

随着语音助手、会议转写、实时翻译等音频处理应用的普及,市场对轻量级、高性能的音频模型的需求日益增长。传统的音频处理模型往往面临参数庞大、计算资源消耗高、难以实时处理长音频等问题。为了解决这些挑战,LMMs-Lab 团队推出了一款名为 Aero-1-Audio 的轻量级音频模型。该模型不仅在参数规模上实现了高效性,还在多个音频处理任务中表现出色,尤其是在长音频处理和语音识别方面。
一、项目概述
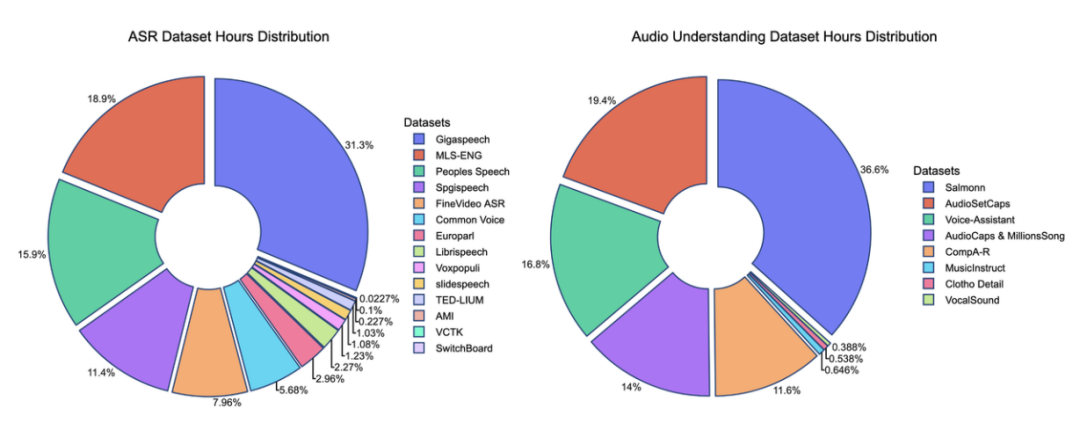
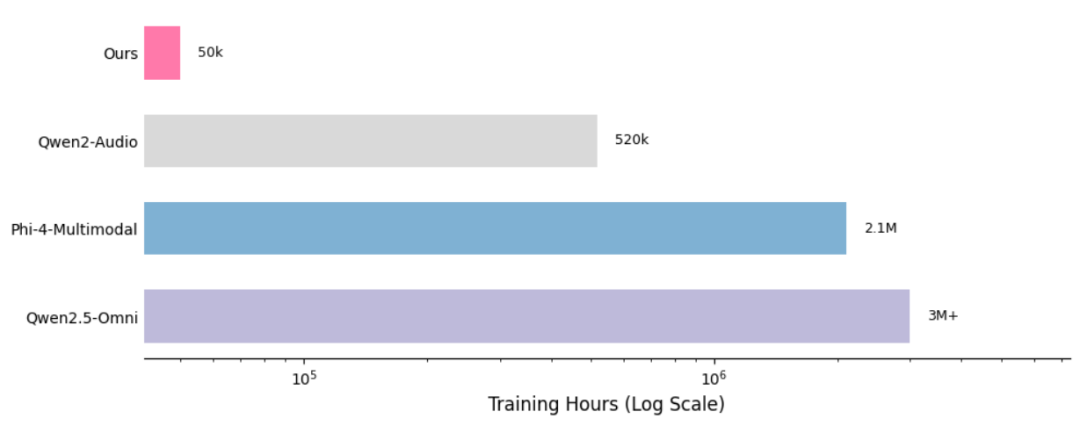
Aero-1-Audio 是由 LMMs-Lab 开发的一款紧凑型音频模型,基于 Qwen-2.5-1.5B 语言模型构建,仅包含 1.5 亿参数。尽管参数规模较小,但该模型在多个音频基准测试中表现出色,甚至超越了许多更大规模的模型,如 Whisper 和 Qwen-2-Audio。Aero-1-Audio 能够处理长达 15 分钟的连续音频输入,无需分割,同时保持上下文连贯性,特别适合长篇语音内容的处理。此外,该模型仅用 16 个 H100 GPU 在一天内完成训练,使用了约 50 亿个 tokens(相当于 5 万小时音频)的高质量过滤数据。
二、技术原理
(一)轻量级设计与高效性能
Aero-1-Audio 仅包含 1.5 亿参数,规模较小,但在多个音频基准测试中表现出色,超越了更大规模的模型,如 Whisper 和 Qwen-2-Audio。这种轻量级设计使得模型在资源受限的环境中也能高效运行。例如,在移动设备或嵌入式系统中,Aero-1-Audio 能够提供快速的语音识别和处理能力,而不会占用过多的内存和计算资源。
(二)高效的训练方法
Aero-1-Audio 的训练数据量相对较小,仅使用了约 50 亿个 tokens(相当于 5 万小时音频),远少于其他大型模型。通过高质量的过滤数据和优化的训练策略,模型在一天内即可完成训练,仅需 16 个 H100 GPU。这种高效的训练方法使得模型能够快速适应新的音频数据和任务需求,降低了开发成本和时间。
(三)动态批处理与序列打包技术
Aero-1-Audio 采用了基于 token 长度的动态批处理策略,通过将样本分组到预定义的 token 长度阈值内,显著提高了计算资源利用率。此外,通过序列打包技术结合 Liger 内核融合,模型的 FLOP 利用率从 0.03 提升至 0.34,进一步提高了训练效率。这种技术优化不仅加快了模型的训练速度,还提高了模型在推理阶段的性能,使其能够更快地处理音频输入。
(四)多任务能力
Aero-1-Audio 在语音识别(ASR)任务中表现出色,在音频分析与理解、语音指令跟随和音频场景理解等多个维度上展现了强大的能力。例如,在 AMI、LibriSpeech 和 SPGISpeech 数据集上,词错误率(WER)最低。此外,该模型还支持多语言处理,能够识别多种语言的语音内容,适用于全球范围的应用场景。
三、核心功能
(一)长音频处理
Aero-1-Audio 能够处理长达 15 分钟的连续音频输入,无需分割,保持上下文连贯性,特别适合长篇语音内容的处理。例如,在会议记录或讲座转录中,模型能够完整地捕捉整个过程的语音内容,生成准确的文本记录。这种能力对于需要长时间音频处理的应用场景尤为重要,如播客转录、法庭记录等。
(二)语音识别(ASR)
Aero-1-Audio 在语音识别任务中表现出色,能够准确地将语音转换为文字,适用于实时转写、会议记录、讲座转录等场景。模型在多个语音识别基准测试中取得了优异的成绩,证明了其在不同语言和口音下的鲁棒性和准确性。例如,在嘈杂环境下的语音识别中,Aero-1-Audio 依然能够保持较高的识别准确率。
(三)复杂音频分析
Aero-1-Audio 支持对语音、音效、音乐等多种音频类型的分析,能够理解音频中的语义和情感,适用于音频内容的分类和分析。例如,在音乐分析中,模型能够识别音乐的风格、节奏和情感表达;在语音分析中,能够检测说话者的情绪状态和意图。这种多维度的音频分析能力为音频内容的智能化处理提供了强大的支持。
(四)指令驱动任务
Aero-1-Audio 支持指令驱动的音频处理任务,例如根据指令提取音频中的特定信息或执行特定操作,适用于智能语音助手等应用。例如,用户可以通过语音指令让模型提取音频中的关键信息,如会议中的决策要点或讲座中的主要观点。这种指令驱动的任务能力使得模型在智能语音助手和自动化处理系统中具有广泛的应用前景。
四、应用场景
(一)语音助手
Aero-1-Audio 可以作为脱网语音控制和对话助手的核心模型,提供快速响应和准确的语音识别。例如,在智能家居系统中,用户可以通过语音指令控制家电设备,Aero-1-Audio 能够实时识别用户的指令并执行相应的操作。这种应用不仅提高了用户的便利性,还增强了语音助手在复杂环境下的性能。
(二)实时转写
在课堂或会议中,Aero-1-Audio 能够捕捉长时间讲解并输出笔记摘要,帮助用户实时记录和整理信息。例如,在国际会议中,模型能够实时将演讲者的语音内容转写为文字,并提供多语言的翻译服务。这种实时转写功能对于提高会议效率和信息传递的准确性具有重要意义。
(三)会议纪要
Aero-1-Audio 可以实时转写会议音频,智能提取标签和关键词,帮助用户快速整理会议纪要。例如,模型能够识别会议中的主要议题、决策和行动计划,并生成结构化的会议纪要。这种智能提取和整理功能大大节省了用户的时间和精力,提高了会议管理的效率。
(四)归档理解
Aero-1-Audio 能够为录音库添加内容标签,支持按语义搜索,提升音频资源的管理和检索效率。例如,在广播电台或播客平台中,模型可以为大量的音频内容生成详细的标签和描述,用户可以通过关键词搜索快速找到所需的音频资源。这种音频归档和检索功能对于音频内容的管理和利用具有重要的价值。
(五)听力模块
Aero-1-Audio 赋予智能代理多轮长语音的理解能力,提升其在复杂对话场景中的表现。例如,在客户服务中心,模型能够实时理解客户的语音咨询,提供准确的回答和解决方案。这种多轮对话理解能力使得智能代理能够更好地服务于用户,提高客户满意度。
五、快速使用
(一)安装依赖
在开始之前,确保已安装Python 和必要的依赖库。可以通过以下命令安装:
pip install transformers@git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-previewpip install librosa
(二)加载模型
from transformers import AutoProcessor, AutoModelForCausalLMimport torchimport librosadef load_audio():return librosa.load(librosa.ex("libri1"), sr=16000)[0]processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)model.eval()
(三)生成转写
messages = [{"role": "user","content": [{"type": "audio_url","audio": "placeholder",},{"type": "text","text": "Please transcribe the audio",}]}]audios = [load_audio()]prompt = processor.apply_chat_template(messages, add_generation_prompt=True)inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt")inputs = {k: v.to("cuda") for k, v in inputs.items()}outputs = model.generate(**inputs, eos_token_id=151645, max_new_tokens=4096)cont = outputs[:, inputs["input_ids"].shape[-1]:]print(processor.batch_decode(cont, skip_special_tokens=True)[0])
通过上述代码,用户可以快速加载模型并生成音频转写。在实际应用中,用户可以根据具体的音频任务修改`messages`中的内容,以生成对应的转写。
(四)在线体验
为了方便用户快速体验Aero-1-Audio 的功能,LMMs-Lab 提供了在线体验平台。用户可以通过以下链接访问在线体验环境:
在线体验地址:https://huggingface.co/spaces/lmms-lab/Aero-1-Audio-Demo
在在线体验平台上,用户可以上传音频文件并实时查看转写结果。平台还提供了多种语言选项和自定义指令功能,方便用户探索模型的不同功能和应用场景。
六、结语
Aero-1-Audio 作为一款轻量级但功能强大的音频模型,在参数效率和性能之间实现了出色的平衡。特别是在长音频处理方面的突出表现,为未来音频模型的发展提供了新的思路。LMMs-Lab 团队的这一工作证明,通过高质量的数据和创新的训练方法,即使是小参数模型也能在复杂的音频任务中取得卓越的性能。对于需要高效音频处理解决方案的研究人员和开发者来说,Aero-1-Audio 是一个值得尝试的开源模型。
七、项目地址
模型下载:https://huggingface.co/lmms-lab/Aero-1-Audio
在线体验:https://huggingface.co/spaces/lmms-lab/Aero-1-Audio-Demo
(文:小兵的AI视界)