
音频模型
OpenAI 发布新型音频模型,听起来比以往任何时候都更像人类

OpenAI发布了两款新的音频模型GPT-4o-transcribe和GPT-4o-mini-transcribe,旨在提升语音转文本的准确性,并引入可操控性文本转语音功能。此举为自然、直观的口语对话迈出了重要一步。
重磅!OpenAI推出语音智能体全家桶:可以实现前所未有的精细化教AI说话

OpenAI发布了三种新的先进音频模型:两款语音转文本模型表现优于Whisper,新TTS模型可教AI说话。为了让开发者构建强大的‘语音智能体’,OpenAI推出了三项重要功能:全新语音转文本模型、文本转语音模型和升级版Agent SDK。
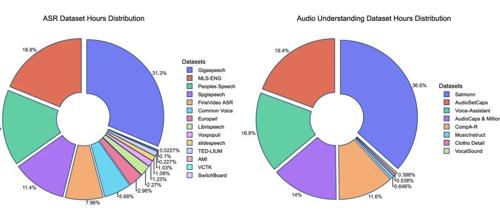
最强全模态模型Ola-7B横扫图像、视频、音频主流榜单,腾讯混元Research&清华&NTU联手打造

多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,