
微软发布3.48T token训练数据集+高质量处理管线,覆盖通用、代码、数学、问答等关键领域。在当前 大模型 训练耗尽了越来越多可用数据的状况下,高质量训练数据的重要性日益凸显。
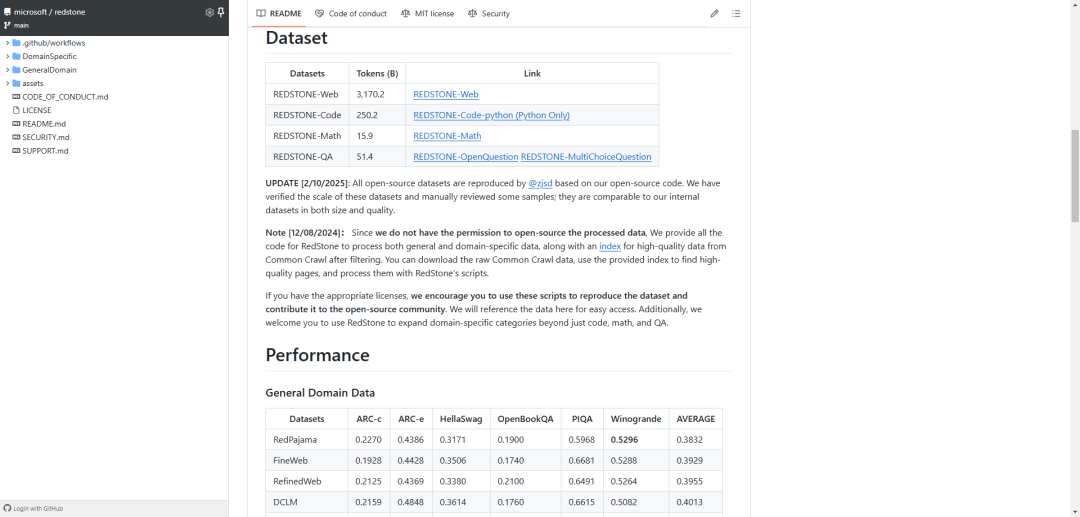
前不久,微软研究院 公布了一项名为 REDSTONE 的开源项目,提供了一套完整的数据处理框架,包括通用领域和特定领域数据的处理脚本,以及经过筛选的高质量 Common Crawl 数据索引。研究团队使用这一框架成功构建了总规模达 3.48 万亿 token 的数据集,涵盖通用知识、代码、数学和问答等多个领域。
与以往的数据处理方法相比,REDSTONE 在数据质量和处理效率上都实现了显著提升。特别是在特定领域数据的获取上,REDSTONE 显著降低了数据集构建的门槛,使得研究人员能够更容易地获取高质量的专业领域数据。从 数据集 的具体构成来看,REDSTONE 主要分为通用领域和特定领域两大类数据。

参考文献:
[1] RedStone: Curating General, Code, Math, and QA Data for Large Language Models:https://arxiv.org/abs/2412.03398
[2] https://huggingface.co/zjsd
[3] 微软发布3.48T token训练数据集+高质量处理管线,覆盖通用、代码、数学、问答等关键领域:https://mp.weixin.qq.com/s/2afNHXmpk5AzAqeenMR0Zg
[4] https://github.com/microsoft/redstone
(文:NLP工程化)