

-
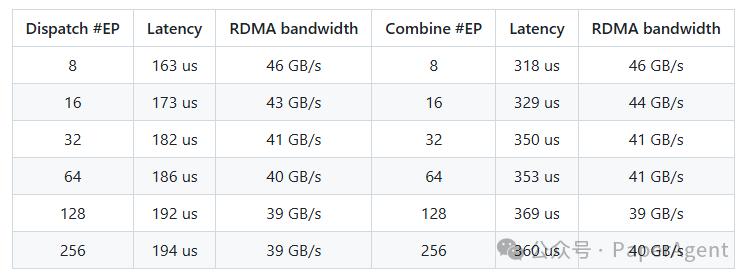
带有NVLink和RDMA转发的正常内核:H800上测试,遵循DeepSeek-V3/R1预训练设置(每批4096 tokens, 7168 hidden, top-4 groups, top-8 experts, FP8 dispatching and BF16 combining)

-
带有纯RDMA的低延迟内核:H800上测试,遵循典型的DeepSeek-V3/R1生产设置(每批128 tokens, 7168 hidden, top-8 experts, FP8 dispatching and BF16 combining)
https://github.com/deepseek-ai/DeepEP
(文:PaperAgent)