


-
数字世界和物理世界: Magma 是第一个多模式 AI Agent的基础模型,旨在处理虚拟和现实环境中的复杂交互! -
多功能功能: Magma作为单一模型不仅具有通用的图像和视频理解能力,而且还能生成目标驱动的视觉计划和动作,使其能够灵活地完成不同的代理任务! -
最先进的性能: Magma 在各种多模式任务上实现了最先进的性能,包括 UI 导航、机器人操作以及通用图像和视频理解,特别是空间理解和推理! -
可扩展的预训练策略: Magma 除了现有的代理数据之外,还被设计为从野外未标记的视频中进行可扩展地学习,从而具有很强的泛化能力,适合现实世界的应用!
-
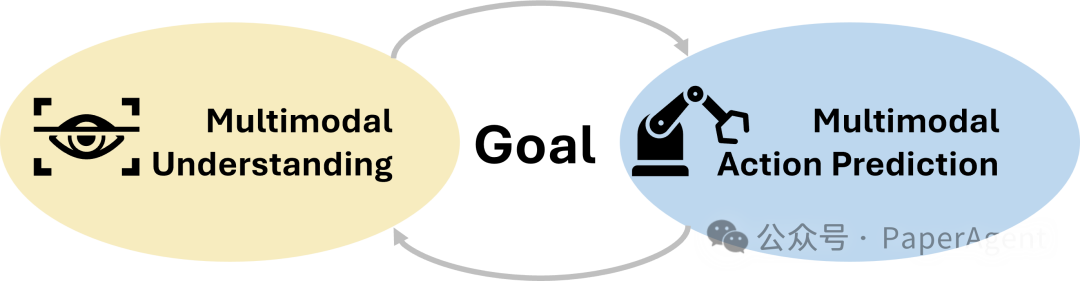
语言和时空智能: Magma应该具有强大的语言和时空智能,以理解图像和视频,根据观察采取行动,并进一步将外部目标转化为行动计划和执行。 -
数字和物理世界: Magma 不应局限于数字世界(例如,网络导航)或物理世界(例如,机器人操纵),而是能够跨两个世界工作,就像人类一样。

-
大规模异构训练数据:在野外整理了大量数据,包括现有的多模态理解数据、UI 导航数据、机器人操作数据以及野外未标记的视频。还提出了一种新的数据收集管道来收集野外未标记的视频,这种管道可扩展且经济高效。为了从原始视频和机器人轨迹中获得有用的动作监督,精心去除了视频中的摄像机运动,然后将运动转换为“动作”监督以供我们的模型训练。这些为模型提供了独特的信号,以学习跨模态连接和长期动作预测和规划。 -
通用预训练目标:文本和动作本质上是不同的,因此会造成巨大的差距,而视觉标记是连续的。提出了一个通用的预训练框架,将这三种模态的训练统一起来,并表明这对于模型学习跨模态连接至关重要。更具体地说,提出了 Set-of-Mark 和 Trace-of-Mark 作为模型预训练的辅助任务,作为不同输出模态之间的桥梁。通过这种方式,在文本和动作模态之间以及图像和动作模态之间建立了良好的一致性。
https://github.com/microsoft/Magmahttps://huggingface.co/microsoft/Magma-8B
(文:PaperAgent)