
DeepSeek最近爆火,确实是让AI圈更热闹了。
作为AI圈算力供应商的老大哥英伟达终于下场了。
就像我之前说的一样,英伟达会不断地去提供一些新思路、新技术去引领AI发展。
今天英伟达真是整大活儿了。
好消息,是开源的。

DeepSeek R1在Blackwell架构上的优化取得了重大的突破。
这到底意味着什么?
简单来讲,DeepSeek R1的推理性能暴涨25倍,成本降低了20倍。
再通俗点,更快了,更便宜了。
这个优化感觉有点太爽了。。。。
这可不像现在苹果手机一样每一代都是挤牙膏,涨那20%有什么用。
直接就是25倍的性能增长。
通过使用FP4精度,DeepSeek-R1 在MMLU通用智能基准测试中实现了99.8%的FP8精度。
这意味着在保持高精度的同时,DeepSeek-R1 可以以更低的成本和更高的效率运行,
不知道有没有开发者跟我一样的想法,API价格又要大规模降价了,爽爽爽!
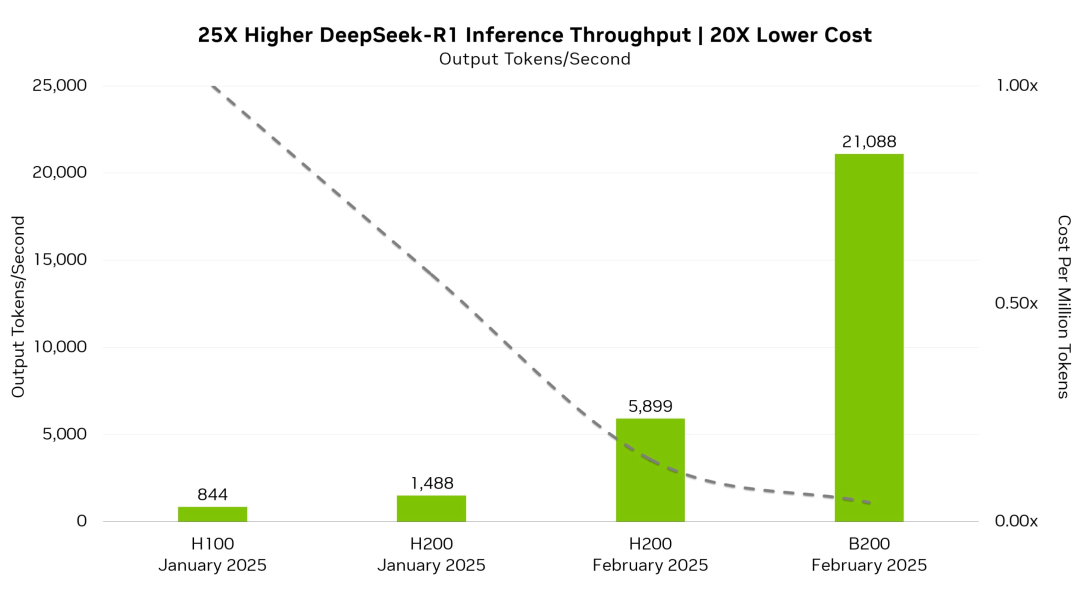
简单来讲下这个柱状图,你就知道提升了多少。
DeepSeek R1 在B200上跑,真是像猛兽一样,每秒21089tokens。
然而H100只有每秒844tokens,差了20多倍。
H100和B200的区别可能有朋友不知道,
-
H100是基于Hopper架构,是当前NVIDIA在数据中心和高性能计算领域的主力产品;
-
B200是基于Blackwell架构,是Hopper架构的后续产品,引入了新的计算精度(如FP4和FP6),并进一步优化了多芯片设计。
总结下技术特点
-
TensorRT优化:NVIDIA的TensorRT技术在DeepSeek-R1的优化中发挥了关键作用。通过TensorRT,DeepSeek-R1能够在Blackwell架构上实现更高的性能和更低的成本。让模型在保持高精度的同时,能够以更快的速度处理数据。
-
FP4精度:DeepSeek-R1使用FP4精度,这比传统的FP8精度更节能、更高效。FP4精度在保持高精度的同时,显著降低了计算成本和能耗。
坏消息,你想用的话,得先拥有8张B200显卡。
不过这并不影响API的价格可能会大幅降低的事实。
最终我们都是受益的。
项目链接
https://huggingface.co/nvidia/DeepSeek-R1-FP4
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

关注「开源AI项目落地」公众号
(文:开源AI项目落地)