

OpenAI发布了一套新的音频模型,旨在为更自然、响应更快的语音代理提供支持。ChatGPT的开发者表示,这是将人工智能从基于文本的交互带入更直观的口语对话的重要一步。
在经历了数月专注于文本代理能力的发布(如Operator和Agents SDK)之后,该公司将赌注押在了语音技术上。正如OpenAI所定位的那样,真正有用的人工智能需要超越文本进行交流。
“为了让代理模型真正有用,人们需要能够与代理模型进行更深层次、更直观的互动,而不仅仅是文本——使用自然口语进行有效沟通,”该公司在公告中解释道。
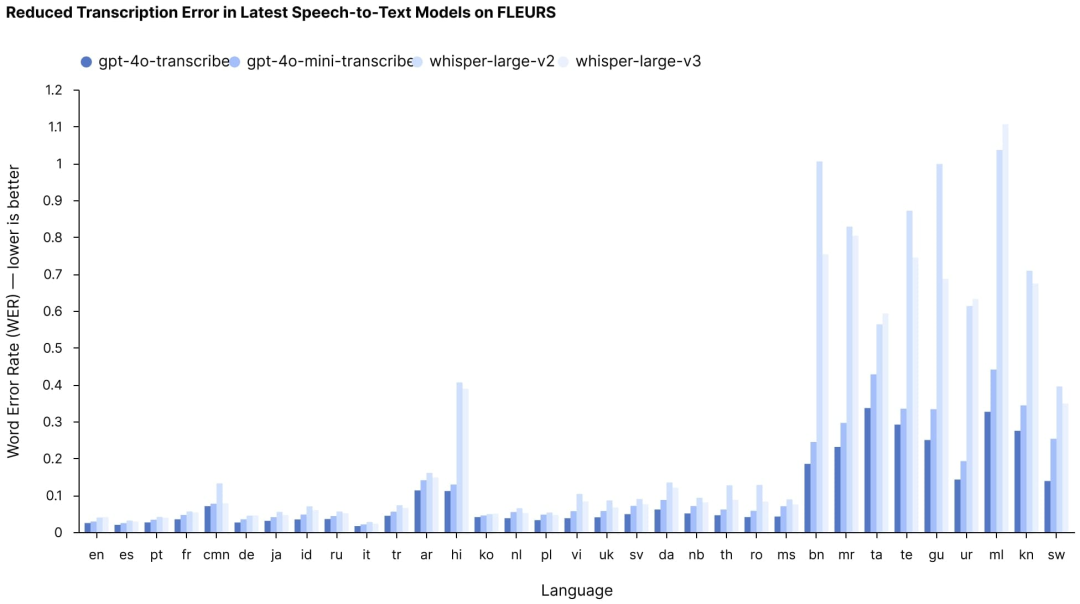
此次发布的核心是两个新的语音转文本模型:GPT-4o-transcribe 和 GPT-4o-mini-transcribe。两者都旨在将口语转换为文本,其准确性显著高于OpenAI之前的Whisper模型,在多种语言中实现了更低的词错误率(WER)。
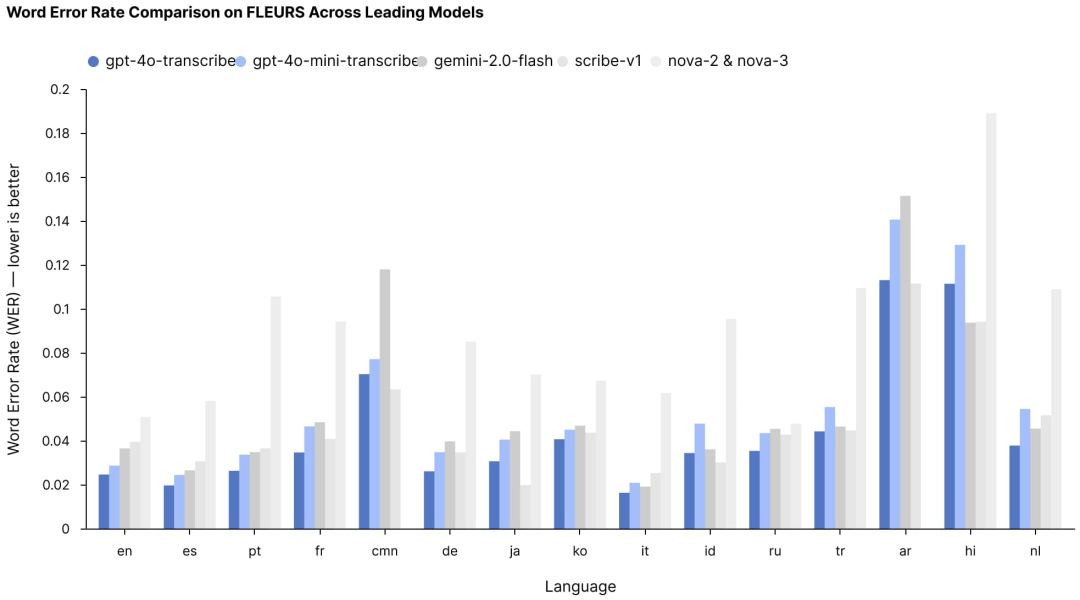
这些改进在理解不同口音、过滤背景噪音和处理不同语速等具有挑战性的场景中尤为显著——这些一直是音频转录技术的痛点。在FLEURS多语言语音基准测试中(测试超过100种语言的转录准确性),这两个新模型不仅超越了OpenAI之前的Whisper产品,还超越了其他公司的竞争解决方案。
对于开发者来说,可能更有趣的是新的GPT-4o-mini-tts文本转语音模型,它引入了OpenAI所称的“可操控性”——即不仅能够指示模型说什么,还能指示它如何说。在一次直播演示中,OpenAI工程师Iaroslav Tverdoklhib展示了开发者如何提供诸如“像疯狂科学家一样说话:高能量、混乱”的指令,从而显著改变同一文本的表达风格。该公司推出了openai.fm()作为一个互动演示网站,开发者可以在这里尝试这些语音变化。
“你可以尽可能具体,”Iaroslav在演示中解释道。“你可以准确地告诉它你想要的节奏和情感。”
定价结构使这些功能相对容易获取:GPT-4o-transcribe每分钟约0.6美分,GPT-4o-mini-transcribe每分钟0.3美分,GPT-4o-mini-tts每分钟1.5美分——尽管性能有所提升,但价格均低于之前的版本。

对于已经构建了基于文本的AI代理的开发者来说,OpenAI使向语音的过渡变得异常简单。对一周前发布的Agents SDK的更新允许开发者通过最少的代码更改将现有的文本代理转换为语音代理。在演示中,OpenAI展示了仅需九行额外代码,就可以将一个基于文本的客户支持代理转换为处理语音查询并以自然语音响应的代理。更新后的SDK处理了将语音转换为文本、通过语言模型处理文本并将响应转换回语音的复杂流程。
这些模型背后的技术创新包括使用专门的音频数据集进行预训练、先进的蒸馏技术将知识从较大模型转移到较小模型,以及通过强化学习提高转录准确性。该公司表示,计划继续改进其音频模型,并探索让开发者在符合其安全标准的前提下为平台带来自定义语音的方法。

语音助手市场也将因这些新模型而迎来新的发展机遇。目前市场上的语音助手虽然功能不断增多,但在理解和生成自然语音方面仍存在不足。OpenAI的新模型能够显著提升语音助手的交互质量。例如,智能家居中的语音助手可以更准确地理解用户的指令,无论是调节灯光亮度、控制家电设备,还是查询天气信息等,都能以更自然、更人性化的方式进行回应。同时,在车载语音助手方面,驾驶员可以通过语音更安全、便捷地操作导航系统、播放音乐等,减少驾驶过程中的分心。
OpenAI的新音频模型无疑将对传统的语音技术公司构成挑战。这些传统公司在语音转录、合成等领域已经占据了一定的市场份额,但OpenAI凭借其强大的技术实力和创新能力,推出了性能更优、价格更低的模型。这可能会促使传统公司进行技术升级和创新,以应对竞争。同时,也会吸引更多的开发者和企业关注OpenAI的音频模型,进一步推动语音技术的发展和应用。
这场语音交互革命才刚刚开始。随着开发者社区的创造性实践,未来两年内,我们或将见证AI从“能听会说”向“善解人意”的质变。正如OpenAI CTO在技术峰会所言:“当机器能以人类的方式沟通时,真正的智能协同时代才会到来。”
(文:AI音频时代)