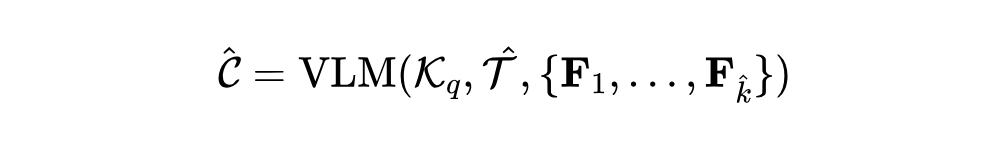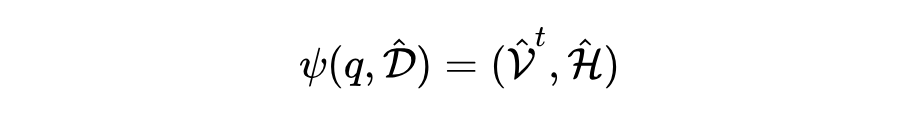https://github.com/HKUDS/VideoRAG 论文地址:
https://arxiv.org/abs/2502.01549 实验室主页:
https://sites.google.com/view/chaoh
检索增强生成(Retrieval-Augmented Generation, RAG)通过推理阶段动态引入与查询相关的外部知识,显著拓展了大语言模型的预训练知识,使其能够与大型私有数据库或最新的信息交互。 然而,当前 RAG 主要应用于文本领域,而视频作为复杂的多模态信息载体,融合视觉、语音和文本等异构模态,在长时间跨度和多视频场景下的有效建模与信息检索仍面临诸多挑战。 在与大规模视频库进行交互时,现有视觉-语言模型(Vision-Language Models, VLMs)受限于基座模型的上下文长度及推理阶段的 GPU 显存,通常依赖采样固定数量的视频帧来简化处理。这种方法不免会破坏视频内容的跨片段连续性并导致关键信息丢失。 此外,传统方法难以为回答提供精确的索引支持,可能引发幻觉问题。为保留跨帧实体关系,部分现有方法采用重量级目标检测与追踪模型保留视频视觉信息,计算成本高且存储大量与未来查询无关的冗余信息,同时难以泛化至检测模型未见过的实体。 针对上述挑战,香港大学黄超教授实验室联合百度提出 VideoRAG ,一种面向超长视频理解的多模态 RAG 框架。 VideoRAG 采用动态知识图谱构建与多模态特征编码,将视频内容压缩为基于多模态上下文的结构化知识表示,从而支持跨视频推理与精准内容检索。在回答生成过程中,VideoRAG 根据查询动态提取原始视频的细粒度内容,避免存储冗余信息,提高推理效率。 为推动相关研究,团队还构建了超长跨视频理解基准数据集 LongerVideos ,涵盖讲座、纪录片、娱乐三类场景,共 164 个视频,总时长 134 小时,为超长视频理解提供了严格的测试环境。 VideoRAG 可在单张 RTX 3090 GPU(24GB)上高效处理长达数百小时的视频内容。实验结果表明,VideoRAG 在超长视频理解任务上具备可溯源的检索能力与全面的回答生成能力,其性能优于传统 RAG 方法(如 NaiveRAG、GraphRAG、LightRAG),以及支持长视频输入的模型(如 LLaMA-VID、VideoAgent)。
此外,在视频问答任务中,VideoRAG 超越了 Google 商业闭源模型 NotebookLM,为超长视频理解提供了新的解决方案。
超长视频理解可视为在无长度和数量约束的视频知识库 1.1 双通道多模态视频知识索引
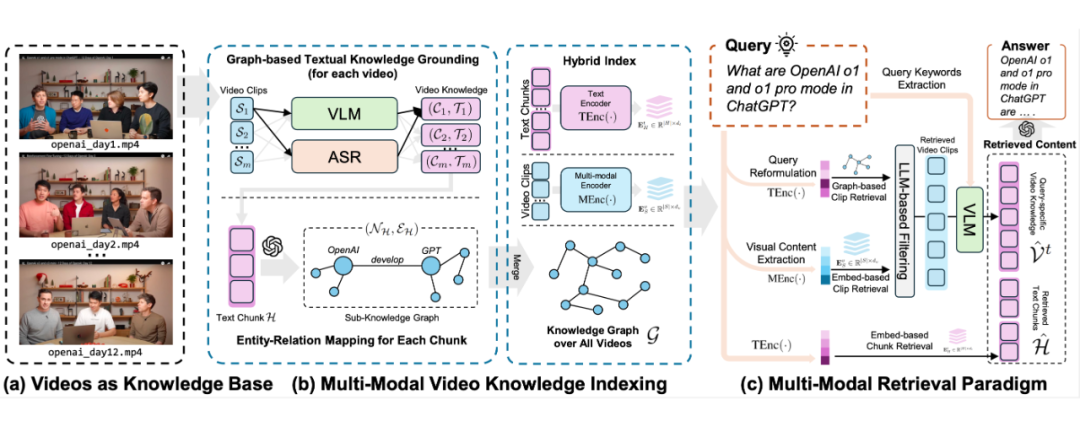
索引阶段的目标是对原始视频中的多模态内容进行知识压缩,并为潜在答案提供视频中可追溯的锚点。索引建立包括两个模块:(1)基于知识图的多模态内容对齐,将多模态信息转换为结构化的文本表示,同时提取实体、事件、场景等语义关系和时序关联;(2)多模态上下文编码,以稠密向量形式存储细粒度跨模态交互特征,增强检索的精准度。 1.1.1 基于知识图的多模态内容对齐
首先,将视频 为保留视频中的语义连贯性和上下文关联性,VideoRAG 进一步利用 LLM 从文本知识库中抽取知识图谱 文本知识 在跨视频知识整合阶段,VideoRAG 通过实体对齐合并等价实体,以保证全局一致性;对于新增视频,则通过 LLM 动态检测新实体与关系,自动扩展知识图结构,同时归纳多来源实体描述。
此外,为提升检索效率,VideoRAG 采用文本编码器对所有文本片段 1.1.2 多模态上下文编码
由于部分视觉细节(如光照变化、复杂物体属性)难以直接转换为文本描述,VideoRAG 进一步引入多模态编码器对所有视频片段 最终,VideoRAG 结合 知识图谱 与 多模态嵌入 ,构建视频知识库的 混合索引结构 1.2 混合多模态检索范式
在检索阶段,VideoRAG 基于构建的双通道索引 在基于知识图谱的文本检索中,VideoRAG 先利用 LLM 将用户查询解析为适合实体匹配的陈述句,并基于相似度匹配知识图谱中的实体以检索相关文本内容。随后,基于 GraphRAG 回溯最符合查询语义的文本子集 在视觉检索中,VideoRAG 解析查询中的视觉元素,生成场景描述,并通过多模态编码器匹配已索引的视觉嵌入,筛选出最接近的 K 个视频片段,构成检索结果 合 。 1.3 内容整合与响应
在检索结果基础上,VideoRAG 通过多模态推理提升响应质量。首先,LLM 从用户查询中提取关键词 随后,VideoRAG 结合文本-视觉联合表示 最终,VideoRAG 采用通用大语言模型(如 GPT-4 或 DeepSeek)基于 query 与检索内容生成准确、可溯源的响应。
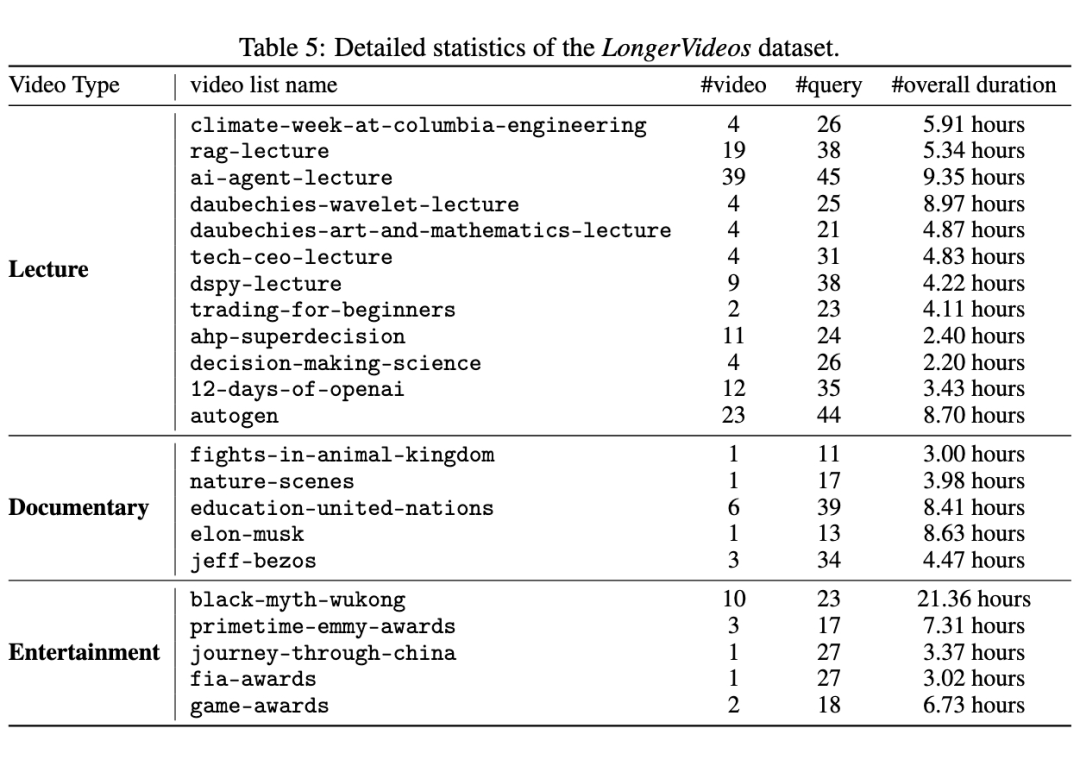
我们在构建的首个超长跨视频理解基准数据集 LongerVideos 上对 VideoRAG 进行了系统测试,实验涵盖了与现有 RAG 方法(NaiveRAG、GraphRAG、LightRAG)、支持超长视频输入的 LVMs(LLaMA-VID、NotebookLM、VideoAgent)的性能对比,以及模型组件的消融实验(-Graph、-Vision)和具体案例分析。 2.1 LongerVideos 基准数据集与评估指标
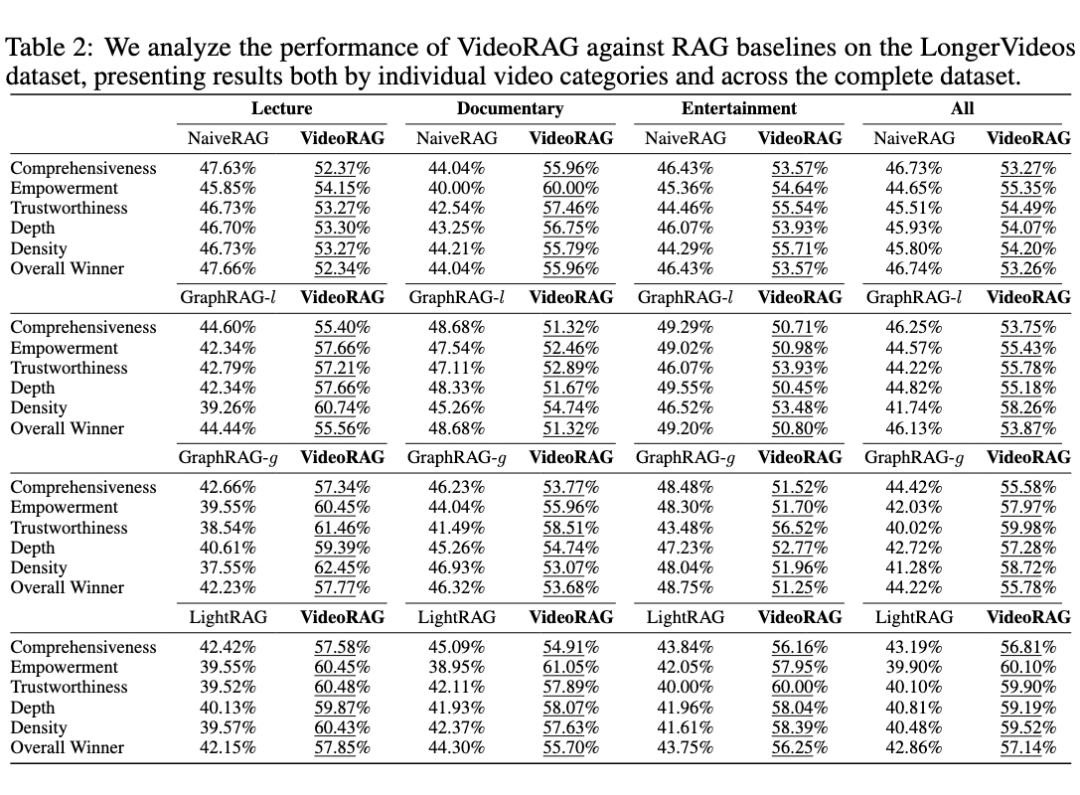
LongerVideos 共包含 164 个视频 ,总时长超过 134 小时 ,涵盖 讲座、纪录片和娱乐 三大类别,支持对模型 跨视频 推理能力的评估。该数据集突破了现有基准数据集中单视频时长普遍不足 1 小时的局限性,为超长视频理解提供了更加严格和全面的测试环境。
我们采用以下两种评估协议来衡量模型的性能:
胜率评估 : 由 GPT-4o-mini 对不同模型的回答进行排序,并提供解释性反馈;
定量评估 : 在胜率比较的基础上,对回答进行评分,以 NaiveRAG 的回答作为标准,并采用 5 分制(1 为最差,5 为最好,NaiveRAG 为 3)进行评估。
我们从五个维度对模型进行分析:
全面性(Comprehensiveness) : 评估回答的广度;
赋能性(Empowerment) : 评估回答如何帮助读者更好地理解和做出判断;
可信度(Trustworthiness) : 评估回答的可靠性,包括细节信息的充分性和与常识的一致性;
深度(Depth) : 评估回答是否包含深入分析和推理;
信息密度(Density) : 衡量回答的信息浓缩程度,避免冗余。
2.2 模型性能对比
我们采用胜率评估方法,对 VideoRAG 与现有 RAG 方法(NaiveRAG、GraphRAG、LightRAG)在不同视频类型和评估维度上的表现进行全面对比。 整体性能优势 :实验结果表明,VideoRAG 在所有维度上均优于现有方法,表明其基于知识图谱与多模态上下文编码的索引机制能够有效捕捉并组织视频中的视觉动态特征和语义信息。此外,VideoRAG 通过结合基于查询的文本语义检索与视觉信息匹配,显著提升了跨视频检索的精确度。
2.2.2 与超长视频理解模型的对比分析
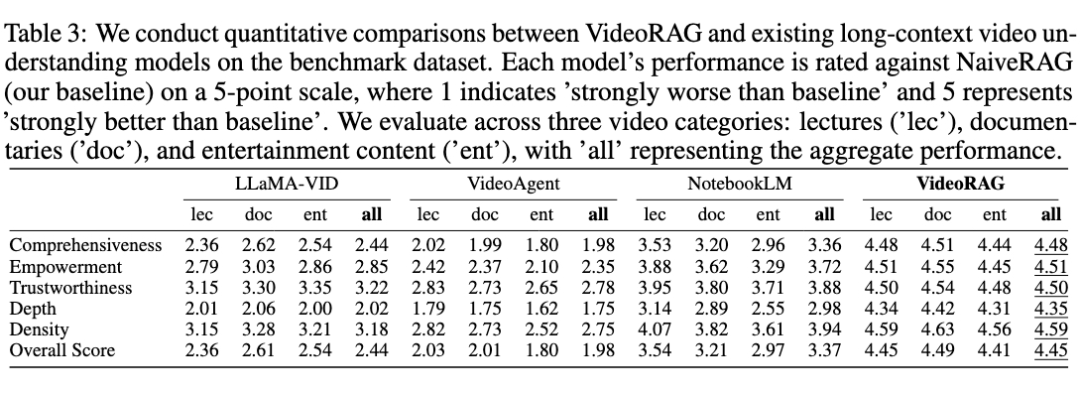
为了进一步评估 VideoRAG 在处理超长视频方面的能力,我们与 LLaMA-VID、NotebookLM(闭源)、VideoAgent 等模型进行了定量评估,并设定 NaiveRAG 作为基准(得分 3 分)。
长视频建模能力的提升 : 通过图增强的多模态索引与检索机制,VideoRAG 有效处理跨视频知识连接和依赖关系,超越了 LLaMA-VID 等模型在处理长视频时的输入上下文限制和计算资源限制;
多模态信息融合的优势 : 相较于仅依赖单一模态的模型(例如 VideoAgent 主要依赖视觉信息,NotebookLM 主要依赖语音转录文本),VideoRAG 在问答过程中通过 query 导向的细粒度建模,减少了索引构建阶段的冗余信息,在确保检索效率的同时,提升了多模态内容的理解能力。
2.3 消融实验
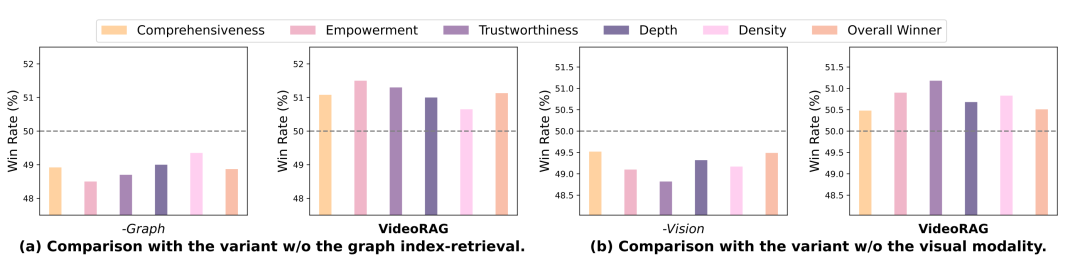
为了分析 VideoRAG 关键设计组件的贡献,我们进行了两种模型变体的消融实验: 变体 1(-Graph) :去除基于图的索引与检索模块; 变体 2(-Vision) :去除多模态编码器中的视觉索引与检索模块。实验结果表明:
去除知识图谱模块(-Graph) : 模型在跨视频信息整合上的能力显著下降,说明知识图谱在刻画实体关系、捕捉跨视频语义关联及提升回答连贯性方面起到了关键作用;
去除视觉模块(-Vision) : 生成的回答在细节丰富度方面明显降低,表明视觉信息对于视频内容理解至关重要,多模态融合有助于提升答案的完整性与细节表达能力。
2.4 案例分析
为评估 VideoRAG 在处理长视频问答任务中的实际表现,我们对查询 “The role of graders in reinforcement fine-tuning” 进行案例分析。该查询来自 OpenAI 2024 年发布的 12 天视频系列(总时长 3.43 小时),目标信息位于第 2 天的视频内容中。
我们展示了 VideoRAG 的回答及对应检索到的视频片段。案例中 VideoRAG 成功检索到第 2 天视频的相关片段(10:35、10:39、11:10),涵盖评分员的基本概念、评分系统原理、得分机制以及部分评分示例,基于检索内容生成了 全面详细且有依据 的回答。 VideoRAG 在全面性和技术深度上明显优于 LightRAG,虽然两者都描述了评分系统的核心概念,但 LightRAG 在解释“评分员评分机制”时缺乏关键技术细节。 这一案例验证了 VideoRAG 在长视频问答任务中的优势,包括精准的跨视频信息检索、语义整合能力以及回答的完整性和深度。同时,VideoRAG 能够提供清晰的参考索引,有效降低模型幻觉的风险,为复杂的长视频理解任务提供了更可靠的解决方案。
总结与未来展望
本文提出了 VideoRAG ,一个面向超长视频的多模态 RAG 框架。通过 知识图谱索引、多模态上下文编码 及 查询感知检索 ,VideoRAG 能高效解析、组织和检索长视频内容。 3.1 核心优势
低计算资源实现超长视频理解 : 突破上下文与计算限制,单张 RTX 3090(24GB)可解析数百小时视频;
高效多模态 RAG 框架 : 结合动态知识图谱与多模态特征编码,构建结构化视频知识索引,支持跨视频推理,并通过查询感知的细粒度检索减少冗余信息存储;
标准化评测基准 : 提出了超长跨视频理解数据集 LongerVideos,推动超长视频理解研究;
优于现有方法 : 在胜率评估和定量评估中均优于现有 RAG、LVMs 以及基于 pipeline 的方法,并在视频问答上超越 Google 商业闭源模型 NotebookLM。
未来工作将进一步优化 实时流媒体解析 和 多语言支持 能力,拓展长视频理解的应用边界。 (文:PaperWeekly)