



共情回复生成(ERG)旨在生成具有情感共鸣的回复,但现有研究局限于单一文本模态,未能充分利用多模态情感表达。
为此,西安电子科技大学与新加坡国立大学以及南洋理工大学团队联合提出多模态共情回复生成(MERG)任务,引入文本、语音和面部视觉信息,并构建大规模基准数据集 AvaMERG,涵盖真实语音与动态头像视频。
为了实现端到端 MERG,作者基于多模态大语言模型(MLLM)设计了 Empatheia 系统,集成多模态编码器、语音与虚拟化身生成器,并进一步引入共情链式推理机制与共情增强微调策略,提升情感理解、多模态一致性及生成质量。
该研究为多模态共情对话奠定基础,推动多模态情感计算发展。目前该工作已被 WWW 2025 录用。

论文链接:
项目链接:

近年来,大型语言模型(LLMs)的发展使机器智能水平达到了前所未有的高度,推动了通用人工智能(AGI)的进步。
然而,真正的 AGI 不仅需要具备与人类相当的认知能力,还应拥有情感理解和共情能力,以更自然地与人类互动。在人机交互中,机器需要能够感知和理解用户的情感与意图,从而做出更具情感共鸣的回应。
这一需求催生了共情回复生成(Empathetic Response Generation, ERG)任务,使机器能够生成富有情感和同理心的回复,以支持情感驱动的对话。
近年来,ERG 研究取得了显著进展,并已在心理咨询、陪伴机器人等领域得到应用。然而,现有的 ERG 研究大多局限于单一文本模态,未能充分利用人类自然表达情感的 多模态特性。
事实上,文本仅能承载部分情感信息,而视觉和语音模态往往能更全面、细腻地传达情绪。例如,面部表情和肢体动作可揭示微妙的情绪变化,语音的语调、音高等特征也能传递丰富的情感信号。
然而,目前的文本 ERG 任务仅能提供文字回复,缺乏人类交流中固有的情感温度和共鸣。同时,从用户角度来看,许多应用场景(如心理咨询、陪伴机器人、虚拟助手等)更倾向于通过语音或动态面部视频直接表达情绪,而非局限于文本输入。
因此,当前 ERG 研究尚未涉及基于虚拟化身的多模态共情回复生成(Multimodal Empathetic Response Generation, MERG),这限制了情感计算在实际场景中的应用潜力。
为填补这一研究空白,作者提出 AvaMERG,一个基于虚拟化身的 MERG 基准数据集,扩展了现有文本 ERG 数据,新增了真实人声语音和动态说话头像视频,并涵盖不同年龄、性别、音色、语调和外貌,以模拟多样化的共情对话场景。
基于 AvaMERG,作者设计了Empatheia,一个端到端多模态大语言模型(Multimodal LLM),集成多模态编码器、语音与虚拟化身生成器,并引入共情链式推理(Chain-of-Empathetic Inference)、内容一致性学习(Content Consistency Learning)和风格对齐机制(Style-aware Alignment and Consistency Learning),确保文本、语音、视频在内容、情感和风格上的一致性。
实验结果表明,Empatheia 在文本和多模态共情回复任务上均优于现有基线模型,推动了 MERG 研究的发展,为未来多模态情感计算奠定了坚实基础。

任务定义
基于虚拟化身的多模态共情回复生成(MERG)是一个全新的任务,旨在扩展传统的文本共情回复生成(ERG),引入多模态输入(包括文本、语音和面部视觉信息),并生成结构化的共情回复和相应的多模态输出。
MERG 不仅能够从多模态输入中生成情感丰富的文本回复,还能根据情感内容生成同步的语音和动态虚拟化身视频,以实现更为自然和真实的情感交流。正如图 1 所示,MERG 不仅能够根据输入的文本生成适当的共情回应,还能确保语音和虚拟化身的情感与文本内容一致,准确传达用户的情感需求。


数据集构建
作者通过增强现有的 ERG 数据集Empathetic Dialogue(ED)来构建 Ava-MERG 数据集,其中包含文本共情回复与对应情感类别。作者通过加入对话中两位参与者的身份信息来丰富数据,包括年龄、性别和语气,以便 MERG 模型能够学习正确的虚拟化身配置,适用于语音和视频。
由于 GPT-4 在上下文理解方面表现出色,且被广泛应用于数据生成,作者也采用 GPT-4 进行标注。作者定义了四个年龄段(儿童、青年、中年、老年)、二元性别(男性、女性)和三种语音语调(强调、温和、柔和)。
作者通过 GPT-4 为 ED 中的每句对话确定上述标签。由于原始 ED 数据存在严重的不平衡问题,例如大多数对话发生在年轻人或中年人之间。作者进一步使用 GPT-4 生成儿童和老年人之间的 ERG 对话,同时检测每段对话的主题,最终构成了 Ava-MERG 数据集的文本部分。
对于对话的多模态部分,作者采用了人工录制和系统合成两种方式得到内容和情感准确的多模态对话。其中虚拟化身涵盖了不同的年龄、性别和语音特征,并包括不同种族(如亚洲人、白人、非洲人、拉美人、印度人)。
为了确保数据集质量,作者招募了一组经过良好训练的标注员,使用三人交叉检查评估每个对话的内容准确性和情感准确性,要求每个标注员检查:1)语音和视频内容是否与文本中的内容匹配;2)语音和视频风格(包括年龄、性别、语气、情感)是否一致。只有在所有三名标注员都同意的情况下,该实例才会被接受。这就形成了最终的Ava-MERG数据集。

Empatheia 模型架构
如图 2 所示,作者为 MERG 任务设计了 Empatheia 系统。整体而言,Empatheia 由三个主要模块组成:多模态编码层、基于 LLM 的核心推理层和多模态生成层。
为了感知多模态对话输入,作者采用了 HuBERT 和 CLIP ViT-L/14@336px 作为语音编码器和虚拟化身视频编码器。本质上,同步文本、语音和动态面部视频的潜在表示应传达一致的语义,这意味着理想情况下,它们的嵌入应该是对齐的。因此,作者通过投影将语音和虚拟化身编码器的表示对齐到LLM的语言语义空间。
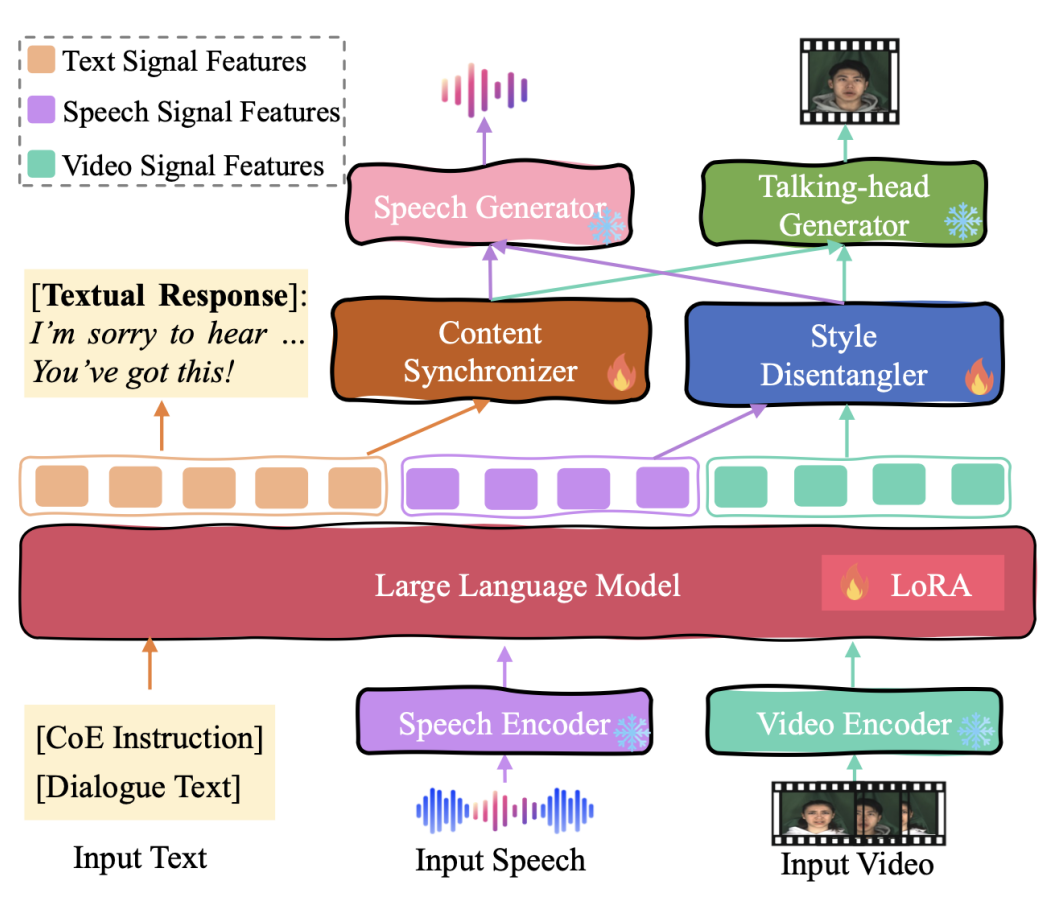
▲ 图2 用于 MERG 的 Empatheia 多模态大模型架构
4.2 核心 LLM 推理器
(1)LLM Backbone
LLM 作为系统的“大脑”,负责理解多模态信号、推理出合适的共情回复,并为多模态生成模块发送信号。鉴于 Vicuna 被广泛作为 MLLM 的基线,并展现了出色的性能,作者选择它作为主干 LLM。
在对输入的多模态对话进行编码后,LLM 被微调以输出以下表示:1)文本 token、2)语音信号 token、3)视频信号 token。语音和视频信号标记包含丰富的情感和风格特征,这些都将用于控制后续模块的生成。
(2)Chain-of-Empathy 推理
共情是一种复杂的人类高级能力,其本质难以被完全诠释,个体作为倾听者在回应前往往会经历多步的思考过程。受思维链(CoT)的启发,作者设计了共情链(CoE)推理机制,逐步引导 LLM 进行渐进式地进行思考,通过层层递进的方式更精准、更可解释地推导出最终的共情回应。
多模态生成器骨干网。在接收到来自 LLM 的信号特征后,骨干语音生成器和动态头像生成器将分别生成非文本内容。为了确保高质量的多模态生成,作者采用了当前最先进的 StyleTTS2 和 DreamTalk。需要注意的是,这些生成器在集成到系统之前已经经过良好的训练。
然而,直接生成语音和动态虚拟化身往往会导致内容和风格的一致性问题。因此,生成过程需要保证两个方面的一致性:
1)内容一致性,语音与动态头像视频应同步,且二者应与文本回复进一步对齐;
2)风格一致性,文本、语音和视觉中的风格,包括情感和个人特征(如年龄、性别、语调、外貌)应保持一致。为了实现自然且准确的 MERG,保持跨模态的一致内容和风格至关重要。

▲ 图3 内容同步器和风格解构器模块
为此,如图 3 所示,作者设计了两个模块:内容同步器和风格解耦器。其中,内容同步器(CS)旨在确保语音和视觉生成器接收到正确的回复内容信息。
如图 3(a)所示,该模块本质上是一个基于 Transformer 的变分自编码器。它主要由两个 Transformer 块组成,CS 将文本特征编码为潜在表示,解码器再从中重建语音内容表征和视觉内容表征。
语音模块和视觉模块中的风格特征(包括情感和身份特征)可能会有细微的差异。因此,风格解耦器(SD)模块旨在从 LLM 输出的语音和视觉信号中解耦风格特征,分别为两个模块提供相应的风格特征。
如图 3(b)所示,与内容同步器(CS)模块类似,风格解耦器也使用 Transformer 模块来解耦语音和视频中的情感与身份特征表示。接下来,作者融合语音/视频的情感表征和身份表征,得到最终的语音/视频风格特征

共情增强的训练策略
有了上述共情模型架构,作者通过一系列训练策略赋予它有效的 MERG 能力。如图 4 所示,主要包括共情链推理学习、内容一致性学习、风格校准和一致性学习和全局 MERG 微调 4 个训练步骤。
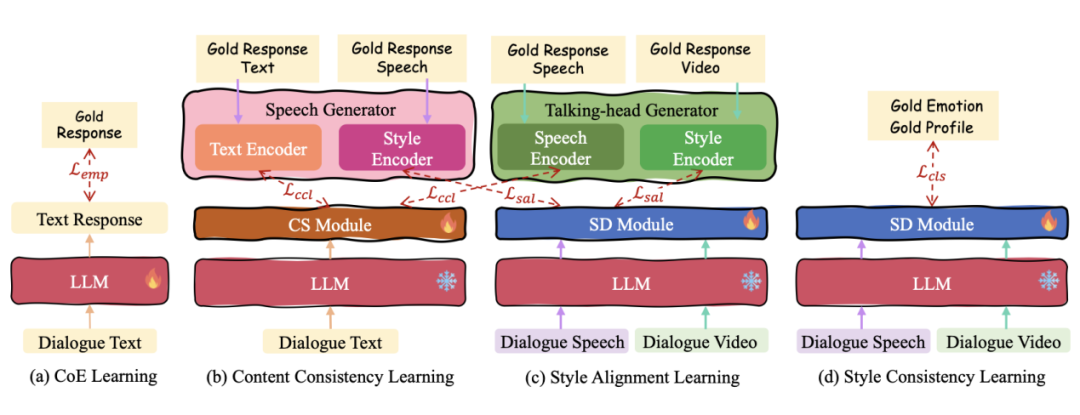
▲ 图4 共情增强的训练策略
(a)共情链推理学习
在第一阶段,为了教会 Empatheia 如何执行共情链式推理(CoE),作者进行监督微调训练。在这次训练中,作者基于 Ava-MERG 训练数据的一个子集标注了一组 CoE 标签。然后,如图 4(a)所示,此训练仅更新用于文本生成的核心 LLM 部分,采用 Lora 技术进行优化。
(b)内容一致性学习
第二阶段的训练目的是鼓励内容同步器(CS)模块输出的内容信号引导多模态生成器生成内容一致的语音和视频。这需要对两边的内容表示进行对齐。
因此,如图 4(b)所示,作者最小化语音生成器中文本编码器的编码输出与 CS 模块输出的音频内容表征之间的欧几里得距离,以及动态头像生成器中音频编码器和 CS 模块输出的视频内容表征之间的距离。在这个阶段,作者保持 LLM 不更新,以防止其遗忘共情回复的能力。
(c)风格校准和一致性学习
在第三阶段,一方面的目标是对齐风格特征,确保多模态生成器准确地解读由 SD 提供的风格信号。如图 4(c)所示,作者最小化语音生成器中风格编码器的风格特征和 SD 输出的语音风格表征之间的欧几里得距离,以及动态头像生成器中风格特征和 SD 输出的视频风格特征之间的距离,从而实现风格一致性学习。
另一方面,为了进一步确保跨模态的风格一致性,作者使用情感和身份标签约束 SD 模块解耦纯粹的情感和个人特征表示。
(d)全局 MERG 微调
前面的训练步骤有效地将 MERG 任务分解为不同能力的子过程。为了提高 MERG 的整体性能,必须进行全面的端到端微调。在这个阶段,作者将所有之前的训练过程整合在一起,并联合微调 LLM、CS 和 SD 模块。
通过联合优化这些组件,模型能够更有效地利用跨模态交互,最终形成一个更加稳健和一致的多模态生成系统,以更好地完成 MERG 任务。

实验分析
首先,作者在表 1 中比较了不同方法在 ERG 任务上的表现,结果发现 Empatheia 模型表现最佳。当移除语音和动态说话头像信息时,性能出现下降(尽管仍然优于基线),这表明多模态信息有助于更好的共情理解。此外,移除 CoE 策略对回复文本的影响最大,反映了 CoE 策略的重要性。
接下来,作者在多模态内容生成中评估了 MERG 的性能,并分别在表 2 和表 3 中展示了语音生成和视频生成的结果。显而易见,Empatheia 模型在所有指标上始终优于管道系统。
作者还分析了模型的消融实验结果。首先,当使用不同的 LLM 作为主干时,发现 Vicuna 相较于 ChatGLM3 和 Flan-T5 获得了更好的性能,因此后续的评估基于 Vicuna。然后,当单独移除 CS 和 SD 模块时,结果出现退化,表明这两个模块的重要性。最后,作者评估了不同学习策略的影响,发现每种策略都会导致不同程度的性能下降,从而验证了它们的有效性。
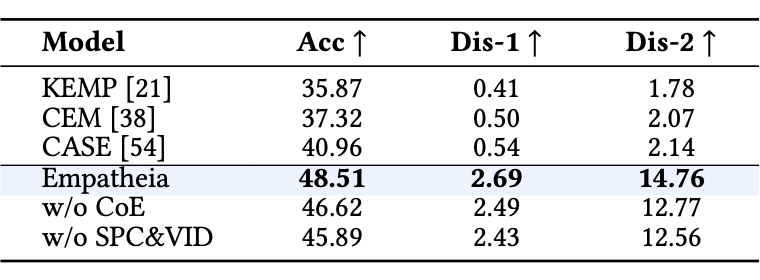
▲ 表1 AvaMERG 数据集共情回复生成测试结果
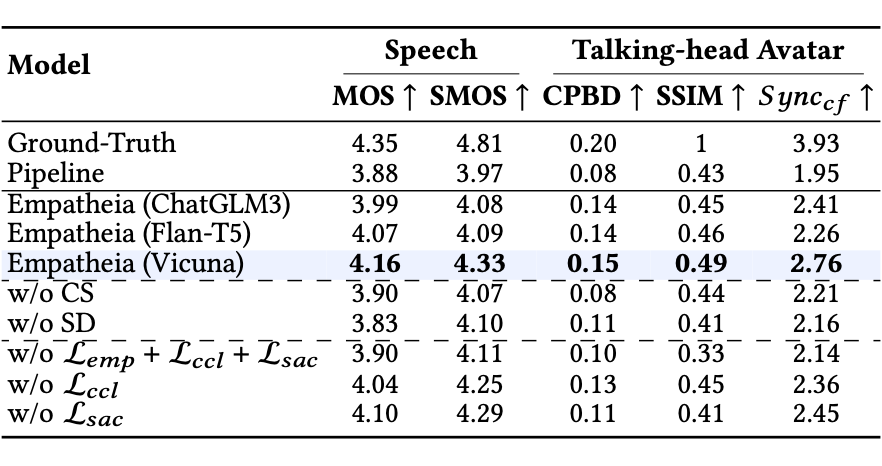
▲ 表2 AvaMERG 数据集音频生成测试结果
由于情感是高级的人类信息,自动评估指标可能不足以全面评估共情能力。因此,作者在表 3 和表 4 中展示了 ERG 和 MERG 任务的人工评估结果。
结果表明,Empatheia 系统显著优于基线方法,且与自动评估一致,验证了多模态信息对共情理解和生成的提升作用。CoE 机制、CS 和 SD 模块,以及精细化的训练策略,对系统性能具有持续的正向影响,证明了它们的重要性和有效性。

▲ 表3 AvaMERG 数据集共情回复生成人工测试结果

▲ 表4 AvaMERG 数据集多模态一致性测试结果
6.2 分析和讨论
图 5 进一步的分析实验显示:Empatheia对悲伤情感最敏感,男性识别优于女性(可能与训练数据性别分布相关),儿童情感识别较弱(因表情动态性强或表达模式差异)。

▲ 图5 不同情感类别、年龄和性别下的结果
图 6 的 t-SNE 可视化验证 SD 模块有效分离情感与个体特征:多模态情感表示中不同情绪类别分离度显著提升,同类别样本聚集紧密,同时成功解耦虚拟化身非情感特征。

▲ 图6 情感和身份特征的 T-SNE 可视化
6.3 案例展示
文章展示了两个案例研究,突出 Empatheia 在多模态共情生成中的优势。第一个案例中,Empatheia 能够准确理解用户的情感并生成具有一致情感表达的回复,而 Pipeline 模型缺乏共情和情感同步机制。
第二个案例中,Empatheia 准确识别了用户的真实情感,并且处理了虚拟形象一致性问题,而 Pipeline 则出现了错误的情感判断和虚拟形象匹配错误。这些案例展示了 Empatheia 在多模态情感理解和生成中的强大能力。

▲ 图7 两个测试案例展示

总结和展望
本文全面探讨了多模态共情回复生成(MERG),为多模态情感分析和共情互动领域的未来发展奠定了基础。根据实践经验,以下是几个未来研究的有前景方向。
-
探索更高效的 MLLMs 和训练方法
未来工作可以探索不同大语言模型(MLLMs)在生成共情回复时的表现,特别是它们在处理多模态输入时的优缺点。尽管我们目前使用了最先进的语音和虚拟形象生成器,但其性能仍有限。因此,提高多模态生成质量以及探索更高效的训练方法(如迁移学习、少样本学习或自监督学习)将是重要方向。
-
开发多维度评估方法
目前,MERG 的多模态生成评估主要依赖人工评估,存在较大不确定性。未来研究应建立多维度的评估方法,结合自动化评估与人工评估,分析生成回复的语义一致性、情感传达准确性以及多模态输入的协同效应。
-
增强模型的上下文理解
未来研究可聚焦于提升模型对对话上下文的理解,尤其是在长对话中保留和利用历史信息。考虑引入更复杂的记忆机制或上下文注意力机制来增强上下文意识。
-
探索跨文化的共情表达
未来工作可以研究如何在不同文化背景下有效生成共情回复,分析文化差异对情感表达和交流风格的影响,并基于这些研究调整模型,以更好地适应不同文化背景的用户。
-
提高数据集的多样性和质量
未来的研究可以集中在收集和构建更大规模、更具多样性的多模态数据集,以涵盖更广泛的情感表达和对话场景,从而进一步提高模型在多样化情感互动场景中的泛化能力和鲁棒性。
(文:PaperWeekly)