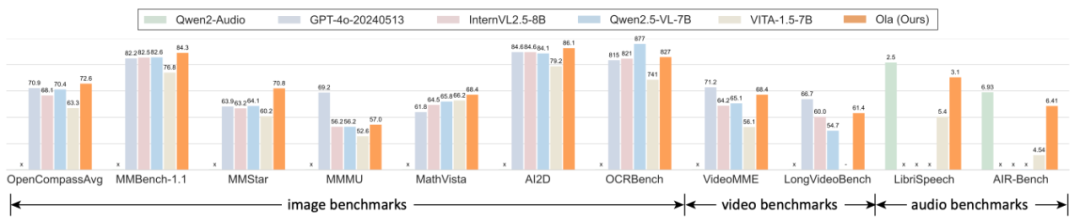
Ola 模型大幅度推动了全模态模型在图像、视频和音频理解评测基准中的能力上限。我们在涵盖图像、视频和音频等方面的完整全模态基准测试下,Ola 作为一个仅含有 7B 参数的全模态模型,实现了对主流专有模型的超越。
图 1:Ola 全模态模型超越 Qwen2.5-VL、InternVL2.5 等主流多模态模型。
在图像基准测试方面,在极具挑战性的 OpenCompass 基准测试中,其在 MMBench-1.1、MMMU 等 8 个数据集上的总体平均准确率达到 72.6%,在市面上所有 30B 参数以内的模型中排名第 1,超越了 GPT-4o、InternVL2.5、Qwen2.5-VL 等主流模型。在综合视频理解测试 VideoMME 中,Ola 在输入视频和音频的情况下,取得了 68.4% 的准确率,超越了 LLaVA-Video、VideoLLaMA3 等知名的视频多模态模型。另一方面,Ola 在诸如语音识别和聊天评估等音频理解任务方面也表现卓越,达到了接近最好音频理解模型的水平。
完整的测试结果表明,与现有的全模态大语言模型(如 VITA-1.5、IXC2.5-OmniLive 等)相比,Ola 有巨大的性能提升,甚至超越了最先进的专有多模态模型的性能,包括最新发布的 Qwen2.5-VL、InternVL2.5 等。目前,模型、代码、训练数据已经开源,我们旨在将 Ola 打造成为一个完全开源的全模态理解解决方案,以推动这一新兴领域的未来研究。
训练全模态大模型的核心挑战在于对于多种分布的模态进行建模,并设计有效的训练流程,从而在所有支持的任务上实现有竞争力且均衡的性能。然而,在以往的研究中,高性能与广泛的模态覆盖往往难以兼顾,现有的开源全模态解决方案与最先进的专用大语言模型之间仍存在较大的性能差距,这给全模态概念在现实世界的应用带来了严重障碍。
在本文中,我们提出了 Ola 模型,探索如何训练出性能可与最先进的专用多模态模型相媲美、具备实时交互能力且在对齐数据上高效的全模态大语言模型。Ola 模型的核心设计是渐进式模态对齐策略。为在语言与视觉之间建立联系,我们从图像和文本这两种基础且相互独立的模态入手,为全模态模型构建基础知识。随后,我们逐步扩充训练集,赋予模型更广泛的能力,包括通过视频帧强化视觉理解能力,借助语音数据连通语言与音频知识,以及利用包含音频的视频全面融合来自语言、视频和音频的信息。这种渐进式学习策略将复杂的训练过程分解为小步骤,使全模态学习变得更容易,从而保持较小规模的跨模态对齐数据,也更容易基于视觉 – 语言模型的现有成果展开研究。
为配合训练策略,我们在架构和数据领域也进行了重要改进。
-
Ola 架构支持全模态输入以及流式文本和语音生成,其架构设计可扩展且简洁。我们为视觉和音频设计了联合对齐模块,通过局部 – 全局注意力池化层融合视觉输入,并实现视觉、音频和文本标记的自由组合。此外,我们集成了逐句流式解码模块以实现高质量语音合成。
-
除了在视觉和音频方面收集的微调数据外,我们深入挖掘视频与其对应音频之间的关系,以构建视觉与音频模态之间的桥梁。具体而言,我们从学术及开放式网络资源收集原始视频,设计独立的清理流程,然后利用视觉 – 语言模型根据字幕和视频内容生成问答对。
全模态输入编码:基于先前文本到单模态大语言模型的成功实践,我们分别对视觉、音频和文本输入进行编码。对于视觉输入,我们使用任意分辨率视觉编码器 OryxViT 进行编码,保留每个图像或帧的原始宽高比;对于音频输入,我们提出双编码器方法,使用 Whisper-v3 作为语音编码器,BEATs 作为音乐编码器;对于文本输入,我们直接使用预训练大语言模型中的嵌入层来处理文本标记。
视觉与音频联合对齐:对齐模块充当从特定模态空间到文本嵌入空间的转换器,这是全模态大语言模型的关键部分。为了提高效率并减少视觉特征的标记长度,我们进一步提出了 “局部 – 全局注意力池化” 层,以在减少信息损失的情况下获得更好的下采样特征。具体而言,我们采用双线性插值进行 2 倍下采样以获得全局特征,将原始特征和全局特征结合用于局部 – 全局嵌入,并使用 Softmax 预测每个下采样空间区域的重要性,此后通过哈达玛积确定每个先前区域的权重。
我们参照先前的工作,应用两层非线性 MLP 将特定模态特征投影到语言空间中。
流式语音生成:我们采用 CosyVoice 作为高质量的语音解码器进行语音生成。为支持用户友好的流式解码,我们实时检测生成的文本标记,一旦遇到标点符号就截断句子。随后,将前一个句子输入语音解码器进行音频合成。因此,Ola 无需等待整个句子完成即可支持流式解码。
语言、视觉与音频之间的模态差距:通过探索,我们认识到全模态训练中的两个关键问题。
-
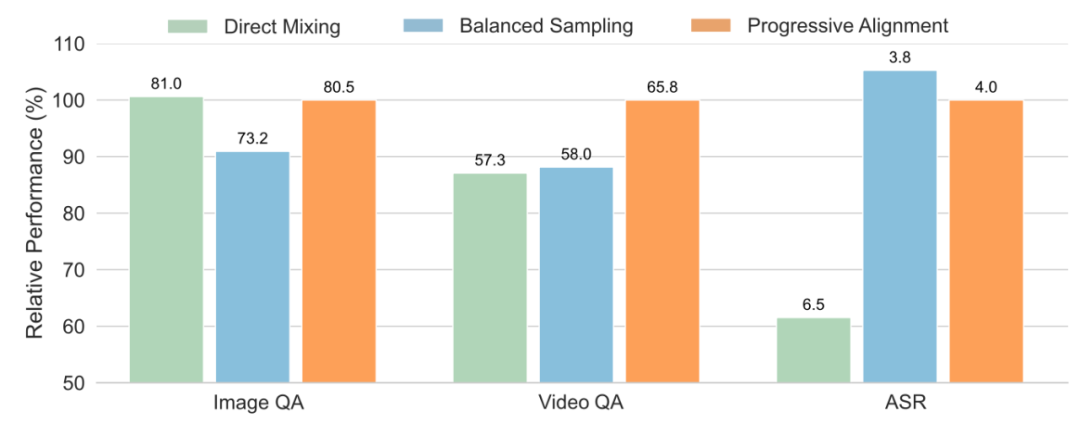
模态平衡:直接合并来自所有模态的数据会对基准性能产生负面影响。我们认为,文本和图像是全模态学习中的核心模态,而语音和视频分别是文本和图像的变体。学会识别文本和图像可确保模型具备基本的跨模态能力,所以我们优先处理这些较难的情况。随后,我们逐步将视频、音频和语音纳入全模态大语言模型的训练中。
-
音频与视觉之间的联系:在全模态学习中,联合学习音频和视觉数据能够通过提供跨不同模态的更全面视角,产生令人惊喜的结果。对于 Ola 模型,我们将视频视为音频与视觉之间的桥梁,因为视频在帧与伴随音频之间包含自然、丰富且高度相关的信息。我们通过优化训练流程和准备有针对性的训练数据来验证这一假设。
在训练流程中,训练阶段 1 为文本 – 图像训练,包括 MLP 对齐、大规模预训练以及监督微调;阶段 2 为图像与视频的持续训练,利用视频数据持续扩展 Ola 的能力;阶段 3 为通过视频连接视觉与音频,我们遵循视觉 MLP 适配器的训练策略,同时通过基本的 ASR 任务初始化音频 MLP。然后,我们将文本与语音理解、文本与音乐理解、音频与视频联合理解以及最重要的文本 – 图像多模态任务混合在一起进行正式训练。在这个阶段,Ola 专注于学习音频识别以及识别视觉与音频之间的关系,训练完成后,便得到一个能够综合理解图像、视频和音频的模型。
图像数据中,在大规模预训练阶段,我们从开源数据和内部数据中收集了约 20M 个文本 – 图像数据对;对于 SFT 数据,我们从 LLaVA-Onevision、Cauldron、Cambrian-1、Mammoth-VL、PixMo 等数据集中混合了约 7.3M 图像训练数据。视频数据中,我们从 LLaVA-Video-178k、VideoChatGPT-Plus、LLaVA-Hound、Cinepile 中收集了 1.9M 个视频对话数据。音频数据中,我们设计了 ASR、音频字幕、音频问答、音乐字幕、音乐问答等文本 – 语音理解任务,总体音频训练数据包含 1.1M 个样本,相关的文本问答表示则从 SALMONN 数据集中收集。
进一步地,我们构造了一种跨模态视频数据的生成方法,旨在揭示视频与音频之间的内在关系,引导全模态大语言模型学习跨模态信息。现有的大多数视频训练数据仅从帧输入进行注释或合成,常常忽略了伴随音频中的宝贵信息。具体而言,我们为跨模态学习开发了两个任务:视频 – 音频问答和视频语音识别。我们使用视觉 – 语言模型基于视频和相应字幕生成问题和答案,并要求模型以字幕输入为重点,同时将视频作为补充信息生成问答。我们为每个视频创建了 3 个问答对,获取了 243k 个跨模态视频 – 音频数据。此外,我们还纳入了包含 83k 个训练数据的原始视频字幕任务,以帮助模型在嘈杂环境中保持其语音识别能力。
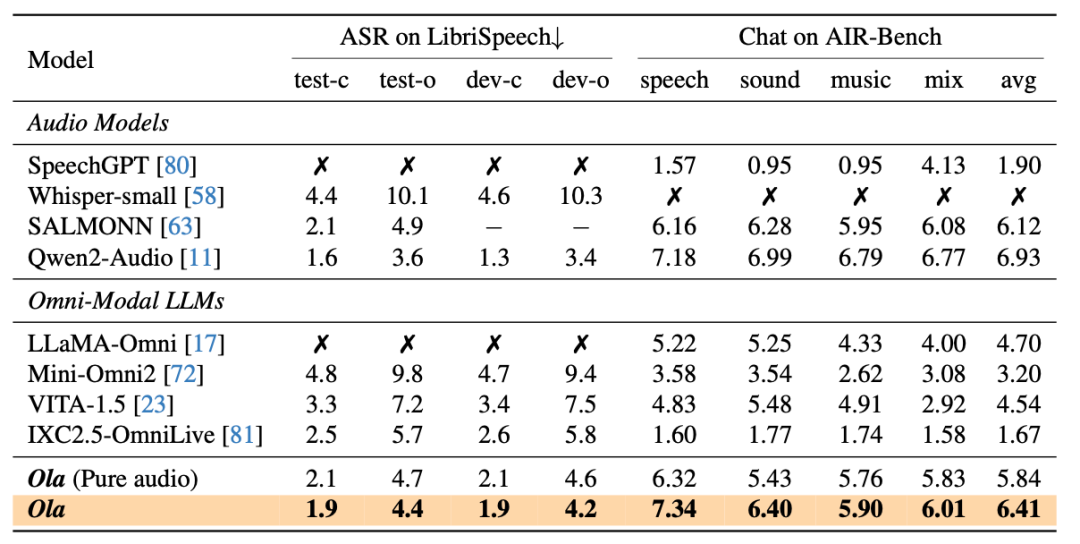
与当前最先进的多模态大语言模型和全模态模型相比,Ola 在主要多模态基准测试中表现出极强的竞争力。具体而言,在图像基准测试中,Ola 在 MMBench-1.1 中达到 84.3%,在 MMStar 上达到 70.8%,在 MMMU 上达到 57.0%,超越了所有参数数量相近的相关多模态大语言模型。在视频基准测试中,Ola 在 VideoMME 上取得了 68.4% 的准确率。在音频基准测试中,Ola 在 LibriSpeech 上的 WER 为 3.1%,在 AIR-Bench 上的平均得分为 6.41,超过了现有的全模态模型。
在音频评测集上的细节结果表明,Ola 相较于现有的全模态模型展现出显著优势,甚至接近专门的音频模型,突显了其强大的通用性。此外,我们可以观察到通过跨模态联合学习,性能仍有稳定提升。尽管视频音频与语音相关数据集之间存在显著的分布差异,但这种提升表明了视频与语音模态之间存在稳固的联系。
通过比较全模态训练前后的结果,我们发现在 VideoMME 上的性能从 63.8% 提升到了 64.4%。此外,在原始视频中加入音频模态后,性能显著提升,在 VideoMME 上的分数从 64.4% 提高到了 68.4%。这些发现表明音频包含有助于提升整体识别性能的有价值信息。
值得注意的是,经过全模态训练并输入音频的 Ola 准确率甚至超过了使用原始文本字幕的结果,总体性能达到 68.4%,而使用原始文本字幕的总体性能为 67.1%。结果表明,在某些基准测试中,音频数据可能包含超出原始文本信息的更多内容。
我们评估了每个阶段中间模型的基本性能,我们可以观察到,从图像、视频到音频的渐进式模态训练能够最大程度地保留先前学到的能力。
我们提出了 Ola,这是一款功能全面且强大的全模态语言模型,在图像、视频和音频理解任务中展现出颇具竞争力的性能。我们基于渐进式模态对齐策略给出的解决方案,为训练全模态模型提供了一种自然、高效且具竞争力的训练策略。通过支持全模态输入和流式解码的架构设计改进,以及高质量跨模态视频数据的准备,进一步拓展了 Ola 的能力。我们期望这项工作能够启发未来对更通用人工智能模型的研究。
(文:机器之心)