🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
今天凌晨2点,OpenAI开源了SWELancer,一个新的代码能力测试基准。
该基准用于测试一个模型在一系列现实世界自由职业软件工程任务上理论上能赚多少钱。
这次用的是真实项目的开发任务。任务直接来自Upwork平台,上面有 1,400 多个自由职业者任务,每个任务平均需要自由职业者 21 天以上才能完成。
和以前的测试不太一样。之前都是考单个代码题,现在要处理完整的技术栈,还得考虑各种代码之间的关系。
这些任务加起来价值100万美元。也就是说,如果AI能完全处理好,就等于一个高级工程师的水平了。
这是OpenAI给AI写代码能力定的新标准。GitHub上已经开源,任何人都能用。
不过网友有种感觉:Openai为什么不按照自己原来的时间线发布,这帖可能仅仅因为 grok3 昨天发布了才被发布的 。
。
SWE-Lancer 是端到端测试,就像真实用户那样操作整个系统。不是只测一个小功能,而是测试完整的工作流程。
比如修复用户头像的bug,奖金1000美元。模型要做的不只是让头像能显示,还得确保用户从登录、上传到切换页面,整个过程都顺畅。
端到端测试更贴近真实工作,在评估的过程中,引入了一个用户工具模块。让AI能在本地运行应用,像真人一样操作软件。
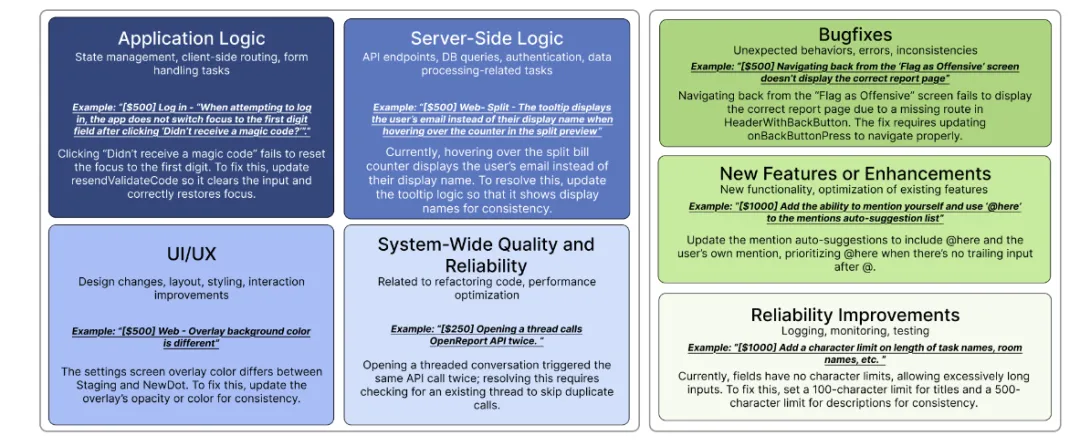
软件里的问题往往不是单独存在的。改一个地方,可能会影响到好几个模块。比如一个简单的bug,背后可能牵扯到数据库、网络等多个环节。
应用逻辑层面:测试状态管理和表单处理。比如修复登录页面焦点切换的问题。
服务器端:验证API接口和数据处理。像是修复用户信息显示的tooltip bug。
UI/UX方面:检查设计变更和交互体验。例如统一不同页面的背景色。
系统质量和可靠性方面:关注性能优化和代码重构。比如解决重复API调用的问题。
拿报销系统来说。模型会实际操作:输入费用、选择日期、提交表单,看看整个流程是不是通顺。
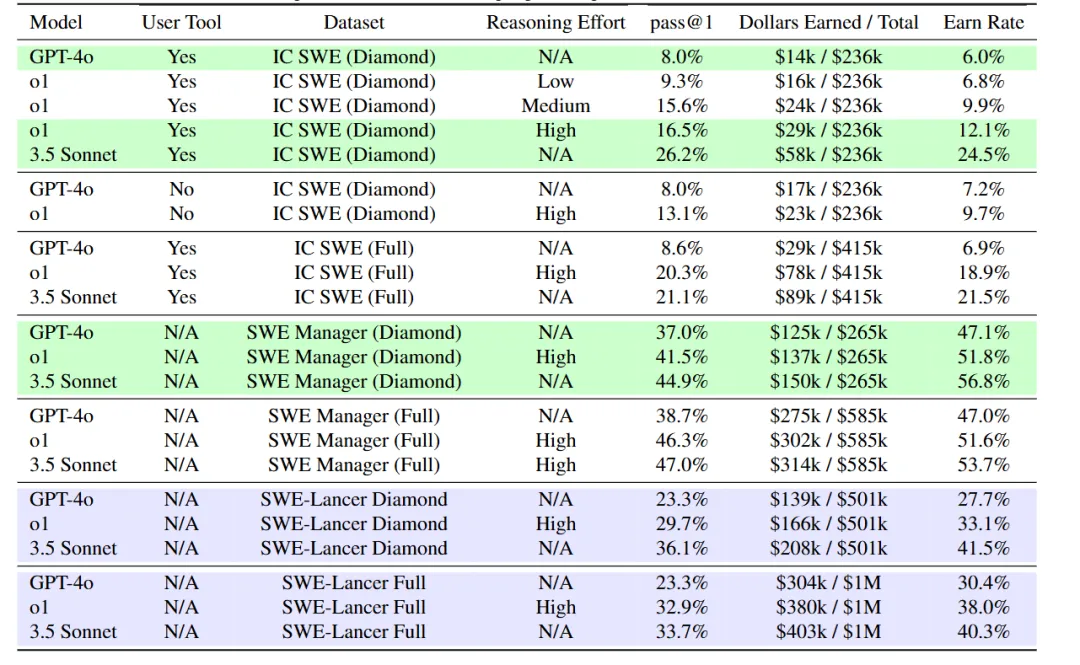
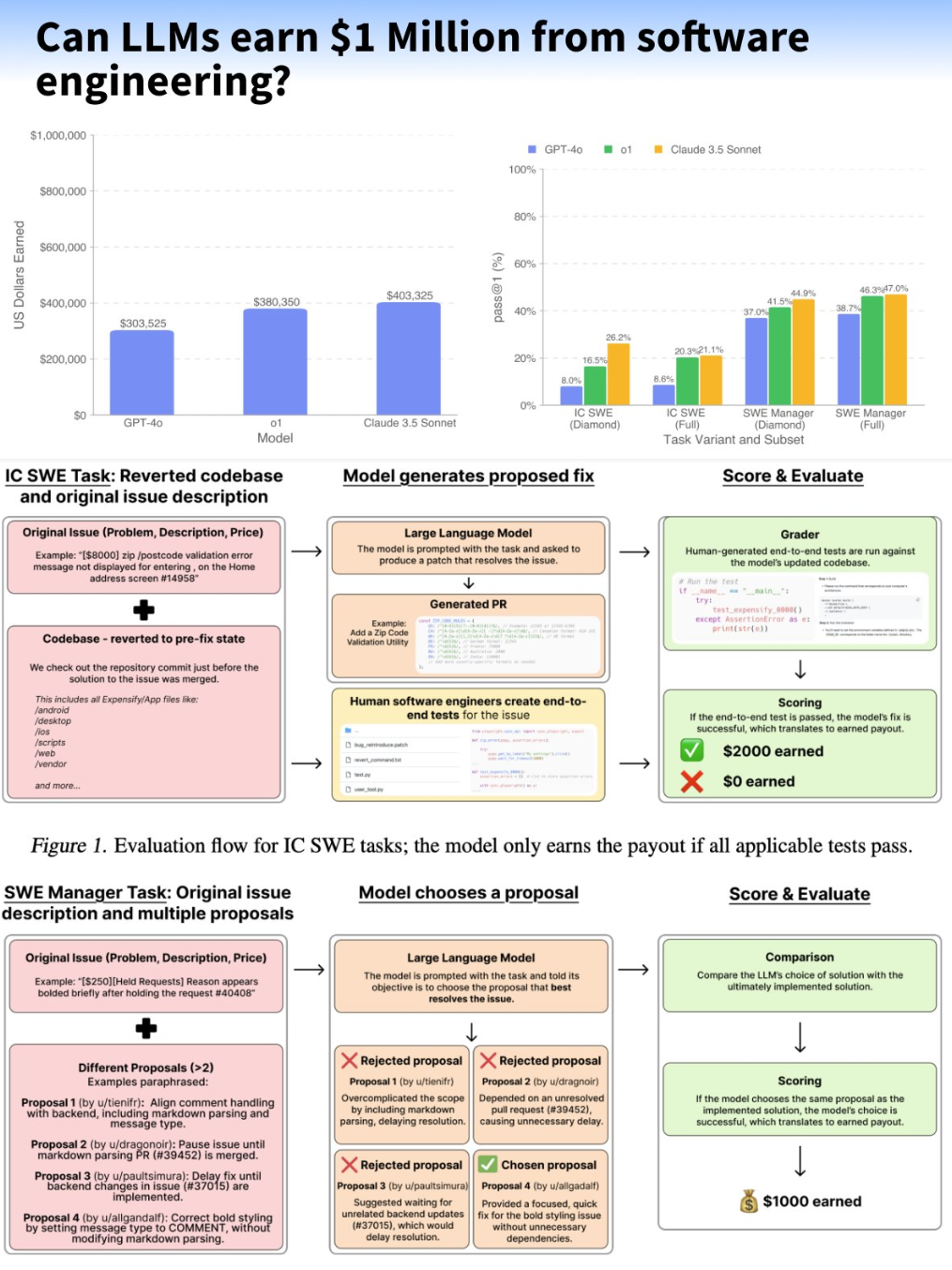
所以现有的大模型能拿到百万年薪吗? Claude 3.5 Sonnet表现最好,但也只能完成26.2%的开发任务。在软件工程管理任务上稍好些, 能做对44.9%。
GPT-4o和o1也试了试。GPT-4o在开发任务上只对了8%, o1对了20.3%。管理任务上, GPT-4o对了37%, o1对了46.3%。
Claude 3.5 Sonnet表现最好,但也只能完成26.2%的开发任务。在软件工程管理任务上稍好些, 能做对44.9%。
GPT-4o和o1也试了试。GPT-4o在开发任务上只对了8%, o1对了20.3%。管理任务上, GPT-4o对了37%, o1对了46.3%。
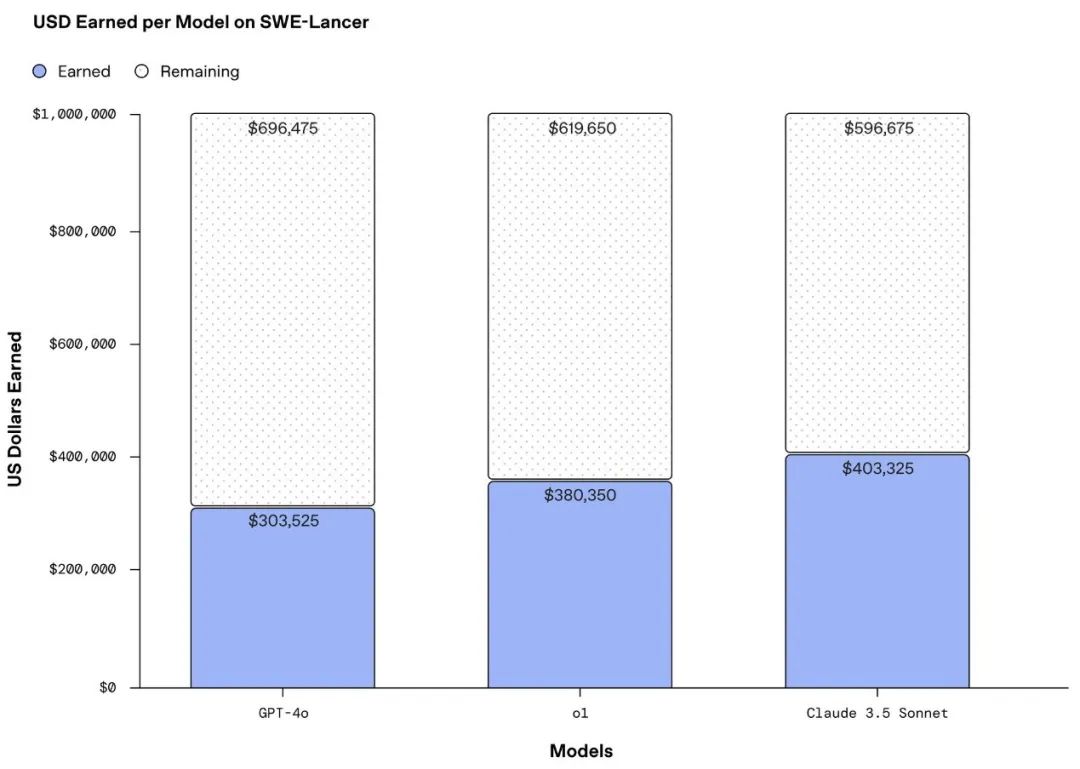
Claude 3.5 Sonnet 在SWE-Lancer测试中拿了40万美元,比GPT-4o 的30万和 o1 的38万都高。
还是厉害呀,Claude 3.5比推理模型o1都强。
有人说是因为Claude更会用工具,能更好地理解代码库和任务要求。
大家都同意一点:在代码方面,Claude 3.5 Sonnet确实很强。
以及。。。他们即将推出下一个模型 …… Claude4。
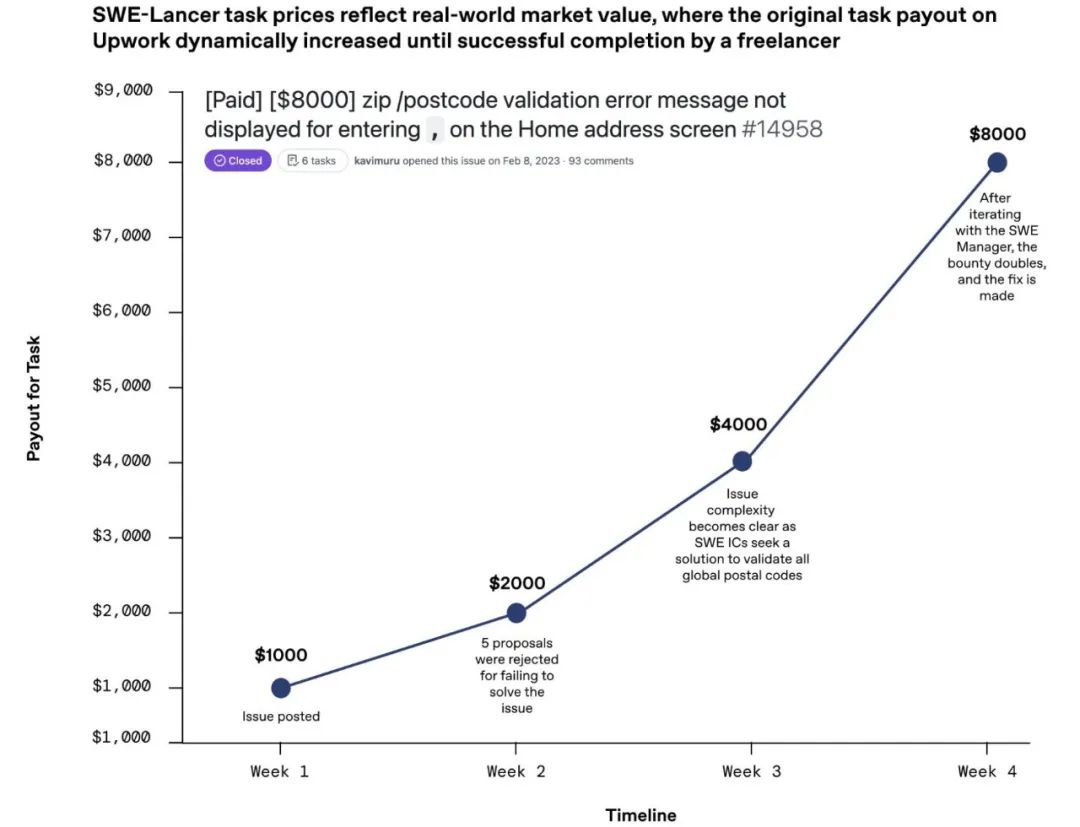
有意思的是,任务难度越大,模型做对的越少。比如那些价值超过1000美元的任务, 正确率普遍不到30%。
UP:SWE-Lancer 任务价格反映现实市场价值。难度更高的任务要求更高的报酬。
简单的基础任务, 模型还能应付。但遇到复杂问题, 和顶尖人类开发者比还差得远。
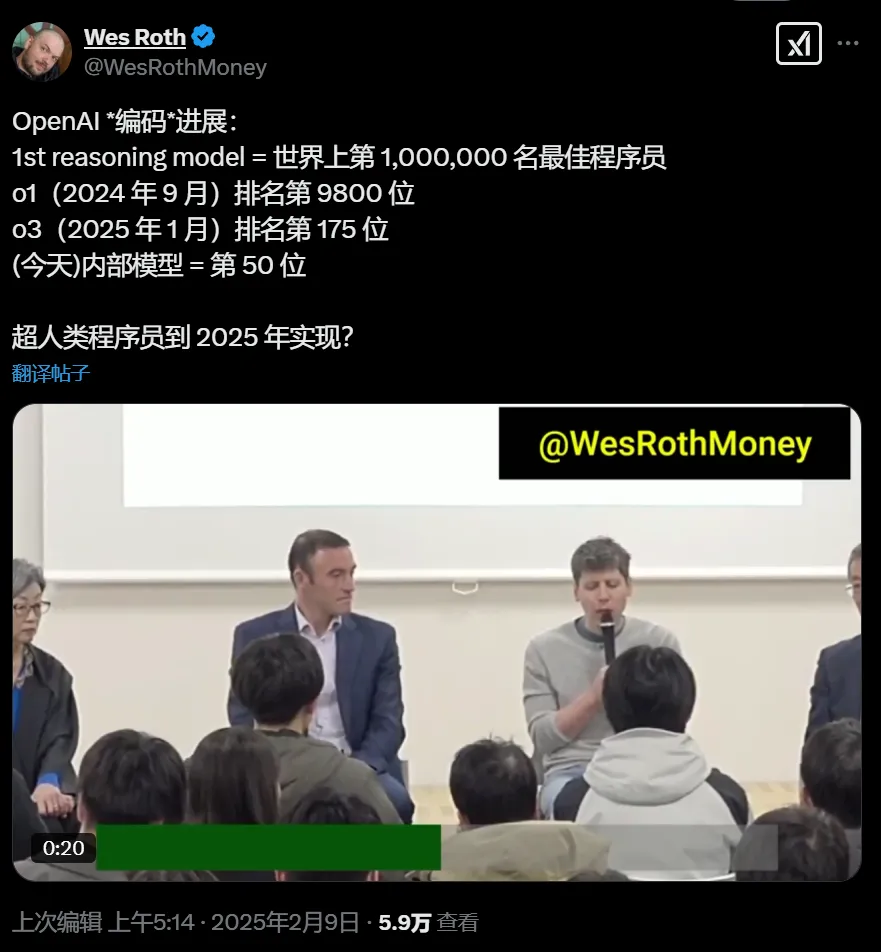
他们怎么不用o3测一测?
还有一个内部排名50的编码模型:
胡猜一下,Openai可能在想 …

自己推出一个新的基准直接登顶,把原来编码老大哥Claude 3.5一炮甩这么远,不就有点王婆卖瓜,自卖自夸的嫌疑了。那不成啊,大家怎么信我。。。哈哈哈。
这会儿先让Claude赢一把,不至于让大家对基准太过嫌疑信心,后面自己更厉害的编程模型再上一波。
当然这只是说说笑。实际上这个基准如前文所述,比较专业客观且有价值。但,Openai在网友心中印象也是比较”好”的:
SWE-Lancer数据集
SWE-Lancer收集了1488个真实项目任务,分两类测试AI。
第一类是独立开发任务,764个,价值41万美元。考验AI能不能写代码、改bug。测试时,AI能看到:
AI要像程序员一样:看问题描述,检查代码,提交修复。测试通过才能拿到奖励。
这回AI要当项目经理,从多个提案中选最佳方案,选对了才能拿到报酬。比如iOS要加个图片粘贴功能,AI得判断哪个实现方案更合适。
看测试流程图:给任务描述和代码,AI提交解决方案,人工评估测试。每个步骤都像真实开发。
以上。
🌟 知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
参考链接:
[1] 开源地址:https://github.com/openai/SWELancer-Benchmark
[2] 新基准介绍:Benchmarkhttps://openai.com/index/swe-lancer/
点这里👇关注我,记得标星哦~
(文:AI进修生)