
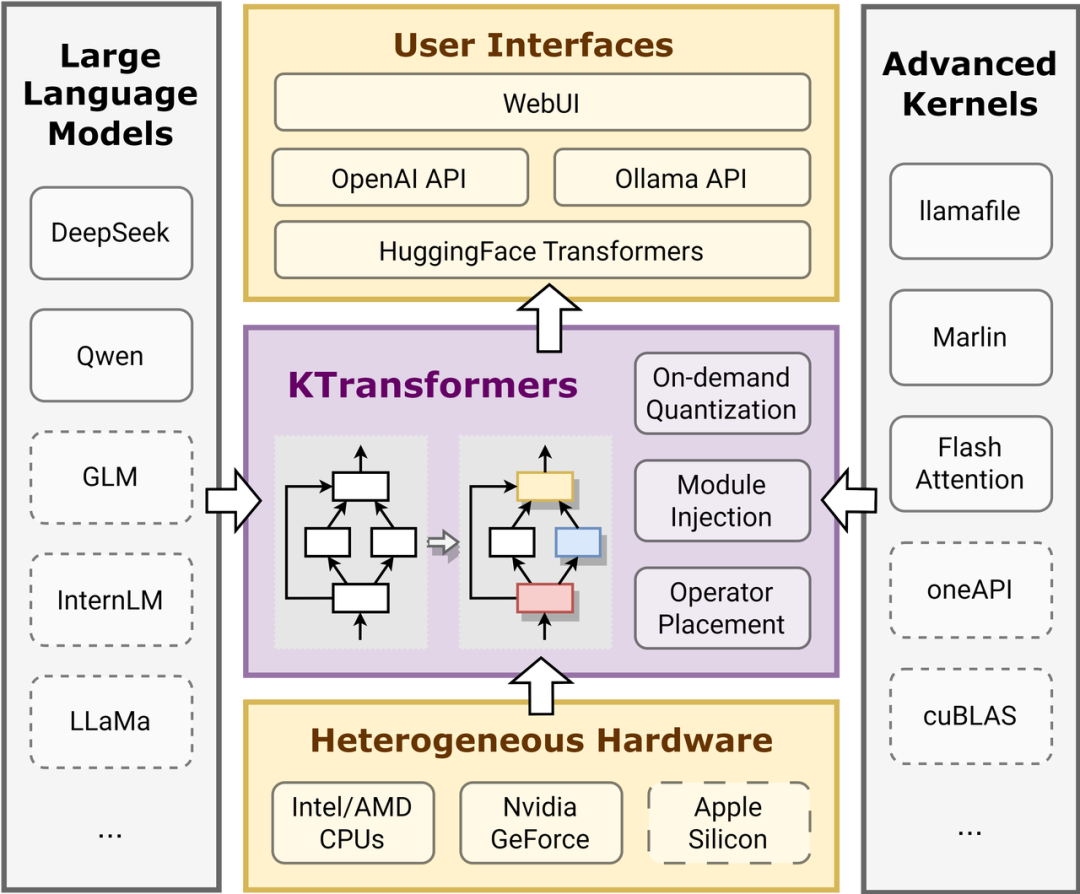
KTransformers是一个旨在提升Transformer体验的灵活框架,结合了先进的内核优化和并行处理策略,尤其注重有限资源下的本地部署优化。
-
多GPU支持与优化:KTransformers支持Deepseek-R1和V3模型在单卡和多卡配置下实现3~28倍的加速,优化了内存和计算资源的使用,适用于24GB显存和382GB系统内存的配置。
-
简化的本地部署与API: 该框架允许用户通过简单的API和Web UI进行模型优化和本地推理,支持OpenAI和Ollama兼容的RESTful接口,且可以在本地实现ChatGPT式的聊天界面。
-
易于定制的优化框架: 用户可以使用YAML文件注入优化模块,轻松替换Transformer模型的标准模块,例如替换为Marlin优化内核,以提高量化模型的推理性能。
-
高级优化技术: 包括MoE(混合专家)和稀疏注意力机制的高效实现,通过Llamafile和Marlin内核优化,在有限的GPU和DRAM配置下也能运行大规模模型。
-
本地运行性能超越GPT-4: KTransformers在本地使用DeepSeek-Coder-V3模型时,能够在21GB显存和136GB DRAM的机器上实现比GPT-4更快的推理速度,特别适用于编程任务的代码生成。
-
支持多平台与操作系统: 目前支持Linux和Windows,提供了Docker镜像及预编译的安装包,确保在不同的操作系统上都能顺利运行。
-
详细教程与快速上手: 官方提供了详细的安装指南和代码示例,帮助用户快速上手并进行本地优化实验,支持从简单的命令行聊天到复杂的多GPU推理任务。
参考文献:
[1] https://github.com/kvcache-ai/ktransformers
[2] https://kvcache-ai.github.io/ktransformers/
(文:NLP工程化)